What Can This Twitter Scraper Extract?
Our Twitter scrapper allows you to extract:
- User profile details – Twitter username, follower count, following count, location, images, and banners.
- Tweets & engagement data – Retweets, tweet lists, replies, hashtags, and search results.
- Content insights – Replies, favorites, retweets, trending topics, and hashtags analytics.
- Media data – Extract images, videos, and media-rich tweets.
Unlike the official Twitter API, which requires registration and imposes limits, our Twitter Scraper provides unrestricted data access. You don’t need an API key, Twitter account, or special permissions to scrape extensive data beyond platform restrictions.
Why Use the Real Data API Twitter Scraper?
Using our scraper Twitter tool, you can:
- Monitor real-time discussions about cities, products, brands, and trending topics.
- Track competitors’ activity and analyze their engagement.
- Observe market trends and public sentiment for business insights.
- Use Twitter data for AI, machine learning, and academic research.
- Spot fake news patterns and track misinformation spread.
With our Twitter Scraper, you can extract, analyze, and utilize social media data at scale for informed decision-making.
How to Use Twitter Scraper?
To learn more about using this Twitter Scraper, check out our stepwise tutorial or watch the video.
Can I Scrape Twitter Data Legally?
Yes, you can extract publicly available data from Twitter. But you must note that you may get private data in your output. GDPR and other regulations worldwide protect personal data, respectively. They don't allow you to extract personal information without genuine reason or prior permission. You can consult your lawyers if you are confused or unsure whether your reason is genuine.
Do You Want More Options to Scrape Twitter Data?
If you wish to extract specific Twitter data quickly, try the targeted Twitter data scraper options below.
- Twitter URL Scraper
- Twitter Image Scraper
- Twitter History Scraper
- Easy Twitter Search Scraper
- Twitter Info Scraper
- Twitter Profile Scraper
- Twitter History Hashtag Scraper
- Twitter Explore Scraper
- Twitter Latest Scraper
- Twitter Explore Scraper
- Twitter Video Scraper
Tips & Tricks
The scraper has the default option to extract using search queries, but you can also try Twitter URLs or Twitter handles. If you plan to use the URL option, check the below allowable URL types.
Logging In Using Cookies
The option to log in using cookies allows you to use the already initialized cookies of the existing user. If you try this option, the scraper will try to avoid the block from the source platform. For example, the scraper will reduce the running speed and introduce a random delay between two actions.
We highly recommend you don't use a private account to run the scraper unless there is no other option. Instead, you can create a new Twitter account so that Twitter won't ban your personal account.
Use Chrome browser extensions like EditThisCookie to log in using existing cookies. Once you install it, open the source platform in your browser, login into Twitter using credentials, and export cookies using a browser extension. It will give you a cookie array to use as an input value login cookie while logging in.
If you try to log out from the Twitter account with the submitted cookies, the scraper will invalidate them, and the scraper will stop its execution.
Check out the below video tutorial to sort it out.
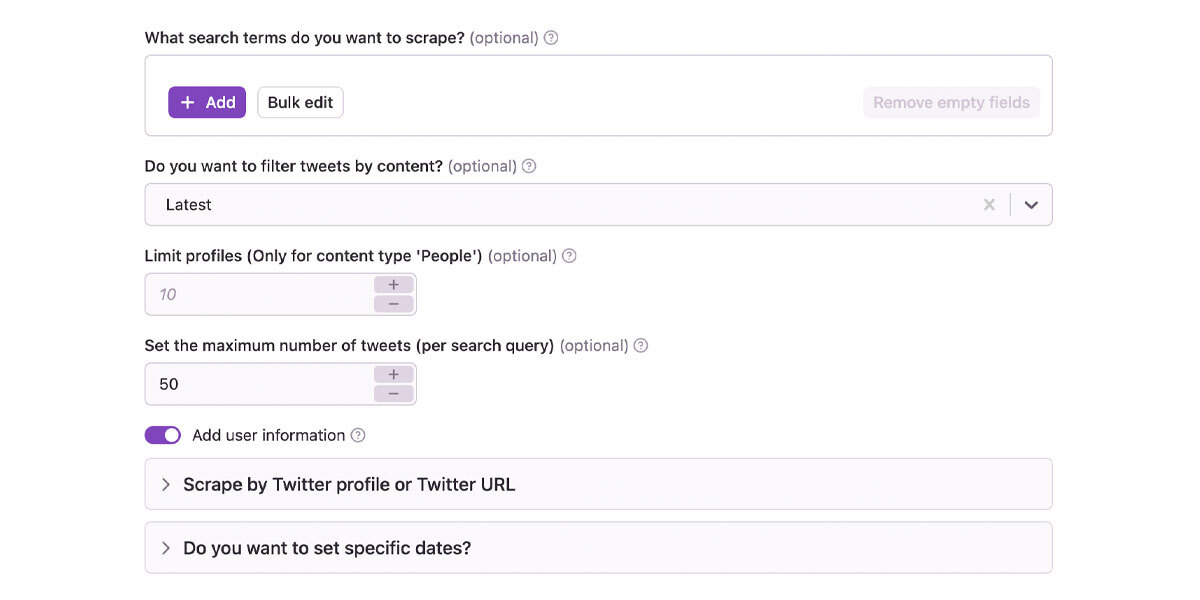
Input Parameters
Here are the input parameters for Twitter Scraper API.
Twitter Data Output
You can export the scraped dataset in multiple digestible formats like CSV, JSON, Excel, or HTML. Every item in the scraped data set contains a different tweet in the following format.
[{
"user": {
"protected": false,
"created_at": "2009-06-02T20:12:29.000Z",
"default_profile_image": false,
"description": "",
"fast_followers_count": 0,
"favourites_count": 19158,
"followers_count": 130769125,
"friends_count": 183,
"has_custom_timelines": true,
"is_translator": false,
"listed_count": 117751,
"location": "",
"media_count": 1435,
"name": "Elon Musk",
"normal_followers_count": 130769125,
"possibly_sensitive": false,
"profile_banner_url": "https://pbs.twimg.com/profile_banners/44196397/1576183471",
"profile_image_url_https": "https://pbs.twimg.com/profile_images/1590968738358079488/IY9Gx6Ok_normal.jpg",
"screen_name": "elonmusk",
"statuses_count": 23422,
"translator_type": "none",
"verified": true,
"withheld_in_countries": [],
"id_str": "44196397"
},
"id": "1633026246937546752",
"conversation_id": "1632363525405392896",
"full_text": "@MarkChangizi Sweden’s steadfastness was incredible!",
"reply_count": 243,
"retweet_count": 170,
"favorite_count": 1828,
"hashtags": [],
"symbols": [],
"user_mentions": [
{
"id_str": "49445813",
"name": "Mark Changizi",
"screen_name": "MarkChangizi"
}
],
"urls": [],
"media": [],
"url": "https://twitter.com/elonmusk/status/1633026246937546752",
"created_at": "2023-03-07T08:46:12.000Z",
"is_quote_tweet": false,
"replying_to_tweet": "https://twitter.com/MarkChangizi/status/1632363525405392896",
"startUrl": "https://twitter.com/elonmusk/with_replies"
},
{
"user": {
"protected": false,
"created_at": "2009-06-02T20:12:29.000Z",
"default_profile_image": false,
"description": "",
"fast_followers_count": 0,
"favourites_count": 19158,
"followers_count": 130769125,
"friends_count": 183,
"has_custom_timelines": true,
"is_translator": false,
"listed_count": 117751,
"location": "",
"media_count": 1435,
"name": "Elon Musk",
"normal_followers_count": 130769125,
"possibly_sensitive": false,
"profile_banner_url": "https://pbs.twimg.com/profile_banners/44196397/1576183471",
"profile_image_url_https": "https://pbs.twimg.com/profile_images/1590968738358079488/IY9Gx6Ok_normal.jpg",
"screen_name": "elonmusk",
"statuses_count": 23422,
"translator_type": "none",
"verified": true,
"withheld_in_countries": [],
"id_str": "44196397"
},
"id": "1633021151197954048",
"conversation_id": "1632930485281120256",
"full_text": "@greg_price11 @Liz_Cheney @AdamKinzinger @RepAdamSchiff Besides misleading the public, they withheld evidence for partisan political reasons that sent people to prison for far more serious crimes than they committed./n/nThat is deeply wrong, legally and morally.",
"reply_count": 727,
"retweet_count": 2458,
"favorite_count": 10780,
"hashtags": [],
"symbols": [],
"user_mentions": [
{
"id_str": "896466491587080194",
"name": "Greg Price",
"screen_name": "greg_price11"
},
{
"id_str": "98471035",
"name": "Liz Cheney",
"screen_name": "Liz_Cheney"
},
{
"id_str": "18004222",
"name": "Adam Kinzinger #fella",
"screen_name": "AdamKinzinger"
},
{
"id_str": "29501253",
"name": "Adam Schiff",
"screen_name": "RepAdamSchiff"
}
],
"urls": [],
"media": [],
"url": "https://twitter.com/elonmusk/status/1633021151197954048",
"created_at": "2023-03-07T08:25:57.000Z",
"is_quote_tweet": false,
"replying_to_tweet": "https://twitter.com/greg_price11/status/1632930485281120256",
"startUrl": "https://twitter.com/elonmusk/with_replies"
}]
...
Search Using Advanced Feature
Use this type of pre-designed search with Advanced Search as a starting link, like https://twitter.com/search?q=cool%20until%3A2021-01-01&src=typed_query
Workaround to Get Maximum Tweets Limit
Twitter returns only 3200 tweet posts per search or profile by default. If you require more tweets than the maximum limit, you can split your starting links using time slices as the below URL samples.
https://twitter.com/search?q=(from%3Aelonmusk)%20since%3A2020-03-01%20until%3A2020-04-01&src=typed_query&f=livehttps://twitter.com/search?q=(from%3Aelonmusk)%20since%3A2020-02-01%20until%3A2020-03-01&src=typed_query&f=livehttps://twitter.com/search?q=(from%3Aelonmusk)%20since%3A2020-01-01%20until%3A2020-02-01&src=typed_query&f=live
Each link is from the same account - Elon Musk, but we separated them by a 30-day monthly timeframe, like January > February > March 2020. You can create it using the advanced search option on Twitter. https://twitter.com/search If you want, you can use larger time intervals for a few accounts that don't post regularly.
Other restrictions contain-
- You can cap live tweets by max one day in the past.
- Flying can cap most search results at about hundred and fifty tweets like Top, Pictures, and Videos.
Extend Output Function
This output parameter function allows you to change your dataset output shape, split data arrays into different items, or categorize the output.
async ({ data, item, request }) => {
item.user = undefined;
delete item.user;
const raw = data.tweets[item['#sort_index']];
item.source = raw.source;
if (request.userData.search) {
item.search = request.userData.search;
item.searchUrl = request.loadedUrl;
}
return item;
}
Item filtering:
async ({ item }) => {
if (!item.full_text.includes('lovely')) {
return null;
}
return item;
}
Separating into multiple data items and changing the entire result:
async ({ item }) => {
return item.hashtags.map((hashtag) => {
return { hashtag: `#${hashtag}` };
});
}
Extend Scraper Function
This factor permits you to extend scraper working and can simplify extending the default scraper function without owning a custom version. For instance, you can contain a trending topic search for every page visit.
async ({ page, request, addSearch, addProfile, addThread, customData }) => {
await page.waitForSelector('[aria-label="Timeline: Trending now"] [data-testid="trend"]');
const trending = await page.evaluate(() => {
const trendingEls = $('[aria-label="Timeline: Trending now"] [data-testid="trend"]');
return trendingEls.map((_, el) => {
return {
term: $(el).find('> div > div:nth-child(2)').text().trim(),
profiles: $(el).find('> div > div:nth-child(3) [role="link"]').map((_, el) => $(el).text()).get()
}
}).get();
});
for (const { search, profiles } of trending) {
await addSearch(search);
for (const profile of profiles) {
await addProfile(profile);
}
}
await addThread("1351044768030142464");
}
extendScraperFunction contains additional data variables.
async ({ label, response, url }) => {
if (label === 'response' && response) {
if (url.includes('live_pipeline')) {
const blob = await (await response.blob()).text();
}
} else if (label === 'before') {
} else if (label === 'after') {
}
}
Twitter Scraper with Real Data API Integrations
Lastly, using Real Data API Integrations, you can connect Twitter Scraper with almost any web application or cloud service. You can connect with Google Drive, Google Sheets, Airbyte, Make, Slack, GitHub, Zapier, etc. Further, you can use Webhooks to carry out an activity once an event occurs, like an alert when Twitter Scraper completes its execution.
Using Twitter Scraper with Real Data API Platform
The Real Data API platform gives you programmatic permission to use scrapers. We have organized the Twitter Scraper API around RESTful HTTP endpoints to allow you to schedule, manage, and run Real Data API Scrapers. The actor also lets you track actor performance, create and update versions, access datasets, retrieve results, and more.
To use the scraper using Python, try our client PyPl package, and to use it using Node.js, try our client NPM package.
Check out the API tab for code examples or explore Real Data API reference documents for details.














