

Introduction
Establishing an enterprise data extraction infrastructure may seem challenging, but it doesn't have to be. It begins with a clear understanding of how to build a scalable enterprise data extraction infrastructure tailored to your business needs. Web scraping projects contain various elements, and finding the correct procedure that aligns with your custom requirements sustainably is critical. Many organizations need help locating developers with the necessary expertise, forecasting budgets, or finding solutions that precisely meet their needs.
We've outlined critical steps for building an adequate infrastructure to clarify the process. Whether your goal is data extraction for price intelligence, lead generation, market research, and other objectives, this guide is designed to assist you. It emphasizes the significance of crawl efficiency, high-performing configurations, scalable architecture, auto data-quality assurance, and robust infrastructure.
For Real Data API, the emphasis remains on crafting a scalable architecture to ensure extracting the most valuable data. Real Data API enhances this process, offering a solution that streamlines web scraping projects, simplifying the challenges of finding the right expertise and budget forecasting. By leveraging Real Data API, businesses can optimize their data extraction efforts for various purposes, such as lead generation, price intelligence, market research, and more. This comprehensive guide ensures that your web scraping project elements are well-crafted and aligned with a scalable architecture, ultimately maximizing the value of the extracted data.
Optimizing Decision-Making: Crafting a Scalable Architecture for Web Scraping
At the core of any large-scale web scraping initiative is the development of a scalable architecture. An indispensable initial step involves creating a well-structured index page that serves as a hub for links to all other pages earmarked for extraction. While crafting effective index pages can be challenging, leveraging an enterprise data extraction tool streamlines this process, making it quick and straightforward.
Invariably, some form of an index page contains links to numerous other pages requiring extraction. In e-commerce, these often manifest as category "shelf" pages, acting as gateways to many product pages. A blog feed typically serves as the index for blog articles, linking to individual blog posts. A strategic separation of discovery and extraction spiders is paramount to scale enterprise data extraction.
In enterprise e-commerce data extraction, this entails developing distinct spiders. The first, the product discovery spider, is tasked with identifying and storing URLs of products within the target category. The second spider is dedicated to scraping the desired data from the identified product pages. This bifurcated approach divides the core processes of web scraping—crawling and scraping—and allows for resource allocation optimization. It allows channeling more resources toward one process over the other, effectively circumventing potential bottlenecks.
By adopting this strategic approach, organizations can enhance the efficiency of their web scraping projects, ensuring a scalable architecture that empowers informed and strategic decision-making. This methodology proves particularly valuable in industries like e-commerce, where the volume of data extraction can be substantial and necessitates a well-orchestrated and scalable framework.
Optimizing Enterprise Data Extraction: Configuring for High Performance
When constructing a robust enterprise data extraction infrastructure, spider design, and crawling efficiency are paramount. Beyond establishing a scalable architecture in the project planning phase, the subsequent critical foundation involves configuring hardware and spiders for high performance when operating at scale.
In large-scale enterprise data extraction projects, speed emerges as a primary concern. Applications, particularly in sectors like e-commerce, demand that enterprise-scale spiders complete comprehensive scrapes within defined time frames. For instance, rapid extraction of competitors' entire product catalogs is essential for timely pricing adjustments in price intelligence.
Critical steps in the configuration process include:
- Developing a profound understanding of web scraping software.
- Eliminating unnecessary processes to optimize team efforts.
- Ensuring the appropriateness of hardware and crawling efficiency for large-scale scraping.
- Fine-tuning hardware and spiders for maximum crawling speed.
- Prioritizing speed during deployment configurations.
The imperative for speed introduces substantial challenges in developing an enterprise-level web scraping infrastructure. Teams must adeptly extract maximum speed from their hardware, eliminating inefficiencies in fractions of a second. This necessitates a comprehensive understanding of the web scraper software market and frameworks in use, empowering enterprise web scraping teams to meet the demands of high-performance data extraction at scale.
Enhancing Crawl Efficiency for Swift and Reliable Data Extraction
In scaling your enterprise data extraction project, prioritizing crawl efficiency and robustness is essential. The primary objective is to extract precise data with minimal requests and the utmost reliability. Unnecessary requests or inefficient data extraction processes can impede the pace of crawling a website, hindering overall project efficiency.
Navigating through potentially hundreds of websites with intricate or messy code presents a challenge, compounded by the dynamic nature of constantly evolving websites. The key to success lies in streamlining the data extraction process to ensure quick and reliable results. By optimizing crawl efficiency, businesses can achieve the dual goals of expeditious data retrieval and increased reliability, laying a foundation for a successful and scalable enterprise data extraction initiative.

Anticipate changes in your target website approximately every 2-3 months, impacting spider performance. Instead of maintaining multiple spiders for various layouts, adopt a best practice: employ a single, highly configurable product extraction spider capable of handling diverse rules and schemes across different page layouts. The more adaptable your spiders are, the more effectively they navigate evolving website structures, ensuring sustained data extraction coverage and quality despite frequent modifications. This streamlined approach enhances resilience, making it a prudent strategy for maintaining the efficacy of your data extraction processes in the dynamic online landscape.
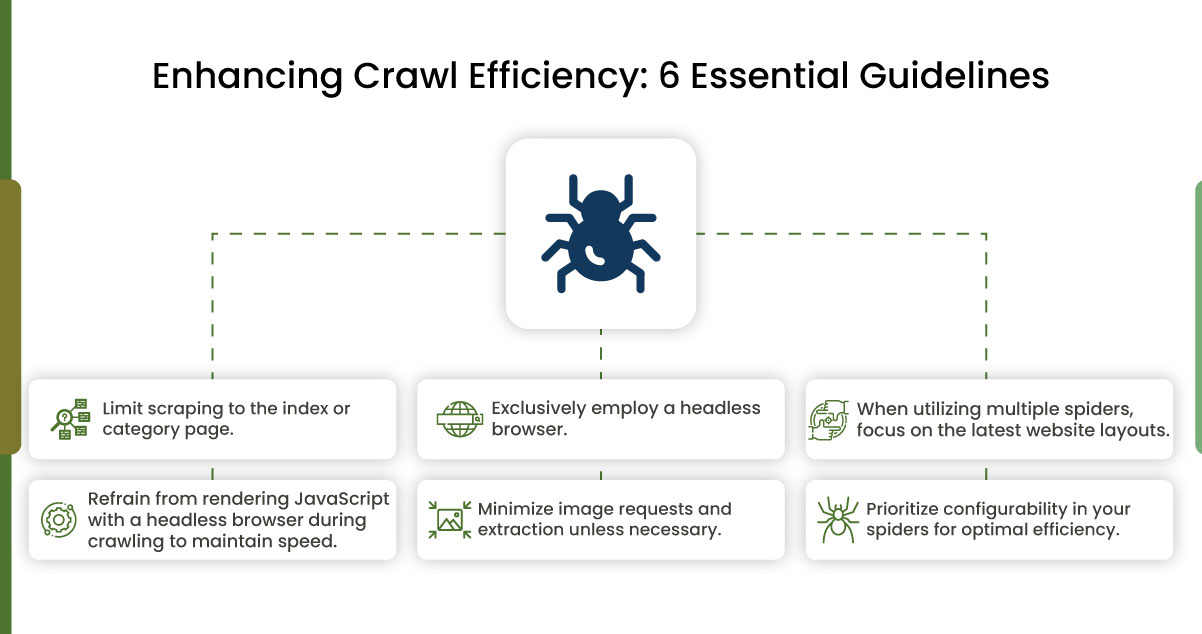
Optimizing Enterprise Data Extraction: Strategies for Efficient Web Crawling
In enterprise data extraction, prioritizing crawl efficiency is paramount for seamless operations. Utilizing a headless browser, such as Splash or Puppeteer, is crucial, especially when deploying serverless functions, and rendering JavaScript should be considered a last resort due to its resource-intensive nature. Avoid requesting or extracting images unless necessary. Rem confine scraping to the index or category page whenever possible for optimal efficiency. For instance, in product data extraction, prioritize this approach if information can be obtained from the shelf page without individual product requests. Real Data API addresses potential delays in spider repairs by employing a machine learning-based extraction tool. This tool automatically identifies target fields on the website and provides the desired results when traditional spiders encounter issues, ensuring continuous and reliable data extraction.
Building a Resilient Proxy Infrastructure for Precision in Enterprise Data Extraction
In the landscape of enterprise data extraction, constructing a scalable and robust proxy management infrastructure is pivotal. The foundation of a reliable web scraping endeavor at scale hinges on a well-managed proxy system, especially when targeting location-specific data.
Without a healthy and efficient proxy management system, teams can quickly find themselves entangled in proxy-related challenges, diverting valuable time from the primary goal of effective and scalable scraping. A substantial proxy pool is essential to achieve success in enterprise data extraction at scale. Implementation of IP rotation, request throttling, session management, and blacklisting logic becomes imperative to prevent proxy blockages.
Achieving the necessary daily throughput from spiders often demands the strategic design of spiders to counteract anti-bot measures without relying on resource-intensive headless browsers like Splash or Puppeteer. While these browsers effectively render JavaScript on pages, their resource-intensive nature significantly slows down scraping speeds, rendering them impractical for large-scale web scraping, except in rare scenarios where all other alternatives have been exhausted. Crafting a resilient proxy infrastructure is thus fundamental to ensuring precision and efficiency in enterprise data extraction initiatives on a substantial scale.
Implementing an Automated Data QA System for Enterprise Data Extraction
The linchpin is an automated data quality assurance (QA) system in any enterprise data extraction initiative. Often overlooked amid the emphasis on building spiders and managing proxies, QA becomes a critical concern when issues arise. The effectiveness of an enterprise data extraction project hinges on the quality of the data it generates. Regardless of the sophistication of the web scraping infrastructure, a robust system ensuring a reliable stream of high-quality information is indispensable.
Automation is critical to adequate data quality assurance for large-scale web scraping projects. Manual data quality validation becomes an insurmountable challenge when dealing with millions of records daily. An automated QA system streamlines the process, ensuring the enterprise data extraction project produces consistently accurate and reliable results. Prioritizing the automation of data QA is fundamental to scaling success in the dynamic landscape of web scraping.
Conclusion
A successful enterprise data extraction infrastructure hinges on aligning architecture with specific data requirements and prioritizing crawl efficiency. Building a foundation tailored to these needs ensures seamless automation of high-quality data extraction. Once all elements are operational, analyzing reliable and valuable data becomes a straightforward process, providing peace of mind for tackling complex projects.
Now equipped with the best practices for quality data extraction through enterprise web scraping, it's time to create your infrastructure. Connect with our team of expert developers at Real Data API to discover how effortlessly you can manage these processes. Accelerate your data extraction endeavors and unlock the full potential of your enterprise web scraping initiatives with Real Data API's tailored solutions.
Latest posts

How to scrape GeM procurement analytics data for manufacturers to Unlock Smarter Government Contract Opportunities?

The future of Data-as-a-Service in 2026 - Trends, Innovations, and Business Opportunities

How To Use AI Agents For Automated Data Collection and Analysis to Improve Business Intelligence And Decision-Making
How to Scrape Dynamic pricing strategies powered by travel data for Smarter Travel Pricing and Revenue Optimization
Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.







Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7


Disclaimer : RealData API functions solely as an independent data infrastructure and technology solutions provider. We build customized automation workflows designed to collect publicly accessible web data based exclusively on client instructions. RealData API neither owns proprietary datasets nor engages in the sale or redistribution of extracted information. Our operations are limited strictly to lawful public web data processing and never involve unauthorized access to restricted systems or private networks. Any company names, trademarks, logos, or brand references displayed on this website are used purely for demonstrative and illustrative purposes to showcase our technical capabilities and do not imply endorsement, partnership, or affiliation. Use of our platform and services remains subject to our Terms of Service.