
Introduction
In the dynamic landscape of the digital era, extracting valuable data from the vast expanse of the internet has become a necessity for businesses and developers alike. Web scraping, the automated process of harvesting information from websites, has emerged as a pivotal tool in this endeavor, offering insights that drive informed decision-making.
Headless scraping has revolutionized how data is gathered in the realm of web scraping. Headless scraping involves accessing website data without rendering a full browser, providing a more efficient and lightweight solution. Cheerio, an agile and swift library designed for web scraping in Node.js, is at the forefront of this technological evolution.
Cheerio stands out for its speed and simplicity, making it an ideal choice for developers seeking a seamless approach to web scraping. This blog will unravel the intricacies of headless scraping with Cheerio, delving into its significance in data extraction and demonstrating how it can be harnessed to navigate the complexities of the digital landscape.
Join us on this exploration as we delve into the art of headless scraping with Cheerio, unlocking a world of possibilities for efficient data extraction in Node.js. Embrace the power of technology to glean actionable insights and stay ahead in the ever-evolving digital frontier.
Understanding Headless Scraping: Navigating the Digital Landscape Efficiently
Headless scraping represents a paradigm shift in web scraping, revolutionizing how data is harvested from websites. Unlike traditional scraping methods that involve rendering an entire browser interface, headless scraping operates without a visible user interface, making it a more resource-efficient and faster approach.
The significance of headless scraping lies in its ability to extract data from websites in the background, streamlining the process by eliminating the need for graphical rendering. This efficiency translates into quicker data retrieval, reduced resource consumption, and improved overall performance. Headless scraping is advantageous when speed, resource optimization, and discretion are paramount.
Headless scraping shines when large datasets need to be extracted or when web pages contain dynamic content loaded via JavaScript. By bypassing the visual rendering of a browser, it enhances the scraping speed and responsiveness. This approach is invaluable for applications ranging from price monitoring and market analysis to data aggregation for business intelligence.
With its non-intrusive, streamlined methodology, headless scraping is a game-changer, offering developers a powerful tool to navigate the digital landscape efficiently and extract meaningful insights with unmatched speed and precision.
Setting Up Your Environment: A Seamless Entry into Headless Scraping with Cheerio
Embarking on the journey of headless scraping with Cheerio begins with setting up a robust development environment. Follow these straightforward steps to ensure a smooth initiation into the world of efficient web data extraction.
Step 1: Install npm and Node.js
Firstly, ensure that npm and Node.js are installed on your machine. Visit nodejs.org to download and install the latest version. npm, a Node.js packages manager, is included with the installation.
Step 2: Create a New Node.js Project
Open your terminal and direct to the required directory for your project. Execute the given command to create a new Node.js project:
npm init -y This command initializes a package.json file with default values, providing a foundation for managing dependencies and project configuration.
Step 3: Verify Your Setup
Confirm that npm and Node.js are installed correctly when running the given command:
node -v npm -vThese commands should display the installed versions of Node.js and npm, respectively.
With these fundamental steps completed, your environment is now primed for the exciting exploration of headless scraping with Cheerio. In the subsequent sections, we will delve deeper into installing the necessary dependencies and crafting the scraping script for a seamless web data extraction experience.
Installing Dependencies: Empowering Your Scraping Endeavor
Now that your Node.js environment is set up, the next crucial step is installing the indispensable npm packages that will propel your headless scraping journey forward. Follow these instructions to seamlessly integrate Cheerio and Puppeteer into your project.
Step 1: Install Cheerio and Puppeteer
In your terminal, execute the given command to install Cheerio and Puppeteer as dependencies for your project:
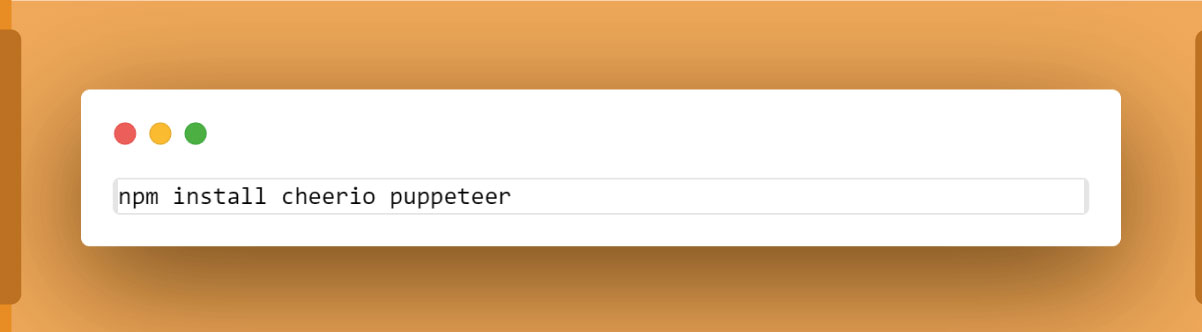
Cheerio is a lightweight and fast HTML parsing library that simplifies data extraction, while Puppeteer is a headless browser automation library that facilitates interaction with web pages. The combination of these two tools empowers you to efficiently navigate and extract data from websites.
Step 2: Understanding Puppeteer's Role
Puppeteer acts as the driving force behind headless browser automation. It allows you to launch and manipulate a headless browser, enabling the interaction with dynamic content and the retrieval of HTML data. This capability is especially crucial when dealing with websites that rely on JavaScript to load or display information
Step 3: Integration with Cheerio
The seamless integration of Puppeteer with Cheerio enhances the scraping process. After retrieving HTML content using Puppeteer, Cheerio comes into play, providing a simplified way to parse and traverse the HTML structure. This dual-tool approach ensures efficient data extraction, making your scraping endeavors not only powerful but also flexible.
With these dependencies installed and integrated, you are now equipped to harness the combined strengths of Cheerio and Puppeteer for a robust and efficient headless scraping experience. The subsequent section will guide you through the process of crafting a scraping script that leverages these tools to their fullest potential.
Writing the Scraping Script: Unveiling the Magic of Headless Scraping with Cheerio
Now that your environment is set up and dependencies are installed, let's delve into the creation of a robust scraping script using JavaScript. Follow these steps to harness the power of a headless browser and the simplicity of Cheerio for efficient web data extraction.
Step 1: Create a New JavaScript File
Open your code editor and create a new JavaScript file, let's call it scrape.js. This will be the canvas for your scraping masterpiece.
Step 2: Launching a Headless Browser with Puppeteer
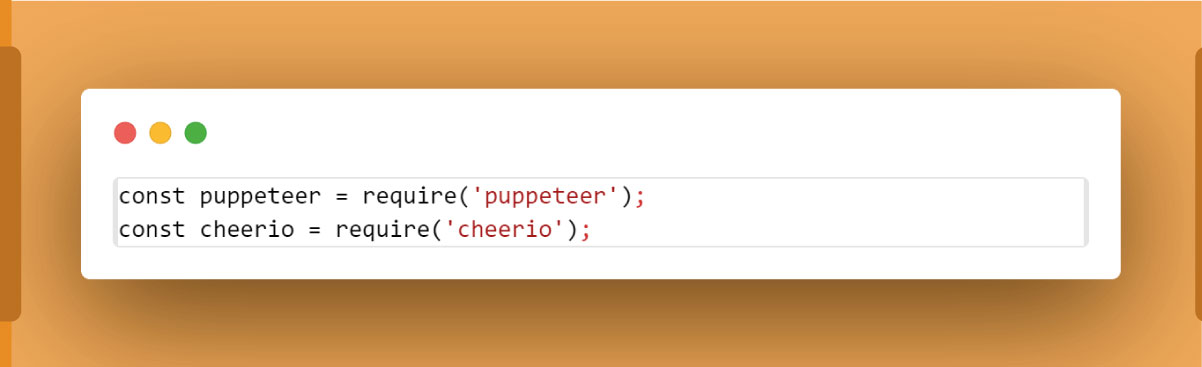
Inside scrape.js, begin by requiring the necessary libraries:
Now, let's initiate a headless browser and navigate to the desired URL:
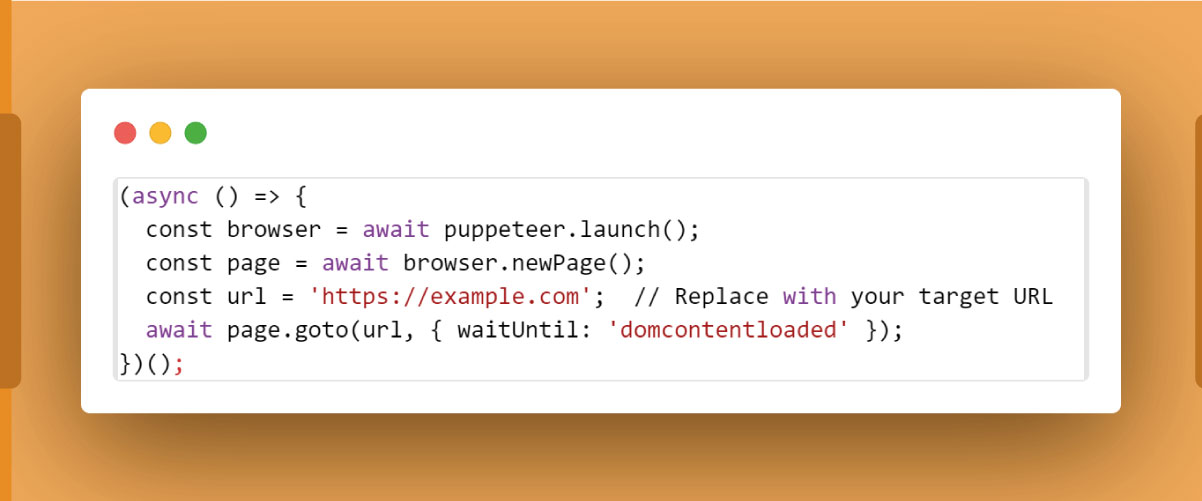
Step 3: Retrieving HTML Content
Once on the page, retrieve the HTML content using Puppeteer:
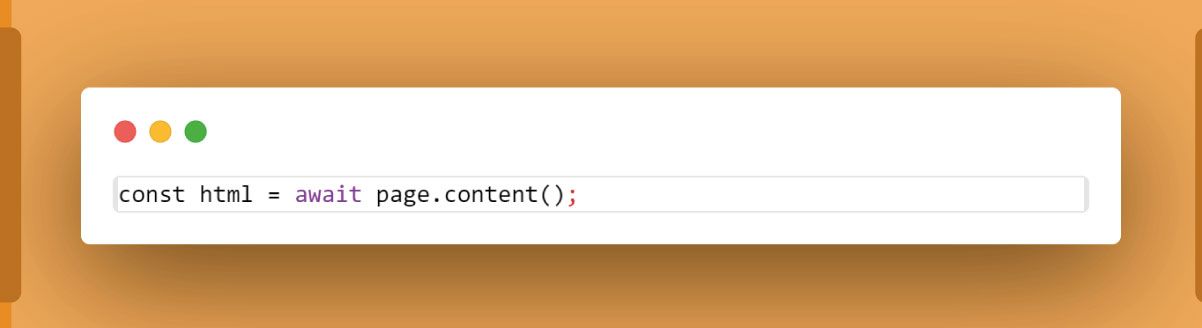
Step 4: Introducing Cheerio for Data Extraction
Load the HTML content into Cheerio to make data extraction a breeze:
Now, you can use Cheerio selectors to pinpoint and extract the data you need. For instance, extracting the title:

Step 5: Closing the Headless Browser
Don't forget to gracefully close the headless browser:

This script is your gateway to a world of web scraping possibilities. Customize the selectors based on the target website's structure, and watch as Cheerio effortlessly transforms HTML into actionable data. In the upcoming sections, we'll explore advanced customization and best practices to refine your scraping prowess.
Customizing the Script: Tailoring Your Scraping Journey
Now that you have a foundation for your scraping script, let's explore the art of customization, a key aspect that elevates your scraping endeavors to precision. Customizing the script involves adjusting selectors and extraction logic to align with the unique structure of the target website, ensuring accurate and relevant data retrieval.
Selectors and Their Significance:
Selectors are the linchpin of your scraping script, acting as a guide to pinpoint specific elements within the HTML structure. For instance, to extract product information from an e-commerce site, you might target the product title, price, and description. Customize selectors accordingly:

Adapting to Website Structure:
Different websites have varying structures, and understanding the HTML hierarchy is crucial for effective customization. Use browser developer tools to inspect the HTML and identify unique classes, IDs, or tags associated with the data you seek. Modify the script accordingly to match the structure:

Iterative Development:
Customization is an iterative process. Run your script, inspect the results, and refine your selectors until you achieve the desired output. Be resilient and adaptable as you navigate the nuances of different websites.
Best Practices for Customization:
Prioritize unique and stable identifiers.
Consider potential changes to the website's structure over time.
Employ regular expressions if necessary for more intricate data extraction.
Empower your scraping script with the finesse of customization, turning it into a versatile tool capable of extracting valuable insights from diverse web landscapes. In the next section, we'll delve into running the script and witnessing the fruits of your customization efforts.
Running the Script: Unleashing the Power of Your Customized Scraping Engine
Now that you've meticulously crafted your scraping script and customized it to match the unique structure of your target website, it's time to set it in motion. Follow these steps to run your script and witness the magic of data extraction.
Step 1: Open Your Terminal
Navigate to the directory where your scrape.js file resides. Open your terminal or command prompt.
Step 2: Execute the Script with Node.js
Run your script using the node command:
Step 3: Replace the URL Placeholder
As the script launches, ensure you replace the placeholder URL ('https://example.com') with the actual URL of the website you intend to scrape. This step is crucial as it directs the headless browser to the target destination.

Step 4: Observe the Output
As the script executes, monitor the terminal for output. You should see the results of your data extraction efforts, such as the title, prices, or any other information you targeted in your customization phase.
Step 5: Iterate and Refine
If the output doesn't match your expectations, revisit the customization phase. Adjust selectors and logic based on the actual structure of the website, rerun the script, and observe the changes. This iterative process ensures your script evolves to suit the intricacies of the target site.
By running your customized scraping script, you unlock the potential to gather valuable data with precision. Remember, the real power lies in the adaptability of your script, allowing you to conquer various websites and extract meaningful insights. In the upcoming sections, we'll explore best practices, compliance, and advanced techniques to further refine your scraping skills.
Best Practices and Compliance: Navigating the Ethical Landscape of Web Scraping
As you embark on your web scraping journey, it's imperative to adhere to best practices and ethical guidelines to ensure both the success of your scraping efforts and compliance with legal and ethical standards.
1. Respect Robots.txt:
Before scraping a website, check its robots.txt file. This file outlines rules and permissions for web crawlers. Adhering to these guidelines demonstrates respect for the website's wishes and helps you avoid potential legal repercussions.
2. Use Legal Sources:
Ensure your scraping activities are directed at publicly accessible data and adhere to the website's terms of service. Avoid scraping sensitive or private information and respect copyright laws.
3. Limit the Frequency of Requests:
Implement delays between requests in your scraping script to avoid undue strain on a website's server. This respects the website's resources and helps you maintain a low profile.
4. Identify Yourself:
Set a user agent in your scraping script to identify your activity. Some websites may block or restrict access to unidentified or suspicious agents, and providing information about your scraping intentions is a courteous practice.
5. Monitor Changes in Website Structure:
Websites can undergo structural changes, impacting the efficacy of your scraping script. Regularly check for updates and adjust your script accordingly to maintain reliability.
6. Be Mindful of Volume:
Avoid scraping large amounts of data in a short period, as this may lead to IP blocking or other defensive measures by the website.
7. Seek Legal Advice:
If you need more clarification on the legality of your scraping activities, seek legal advice. Understanding the legal landscape ensures you operate within ethical boundaries and safeguards against potential legal issues.
By adhering to these best practices, you enhance the effectiveness of your scraping efforts and contribute to a responsible and ethical web scraping community. Stay mindful of the impact of your activities and respect the digital ecosystem you explore.
Conclusion
In this guide, we explored the prowess of headless scraping with Cheerio, a dynamic duo for efficient data extraction. Key takeaways include:
Launching headless browsers with Puppeteer.
Customizing scripts for unique structures.
Running them with precision.
Headless scraping ensures faster, resource-efficient data retrieval, empowering decisions.
Embark on your web scraping journey using Cheerio and headless scraping. Customize scripts, run them on diverse websites, and unlock real-time insights. Experiment, learn, and propel your projects to new heights. For further skills enhancement, contact Real Data API now! Your web scraping mastery awaits!
Latest posts

Web Scraping Competitor Product Monitoring Using Marketplace Data for Real-Time E-commerce Insights and Business Growth?

How to Scrape Product Intelligence Platform Using Marketplace Data to Help Brands Optimize Pricing, Inventory, and Product Strategy?

Why Companies scrape business data from Google Maps using keywords to Build Accurate Business Lists and Competitive Insights?

How Review scraping and monitoring services Help Businesses Track Customer Sentiment and Protect Brand Reputation in 2026?

How Real Estate Investment Insights Using RERA Data Scraping Help Investors Minimize Risk and Maximize Returns
Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.







Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7


Disclaimer : RealData API functions solely as an independent data infrastructure and technology solutions provider. We build customized automation workflows designed to collect publicly accessible web data based exclusively on client instructions. RealData API neither owns proprietary datasets nor engages in the sale or redistribution of extracted information. Our operations are limited strictly to lawful public web data processing and never involve unauthorized access to restricted systems or private networks. Any company names, trademarks, logos, or brand references displayed on this website are used purely for demonstrative and illustrative purposes to showcase our technical capabilities and do not imply endorsement, partnership, or affiliation. Use of our platform and services remains subject to our Terms of Service.