

Introduction
In the dynamic realm of Web scraping, scalability emerges as a pivotal force, influencing the efficiency, speed, and overall success of scraping endeavors. As the volume of data to be extracted grows, the need for scalable solutions becomes paramount. Enter Scrapy, a formidable Python framework that stands as a beacon for those seeking to build web scrapers that can gracefully handle large-scale projects.
Introducing Scrapy: The Scalability Maestro:
Scrapy, renowned for its elegance and versatility, takes center stage as a powerful ally in the pursuit of scalable web scraping. With its robust architecture and features, Scrapy empowers developers to navigate scalability challenges seamlessly. Whether scraping a handful of pages or scaling up to thousands, Scrapy's efficiency remains unmatched.
Objectives of the Handbook: Scalable Wisdom Unveiled:

This handbook is crafted with a singular goal – to provide an exhaustive resource for those aspiring to master the art of building efficient and scalable web scrapers with Scrapy. From understanding the fundamentals of scalability in web scraping to delving into the intricacies of Scrapy's features, the handbook aims to equip readers with the knowledge and tools needed to tackle projects of any magnitude. Join us on this journey, where scalability meets mastery in the world of web scraping with Scrapy.
Unveiling the Essence of Scalability in Web Scraping
Scalability in web scraping encapsulates the ability of a scraping system to adapt and handle varying workloads seamlessly, ensuring consistent performance and data retrieval efficiency irrespective of the project's size. It is the fundamental measure of a scraper's resilience and responsiveness as it grapples with the dynamic landscape of the internet.
Defining Scalability:

Scalability, in the realm of web scraping, is the capacity of a scraping solution to efficiently process and retrieve data as the volume and complexity of the target web pages increase. A scalable web scraper should demonstrate consistency in its performance, maintaining optimal speed and effectiveness regardless of the scale of the scraping project.
Challenges of Scaling Up Web Scraping Projects:
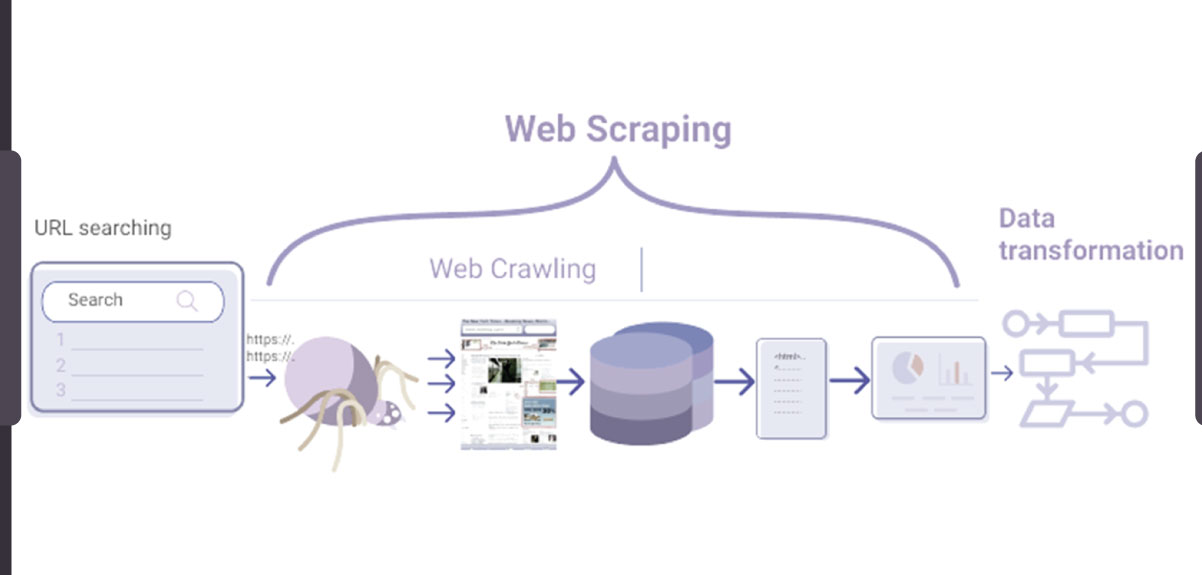
Scaling up web scraping projects introduces a myriad of challenges. The surge in data volume can strain the computational resources, leading to potential bottlenecks in performance. Managing concurrent requests, handling dynamic content, and ensuring compliance with website policies become intricate tasks as the scope of the scraping initiative expands.
Impact of Scalability on Performance and Data Retrieval:
Scalability profoundly influences the efficiency of performance and the effectiveness of data retrieval. A scalable web scraper ensures that as the project grows, it maintains a high level of performance, avoiding sluggishness or resource exhaustion. Additionally, scalability directly impacts the speed and reliability of data retrieval, ensuring timely and accurate extraction even in extensive scraping endeavors.
Understanding the nuances of scalability lays the foundation for building robust web scraping solutions capable of navigating the challenges presented by projects of varying magnitudes.
Unleashing Scrapy: A Pinnacle in Web Scraping Prowess
At the forefront of web scraping excellence stands Scrapy, a robust Python framework revered for its versatility, efficiency, and scalability. Designed to facilitate the seamless extraction of data from websites, Scrapy offers a robust set of features that elevate it to the status of a go-to tool for developers venturing into the realm of scalable web scraping.
Overview of Scrapy and Its Features:
Scrapy, an open-source framework, provides a structured and extensible platform for building web scrapers. It excels in handling the complexities of data extraction, offering a high-level and expressive approach to crafting spiders. With built-in support for shared web scraping tasks like following links and handling cookies, Scrapy streamlines the scraping process.
Advantages of Using Scrapy for Scalable Scraping:
Scrapy's architectural brilliance and feature-rich nature make it ideal for building scalable web scrapers. Its asynchronous design, comprehensive documentation, and built-in support for handling concurrent requests make it adept at managing the challenges presented by large-scale scraping projects. Scrapy's adaptability ensures a smooth scaling process, enabling developers to tackle extensive scraping initiatives easily.
Real-World Triumphs with Scrapy:
Scrapy's prowess isn't confined to theory – it has proven its mettle in the field. Numerous real-world projects testify to Scrapy's ability to scale and handle diverse scraping requirements. Scrapy has played a pivotal role in the success of varied and impactful web scraping endeavors, from harvesting data for research purposes to aggregating content for business intelligence.
Scrapy emerges as a beacon of efficiency and reliability, beckoning developers to harness its capabilities for crafting robust and scalable scraping solutions as we delve into the world of scalable web scraping.
Navigating the Scrapy Universe: Setting Up Your Project for Success
Embarking on a Scrapy-driven web scraping journey requires a well-defined starting point. Let's guide you through the essential steps to set up your Scrapy project with precision.
Installation of Scrapy:
Begin your Scrapy adventure by ensuring the framework is installed. Execute a straightforward installation command, typically using pip:
pip install scrapyWith Scrapy now at your fingertips, you've laid the foundation for crafting robust web scrapers.
Creating a New Scrapy Project:
Initiate your project with Scrapy's intuitive command-line tool. Navigate to your desired directory and execute:
scrapy startproject your_project_nameThis command generates a structured directory, complete with the necessary files and folders, marking the birth of your Scrapy project.
Unveiling the Project Structure:
Dive into the structure of your newly minted Scrapy project. Key components include the 'spiders' directory, housing your scraping scripts, and the 'items.py' file, defining the data structure you aim to extract. The 'settings.py' file offers a centralized hub for project configurations.
As you set sail on your Scrapy project, understanding its anatomy empowers you to wield the framework's full potential. Prepare to navigate the web-scraping seas with confidence, armed with a well-configured Scrapy project.
Mastering Web Crawling Efficiency with Scrapy Spiders
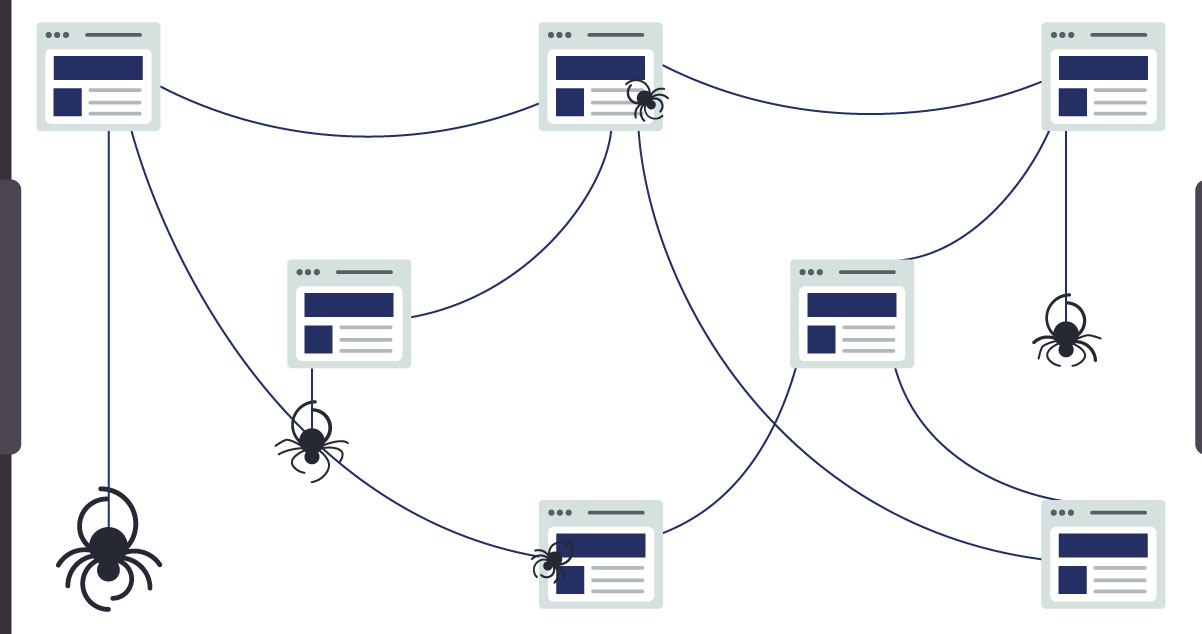
In the intricate world of Scrapy, spiders emerge as the arachnid architects orchestrating the web-scraping symphony. Understanding their pivotal role is paramount for efficient and targeted data extraction.
The core of the Scraping Process:
Scrapy spiders serve as the beating heart of the scraping process. Think of them as intelligent agents programmed to navigate the web, locate desired content, and bring it back to your web-scraping lair. These spiders are designed to crawl through websites, extracting data as they traverse the digital terrain.
Creating and Configuring Spiders:
Crafting a Scrapy spider involves defining a Python class inherited from Scrapy's Spider class. Configure your spider with a start URL, define parsing methods, and employ XPath or CSS selectors to pinpoint the data you seek. This tailored approach ensures your spider's precision in extracting relevant information from specific websites.
Spider Rules and Efficient Crawling:
Spider rules are your Scrapy spider's guiding principles, dictating its behavior during the crawl. Specify domains to traverse, define URL patterns to follow or ignore, and set rules for efficient navigation. Thoughtful rule configuration ensures your spider focuses on the target data, avoiding unnecessary detours and optimizing the scraping process.
As you delve into the realm of Scrapy Spiders, consider them as your skilled agents navigating the web's intricate threads. By mastering their creation and configuration and adhering to efficient crawling principles, you wield the power to extract data with precision and finesse.
Elevating Scalability: Unleashing Advanced Features in Scrapy
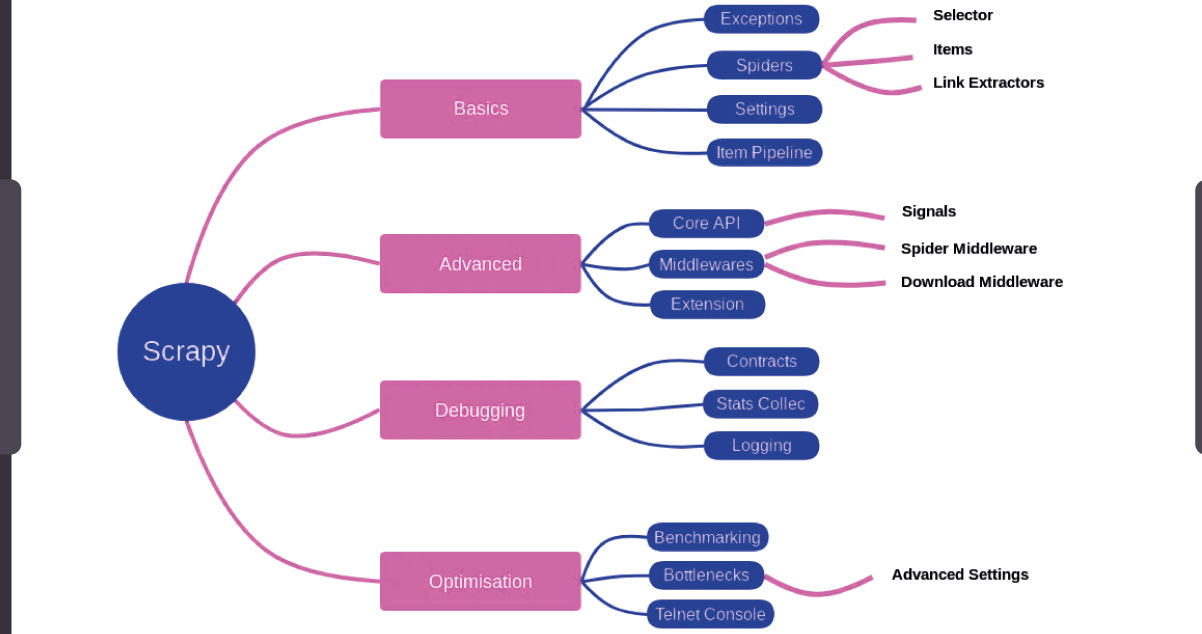
To truly harness the scalability potential of Scrapy, venture into the realm of advanced features that elevate your web scraping endeavors to new heights.
Middleware, Extensions, and Pipelines:
Scrapy's arsenal includes powerful tools such as middleware, extensions, and pipelines, each playing a distinctive role in enhancing scalability. Middlewares offer a customizable layer to preprocess requests and responses, while extensions allow for fine-tuning Scrapy's behavior. Pipelines enable efficient data processing and storage, collectively fortifying your scraper for large-scale operations.
Distributed Crawling for Large-Scale Projects:
As your scraping ambitions grow, distributed crawling emerges as a strategic ally. Scrapy supports distributed crawling through frameworks like Scrapyd, allowing you to deploy spiders across multiple servers. This distributed approach enhances efficiency by parallelizing the scraping process, reducing the time required for extensive projects.
Optimizing Scrapy Settings for Performance:
Unlock the full potential of Scrapy by fine-tuning its settings for optimal performance. Adjusting parameters like concurrency settings, download delays, and retry mechanisms ensures your scraper operates seamlessly, even in challenging web environments. These optimizations are instrumental in maintaining the efficiency and responsiveness of your scraping project.
As you delve into the advanced features of Scrapy, consider them your secret weapons for conquering large-scale scraping challenges. Middleware magic, distributed crawling prowess, and performance optimization strategies collectively empower your scraper, transforming it into a scalable force within the web scraping arena.
Decoding Dynamism: Mastering Dynamic Content and AJAX Challenges with Scrapy

Navigating the ever-evolving landscape of the web requires adept handling of dynamic content and AJAX requests. In the realm of Scrapy, addressing these challenges becomes a nuanced yet essential aspect of web scraping expertise.
Challenges and Solutions:
Dynamic content, often fueled by AJAX, poses hurdles for traditional web scrapers. Scrapy, however, offers solutions to handle these challenges gracefully. By incorporating techniques that synchronize with the dynamic nature of web pages, Scrapy becomes a reliable ally for extracting data from JavaScript-driven elements.
Handling JavaScript-Driven Pages:
Scrapy seamlessly integrates with the headless browser Splash to conquer JavaScript-driven pages. By rendering the page content, including dynamically loaded elements, Splash empowers Scrapy to navigate and extract data from websites heavily reliant on JavaScript. This tandem approach ensures a comprehensive scraping experience, even in the presence of intricate client-side scripting.
Scrapy with Additional Tools:
For an extra layer of dynamism, combining Scrapy with tools like Selenium or Puppeteer enhances its prowess. These tools simulate browser behavior, enabling Scrapy to interact with pages as a user would. This collaboration proves invaluable when tackling websites that demand user-like interactions for content retrieval.
As you embark on the journey of handling dynamic content and AJAX with Scrapy, consider it a strategic dance with the dynamic rhythms of the web. With these techniques and complementary tools, Scrapy positions itself as a versatile and powerful companion, ready to conquer the challenges of modern, interactive web pages.
Navigating the Web Scraping Seas: Overcoming Scalability Challenges with Scrapy
In the expansive realm of web scraping, scalability issues can emerge as formidable adversaries. Recognizing these challenges and arming yourself with practical solutions is pivotal for a successful scraping journey, and Scrapy stands as your stalwart ally in conquering common scalability hurdles.
Identifying Scalability Challenges:
Common scalability pitfalls include increased server load, potential IP blocking, and challenges handling vast datasets. As the scale of web scraping projects amplifies, the risk of encountering these issues intensifies, demanding a strategic approach to mitigate potential roadblocks.
Solutions and Best Practices with Scrapy:
Scrapy offers a robust toolkit to address scalability concerns. Implementing autothrottle, which dynamically adjusts request rates, helps manage server load effectively. Utilizing distributed crawling with Scrapyd ensures parallelized scraping, reducing the risk of IP blocks and enhancing overall project efficiency. Employing these Scrapy-centric solutions ensures that your scraping endeavors can adeptly handle scaling challenges.
Monitoring and Maintenance Tips:
Proactive monitoring is the key to maintaining scalable scraping projects. Leverage Scrapy's built-in logging and stats features to keep a vigilant eye on performance metrics. Implement automated monitoring tools to detect anomalies and ensure continuous project health. Regularly review and adjust scraping parameters to align with evolving website structures, safeguarding your project against potential disruptions.
As you navigate the web scraping seas, let Scrapy guide you. By understanding, anticipating, and leveraging Scrapy's capabilities, you overcome common scalability issues and ensure a resilient and sustainable web scraping expedition.
Embarking on Scalable Scraping Mastery: Unveiling Scrapy's Prowess
As we conclude this insightful handbook journey, let's distill the key takeaways that illuminate the path to scalable web scraping prowess with Scrapy.
Key Takeaways:
Scrapy's Power Unleashed: Scrapy emerges as a dynamic force, offering a structured and extensible framework for crafting web scrapers with scalability in mind.
Advanced Features for Precision: Features like middlewares, extensions, and pipelines elevate your scraping projects, providing unparalleled control and efficiency.
Dynamic Content Conquered: Scrapy's ability to handle dynamic content and AJAX requests, coupled with integration options like Splash, ensures adaptability to the modern web's complexities.
Scalability Solutions: Recognizing and addressing common scalability challenges with Scrapy's distributed crawling, autothrottle, and other tools ensures a resilient and efficient scraping experience.
The Scalability Imperative:Scalability isn't just a feature; it's the bedrock of building robust web scrapers. It ensures your scraping projects can gracefully evolve with the demands of an ever-changing digital landscape.
Apply and Innovate:As you absorb the insights from this handbook, we urge you to apply this knowledge actively. Let Scrapy be your ally in crafting scraping solutions that not only meet but exceed scalability expectations. Embrace innovation, experiment with advanced features, and witness your web scraping projects transform into dynamic and scalable endeavors.
Explore Real Data API for Unmatched Insights:For those ready to elevate their data game further, explore the possibilities of Real Data API. Unlock unmatched insights and efficiency in data extraction, seamlessly integrating with your scalable scraping solutions. Let innovation flourish, powered by the combined strength of Scrapy and Real Data API.
The journey doesn't end here; it evolves. Let your scraping endeavors be marked by scalability, precision, and continuous innovation. Happy scraping!
Latest posts
Why Brands Use Competitive Data Intelligence to Increase Market Share in Highly Competitive Markets?

How To Scrape Competitor Data To Support Market Entry Strategy And Expansion Planning For Data-Driven Business Growth?

How Hotel Occupancy Intelligence Through Public Data Sources Is Reshaping Revenue Management

The ZIP Code Advantage: How Hyper-Local Amazon Product Data Collection Is Redefining Retail Intelligence
Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.







Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7


Disclaimer : RealData API functions solely as an independent data infrastructure and technology solutions provider. We build customized automation workflows designed to collect publicly accessible web data based exclusively on client instructions. RealData API neither owns proprietary datasets nor engages in the sale or redistribution of extracted information. Our operations are limited strictly to lawful public web data processing and never involve unauthorized access to restricted systems or private networks. Any company names, trademarks, logos, or brand references displayed on this website are used purely for demonstrative and illustrative purposes to showcase our technical capabilities and do not imply endorsement, partnership, or affiliation. Use of our platform and services remains subject to our Terms of Service.