

Introduction
Web scraping, the process of extracting data from websites, offers businesses invaluable insights. Amazon web scraping, facilitated by tools like an Amazon data scraper or Amazon API dataset, provides access to crucial product information. This data is particularly beneficial for price comparison and market research, aiding businesses in making informed decisions.
With an Amazon ASINs data scraper, businesses can gather details on specific products, streamlining the process of obtaining accurate and up-to-date information. Amazon scraping services further enhance this capability, ensuring efficiency and accuracy. Whether for tracking prices, analyzing market trends, or optimizing strategies, the ability to scrape Amazon product data empowers businesses to stay competitive and agile in the dynamic e-commerce landscape. Harnessing this data-rich resource becomes essential for businesses seeking a comprehensive understanding of the market and seeking avenues for growth.
Understanding the Basics
Understanding the basics of scraping Amazon product data involves recognizing the importance of ethical practices. When engaging in Amazon web scraping, it is crucial to respect robots.txt directives and avoid overloading Amazon's servers. Ethical considerations extend to legal aspects, where scraping data from websites, including Amazon, must comply with terms of service and relevant laws.
Amazon data scraper tools, Amazon ASINs data scraper, and Amazon API datasets should be employed responsibly to gather information for purposes such as price comparison and market research. Adhering to ethical guidelines ensures fair usage and prevents potential legal consequences. Embracing responsible practices in Amazon scraping services not only safeguards against legal issues but also fosters a positive and sustainable approach to leveraging web data for business insights, promoting transparency and integrity in the data extraction process.
Setting Up the Environment
Setting up the environment for web scraping involves a few key steps. First, ensure Python is installed on your system. Creating a virtual environment (optional but recommended) helps manage dependencies. To do so, open a terminal and run:
Activate the virtual environment:
On Windows:
./venv/Scripts/activate
On macOS/Linux:
source venv/bin/activate
Now, install the necessary libraries:
pip install requests beautifulsoup4
Here, 'requests' facilitates HTTP requests, while 'BeautifulSoup' aids in HTML parsing. With the environment set up, you're ready to commence web scraping using Python. Be mindful of ethical considerations, adhere to website terms of service, and respect any relevant guidelines, ensuring responsible and legal scraping practices.
Analyzing Amazon Product Pages
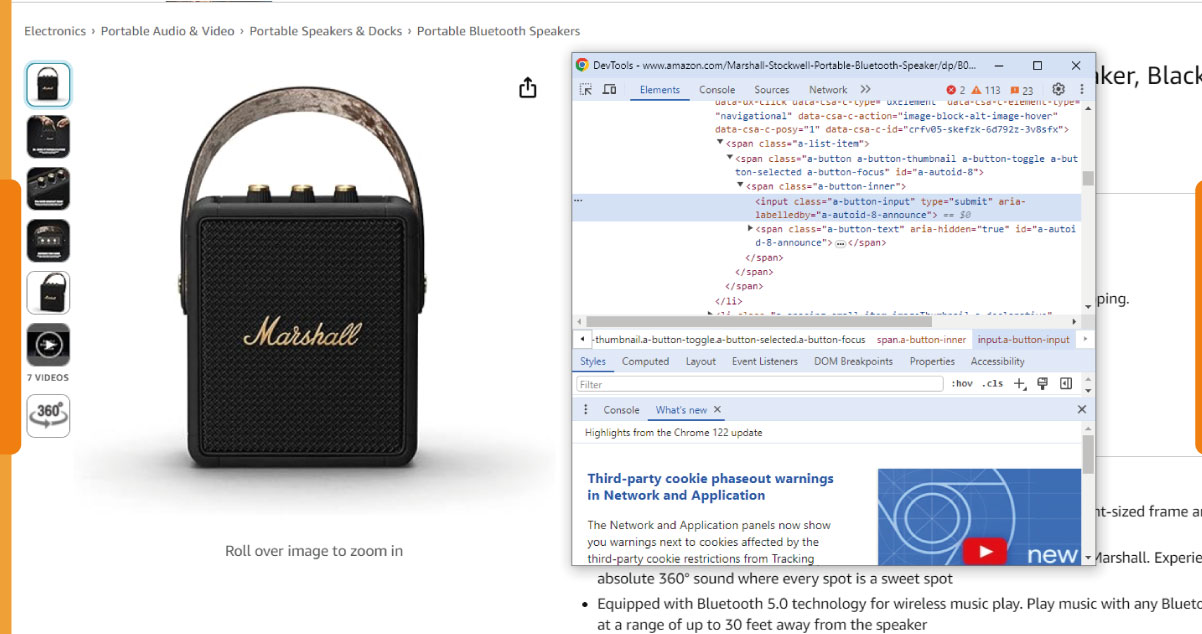
Identifying desired data points on an Amazon product page can be done effectively using browser developer tools, such as Chrome DevTools. Here's a step-by-step guide focusing on common elements:
Open Developer Tools:
Right-click on the element you want to inspect (e.g., product title) on the Amazon product page and select "Inspect" or press Ctrl+Shift+I (Windows/Linux) or Cmd+Opt+I (Mac) to open Chrome DevTools.
Locate HTML Elements:
Use the "Elements" tab to explore the HTML structure. For the product title, look for a relevant HTML tag and class, usually associated with the title. Repeat this process for other elements like price, description, image URL, rating, and number of reviews.
Copy Selectors or XPath:
Right-click on the HTML element in the "Elements" tab and select "Copy" > "Copy selector" or "Copy XPath." This copied information helps locate the element programmatically.
Utilize Developer Console:
Switch to the "Console" tab and test your selectors. For example:
document.querySelector('your-selector-for-title').textContent
This allows you to verify that the selected elements correspond to the desired data points.
Implement in Your Code:
Use the identified selectors in your Python code, combining them with libraries like requests and BeautifulSoup to scrape the data. For instance:

Remember to check Amazon's terms of service, robots.txt, and legal considerations to ensure compliance while scraping data. Additionally, respect the website's policies to maintain ethical scraping practices.
Retrieving Page HTML:
To retrieve the HTML content of an Amazon product page using the requests library in Python, follow these steps:
Explanation:
Import requests:
Import the requests library to make HTTP requests.
Define Amazon Product URL:
Set the amazon_url variable to the desired Amazon product page URL.
Send GET Request:
Use requests.get(amazon_url) to send an HTTP GET request to the specified URL.
Check Status Code:
Verify that the request was successful by checking the status code (200 indicates success).
Store HTML Content:
If the request was successful, store the HTML content in the html_content variable using response.text.
Print Preview:
Optionally, print a preview of the HTML content (first 500 characters in this example) to verify successful retrieval.
Now, html_content holds the HTML of the Amazon product page, allowing you to proceed with parsing and extracting the desired data using tools like BeautifulSoup.
Scraping Product Details Using Python Libraries:
Scraping product details using Python involves parsing HTML, and the BeautifulSoup library is a powerful tool for this purpose. Follow these steps to extract desired data points:
Install BeautifulSoup:
If not installed, use the following command:
pip install beautifulsoup4
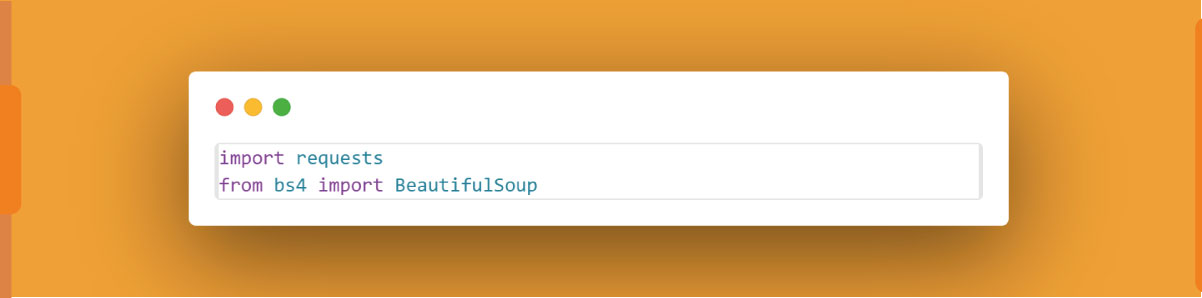
Import Libraries:
In your Python script, import the necessary libraries:
Retrieve HTML:
Use the requests library to send an HTTP GET request and store the HTML content:

Parse HTML with BeautifulSoup:
Create a BeautifulSoup object to parse the HTML:
soup = BeautifulSoup(html_content, 'html.parser')
Find and Extract Data Points:
Use BeautifulSoup methods like find() or select_one() to locate specific HTML elements. For example, to extract the product title:
title = soup.select_one('span#productTitle').text.strip()
Repeat this process for other data points like price, description, image URL, rating, and number of reviews.
Print or Store Results:
Print or store the extracted data points:
print(f'Title: {title}')
Adapt the code for other data points as needed.
Here's a comprehensive example extracting title and price:
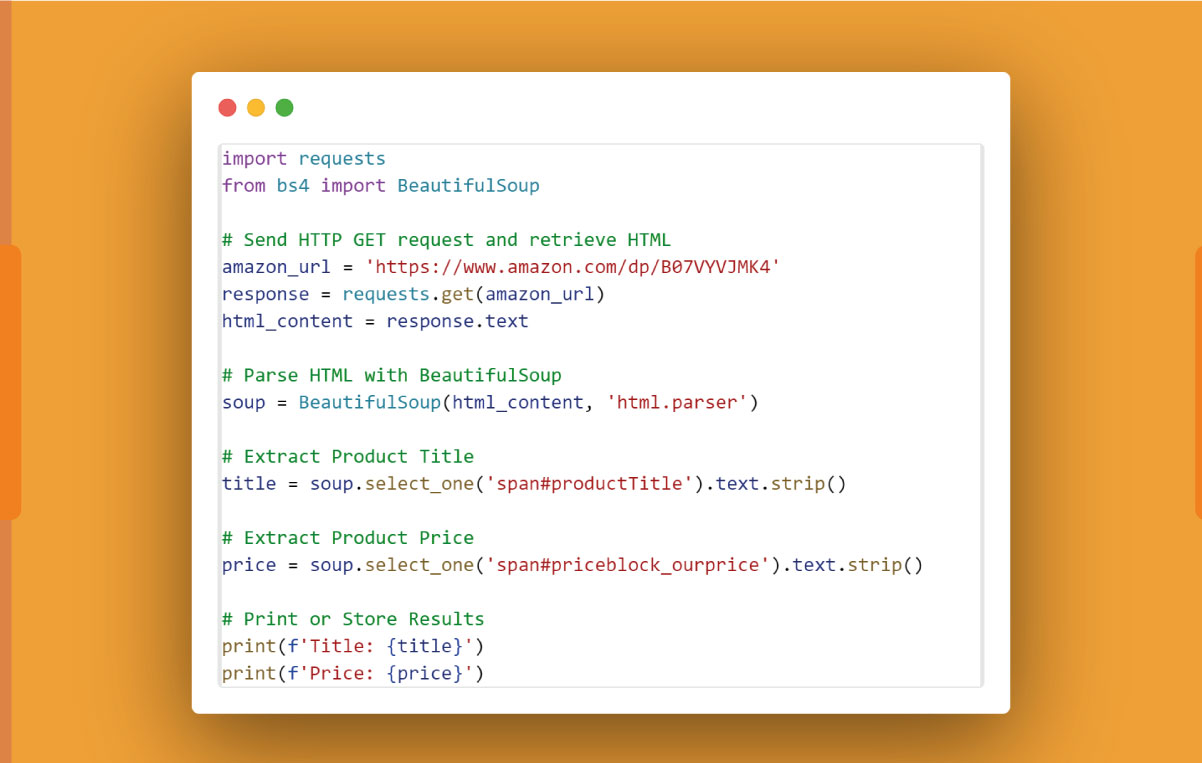
Adapt the code for other data points by inspecting the HTML structure with browser developer tools and utilizing appropriate BeautifulSoup methods.
Product Title:
To find the product title element on an Amazon product page and extract its text content using its unique identifier (id) or CSS selector, you can use the following example with BeautifulSoup in Python:

Explanation:
Send HTTP GET request and retrieve HTML: Use the requests library to fetch the HTML content of the Amazon product page.
Parse HTML with BeautifulSoup: Create a BeautifulSoup object to parse the HTML.
Find Product Title using id: Use the find method to locate the product title element with a specific id and extract its text content.
Find Product Title using CSS selector: Use the select_one method with a CSS selector to locate the product title element and extract its text content.
Print or store the extracted title: Display the product title or indicate if it was not found.
Inspect the Amazon product page's HTML structure with browser developer tools to identify the appropriate id or CSS selector for the product title. Adjust the code accordingly for other elements like price, description, etc.
Product Image:
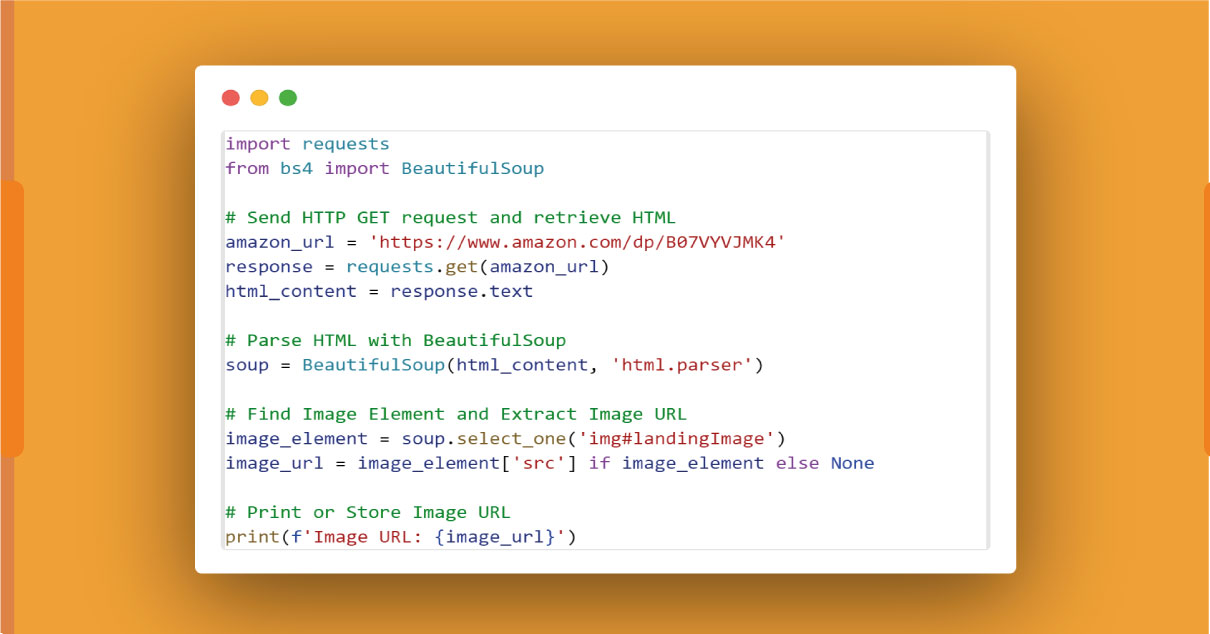
To extract the product image URL using Python and BeautifulSoup, follow these steps:
Identify Image Element:
Inspect the HTML structure of the product page using browser developer tools. Locate the image element, usually represented by the tag.
Find Image URL with BeautifulSoup:
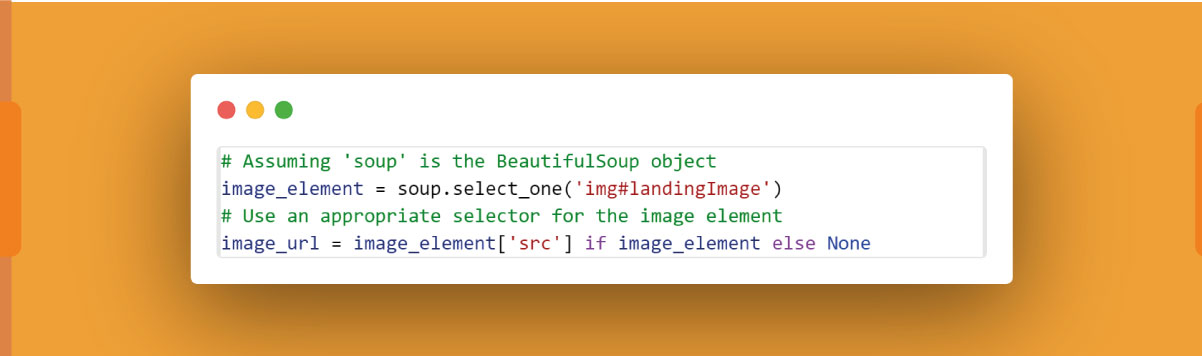
Here, 'img#landingImage' is a sample CSS selector, and you should adapt it based on the actual HTML structure of the image element on the Amazon product page.
Print or Store the Image URL:
Print or store the extracted image URL as needed:
Ensure to check if the image element exists (if image_element) to avoid potential errors if the image is not found.
Here's an example using the BeautifulSoup code snippet:
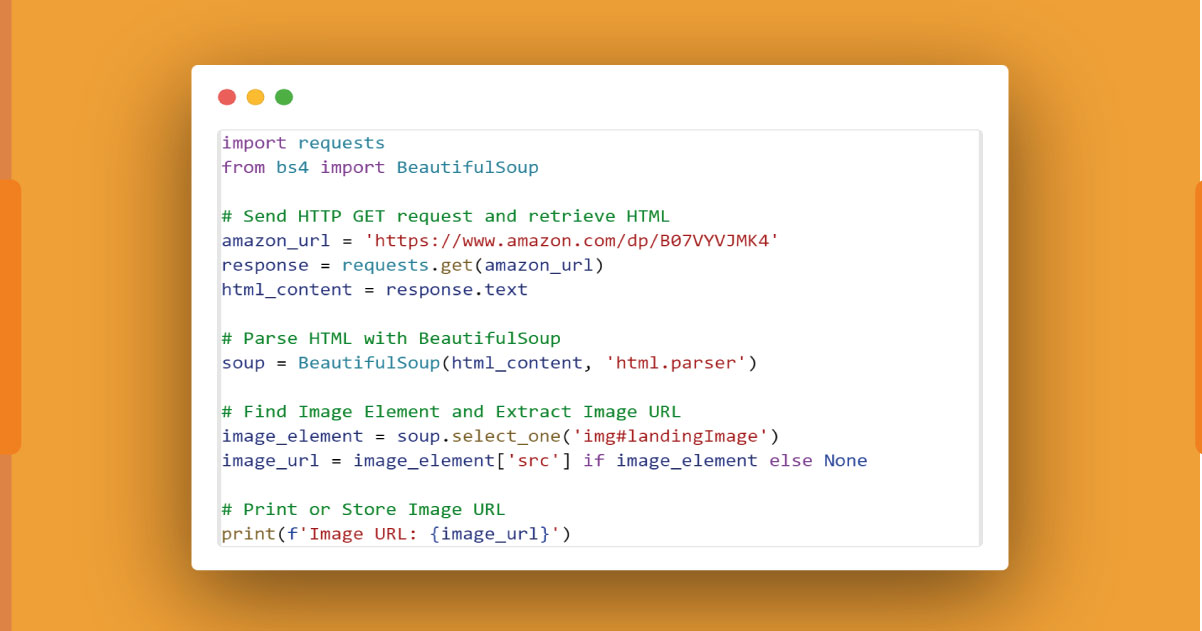
Adapt the code based on the specific HTML structure of the image element on the Amazon product page.
Product Description:
To extract the product description text using Python and BeautifulSoup, you can follow these steps:
Identify Description Element:
Inspect the HTML structure of the product page using browser developer tools. Locate the HTML element containing the product description, such as a
<div> or a <p> tag.
Find Description Text with BeautifulSoup:
Use BeautifulSoup methods to find the description element and extract its text content. For example:
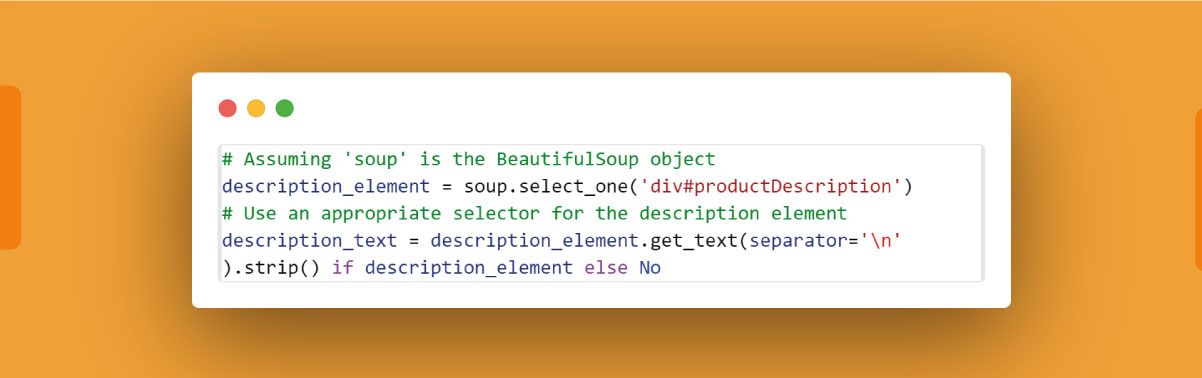
Here, 'div#productDescription' is a sample CSS selector, and you should adapt it based on the actual HTML structure of the description element on the Amazon product page.
Print or Store the Description Text:
Print or store the extracted description text as needed:
print(f'Product Description: {description_text}')
Ensure to check if the description element exists (if description_element) to avoid potential errors if the description is not found.
Here's an example using the BeautifulSoup code snippet:
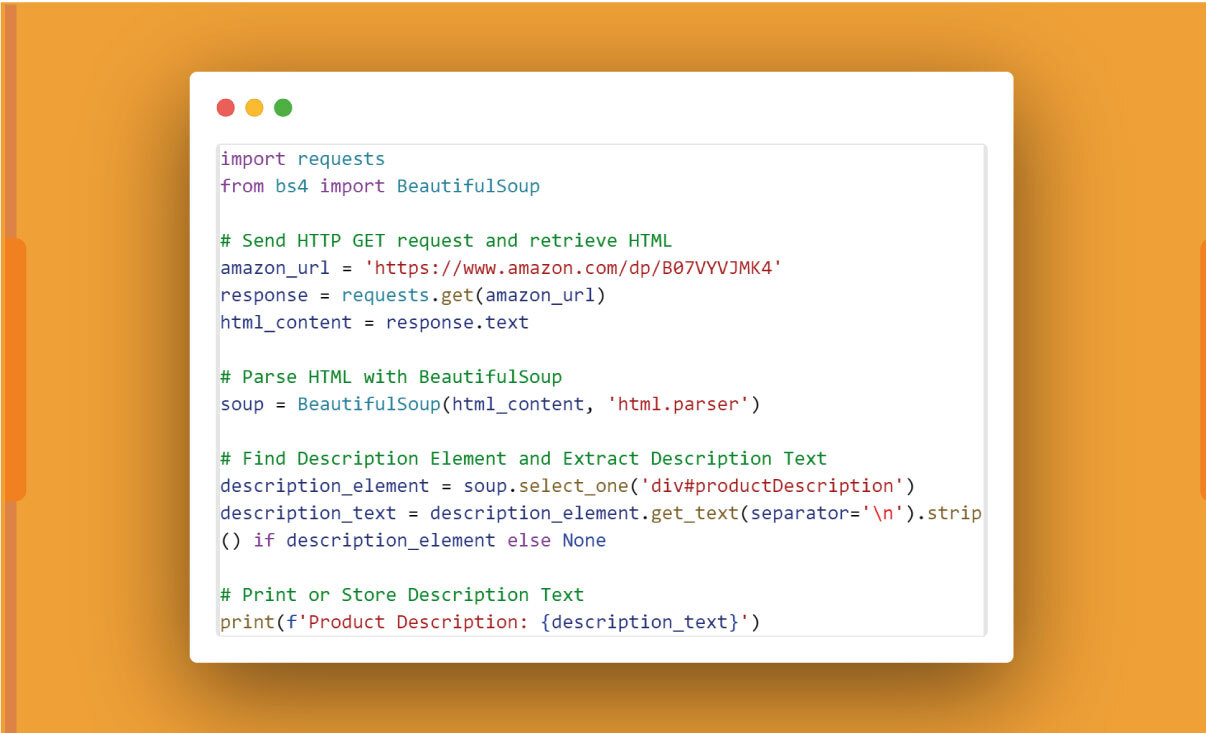
Adapt the code based on the specific HTML structure of the description element on the Amazon product page.
Product Price:
To extract the product price using Python and BeautifulSoup, follow these steps:
Identify Price Element:
Inspect the HTML structure of the product page using browser developer tools. Locate the price element, usually represented by a <span> or <div> tag with a specific class or identifier.
Find Price with BeautifulSoup:
Use BeautifulSoup methods to find the price element and extract the price text. For example:
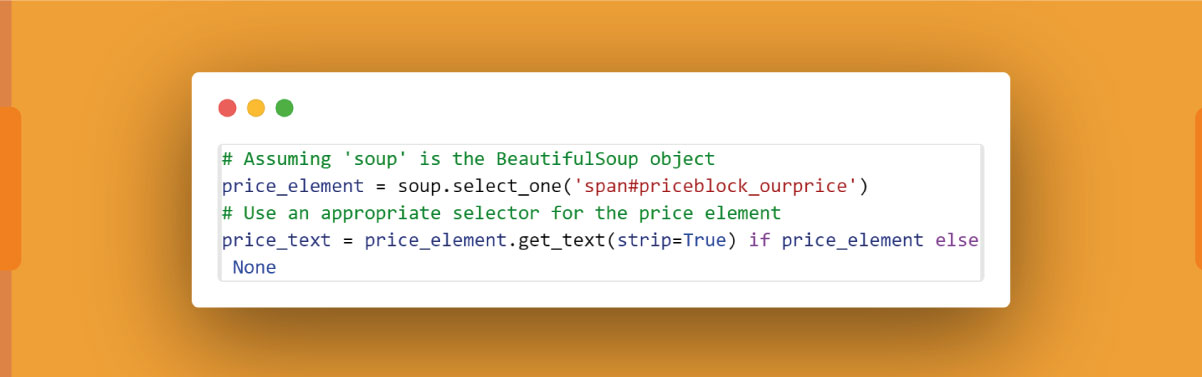
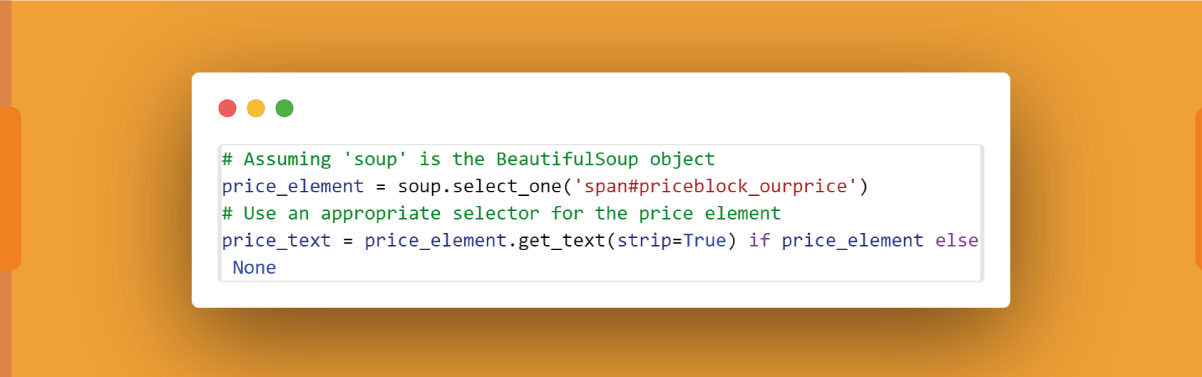
Here, 'span#priceblock_ourprice' is a sample CSS selector, and you should adapt it based on the actual HTML structure of the price element on the Amazon product page.
Clean and Convert Price:
Remove unnecessary characters (e.g., currency symbols) and convert the price text to a numerical value using appropriate functions. For example:
Print or Store the Price:
Print or store the cleaned and converted price as needed:
Ensure to check if the price element exists (if price_element) to avoid potential errors if the price is not found.
Here's an example using the BeautifulSoup code snippet:

Adapt the code based on the specific HTML structure of the price element on the Amazon product page.
Reviews and Rating:
To extract the average rating and the number of reviews from an Amazon product page using Python and BeautifulSoup, follow these steps:
Identify Rating and Reviews Elements:
Inspect the HTML structure of the product page using browser developer tools. Locate the elements representing the average rating and the number of reviews. Typically, these may be found within <span> or <div> tags with specific classes or identifiers.
Find Rating and Reviews with BeautifulSoup:
Use BeautifulSoup methods to find the rating and reviews elements and extract their text content. For example:

Adapt the CSS selectors based on the actual HTML structure of the rating and reviews elements on the Amazon product page.
Clean and Convert Values:
Clean and convert the extracted text values to appropriate data types. For example:

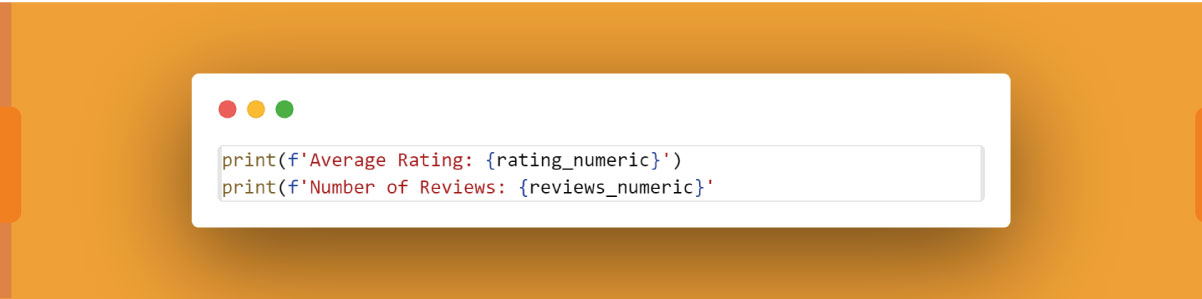
Print or Store the Values:
Print or store the cleaned and converted rating and reviews values as needed:
Ensure to check if the rating and reviews elements exist (if rating_element and if reviews_element) to avoid potential errors if they are not found.
Here's an example using the BeautifulSoup code snippet:

Adapt the code based on the specific HTML structure of the rating and reviews elements on the Amazon product page.
Complete Code with Data Storage:
Certainly! Below is a complete Python code snippet that includes scraping product details from an Amazon product page and storing the extracted data in a JSON file. The code utilizes the requests library for making HTTP requests, BeautifulSoup for HTML parsing, and json library for working with JSON data.

This code defines a function scrape_amazon_product(url) that performs all the scraping steps mentioned earlier. The extracted data is stored in a dictionary (product_data) and then written to a JSON file (amazon_product_data.json). Adjust the URL and data storage format as needed for your specific use case.
Creating a Crawler for Product Links:
Web crawlers are automated scripts that navigate through websites, systematically fetching and parsing web pages to extract data. In the context of scraping data from multiple product pages, a web crawler can be designed to traverse a website, collecting links to individual product pages, and then extracting data from each of those pages.
To extract product links from a search results page, similar techniques as scraping individual product pages can be applied:
Identify Link Elements:
Inspect the HTML structure of the search results page using browser developer tools. Locate the HTML elements (e.g., <a> tags) that contain links to individual product pages.
Use BeautifulSoup for Parsing:
Utilize BeautifulSoup, a Python library for HTML parsing, to extract the links. For example:
Adapt the CSS selector ('a', {'class': 's-title-instructions-placeholder'}) based on the specific HTML structure of the link elements on the search results page.
Clean and Filter Links:
Clean and filter the extracted links to ensure only valid product page URLs are included. You may use functions to check and filter based on specific criteria.
Store or Use the Links:
Store the extracted product links in a list for further processing or use them directly in your web crawler. You can then iterate through these links to visit each product page and scrape data.
Here's a simplified example of extracting product links from an Amazon search results page:

Remember to review the website's terms of service and policies to ensure compliance with ethical and legal considerations while using web crawlers.
Challenges of Amazon Scraping:
Scraping data from Amazon poses several challenges due to its dynamic structure and efforts to prevent automated data extraction. Some key challenges include:
Frequent Website Structure Changes:
Amazon regularly updates its website structure, making it challenging to maintain stable scraping scripts. Changes in HTML structure, class names, or element identifiers can break existing scrapers.
Solutions:
Regularly monitor and update scraping scripts to adapt to any structural changes.
Use more robust selectors like XPath to locate elements, as they are less prone to changes.
Consider utilizing the Amazon Product Advertising API, which provides a structured and stable interface for accessing product data.
Implementing Anti-scraping Measures:
Amazon employs anti-scraping measures to protect its data from automated extraction. These measures include CAPTCHAs, rate limiting, and IP blocking, making it challenging to scrape data efficiently.
Solutions:
Rotate user agents: Use a pool of user agents to mimic different browsers and devices.
Respect robots.txt: Adhere to the guidelines specified in Amazon's robots.txt file to avoid potential issues.
Implement delays: Introduce random delays between requests to avoid triggering rate limits. This helps in simulating human-like browsing behavior.
Use headless browsers: Mimic user interactions by employing headless browsers, which can handle JavaScript-rendered content and reduce the likelihood of encountering CAPTCHAs.
Proxy and IP Blocking:
Amazon may block IP addresses that exhibit suspicious behavior or excessive requests, hindering the scraping process.
Solutions:
Use rotating proxies: Rotate through a pool of proxies to distribute requests and reduce the likelihood of IP blocking.
Monitor IP health: Regularly check the health of proxies to ensure they are not blacklisted.
Utilize residential IPs: Residential IPs are less likely to be detected as a part of a scraping operation.
Legal and Ethical Considerations:
Scraping Amazon data without permission can violate Amazon's terms of service and potentially lead to legal consequences.
Solutions:
Review and adhere to Amazon's terms of service and policies.
Consider using official APIs if available, as they provide a sanctioned means of accessing data.
Opt for responsible scraping practices, respecting the website's limitations and guidelines.
Handling CAPTCHAs:
CAPTCHAs are a common anti-scraping measure that can interrupt automated scraping processes and require human interaction.
Solutions:
Implement CAPTCHA-solving services: Use third-party services to solve CAPTCHAs, but ensure compliance with legal and ethical standards.
Use headless browsers: Headless browsers can handle CAPTCHAs more effectively than traditional scraping approaches.
Navigating these challenges requires a combination of technical expertise, continuous monitoring, and adherence to ethical and legal standards. Employing best practices and staying informed about changes in the scraping landscape are essential for successful and sustainable Amazon scraping.
Amazon Data Collection Using Web Scraping API
Web scraping APIs serve as an alternative approach to manual scraping by providing a structured and programmatic way to access and extract data from websites. These APIs are designed to simplify the data extraction process, offering pre-defined endpoints and responses for retrieving specific information from a website.
Advantages of Using a Web Scraping API:
Structured Data Access:
APIs offer structured endpoints for accessing data, reducing the complexity of manual scraping code.
Data is provided in a consistent format, making it easier to integrate into applications and databases.
Reduced Maintenance:
API endpoints are more stable than HTML structures, reducing the need for frequent updates to scraping scripts due to website changes.
Faster Development:
APIs streamline the development process by providing a clear interface for data retrieval, saving time compared to manually parsing HTML.
Compliance with Website Policies:
Some websites encourage the use of their APIs for data access, ensuring compliance with terms of service and avoiding legal issues associated with unauthorized scraping.
Less Resource Intensive:
API requests are often less resource-intensive compared to loading entire web pages, resulting in faster and more efficient data extraction.
Disadvantages of Using a Web Scraping API:
Limited Data Access:
APIs may provide limited access to data compared to what is available through manual scraping, as they expose only specific endpoints defined by the website.
API Rate Limits:
Websites often impose rate limits on API requests to prevent abuse. This can slow down data extraction, especially for large-scale projects.
Authentication Requirements:
Some APIs require authentication, making it necessary to obtain and manage API keys, tokens, or credentials.
Costs:
While some APIs are free, others may have associated costs based on usage. High-volume data extraction could lead to increased expenses.
Dependence on Third-Party Providers:
Relying on third-party APIs introduces a dependency on the provider's reliability and availability. Changes or discontinuation of an API can impact data collection.
Conclusion
Web scraping serves as a robust method for extracting valuable data from Amazon product pages, empowering businesses with insights for activities such as price comparison and market research. However, the process comes with its challenges, including frequent website structural changes and anti-scraping measures.
Navigating these challenges requires adaptive strategies and adherence to ethical scraping practices, such as respecting website policies and implementing techniques like rotating user agents and introducing delays between requests.
For those seeking a structured and programmatic approach, web scraping APIs offer an alternative, providing advantages like structured data access and reduced maintenance. The Real Data API stands as a reliable solution for scraping Amazon product data, offering services for Amazon web scraping, ASINs data scraping, and access to Amazon API datasets, facilitating tasks like price comparison and market research.
As users engage in web scraping, it is crucial to uphold responsible practices, respecting legal considerations and contributing to the sustainability of the web data extraction ecosystem. Additional resources, tutorials, and guides can aid in further learning and exploration of web scraping and API integration. Explore the Real Data API for an efficient and ethical approach to Amazon data collection, ensuring reliable and compliant extraction for diverse needs.
Latest posts

How Companies Scrape Government Procurement Data for Competitive Market Analysis to Win More Contracts?

How AI Detects Market Trends Before Competitors and Helps Companies Gain a Strategic Edge?

How Combining AI and Web Scraping for Business Growth Helps Companies Gain a Competitive Advantage?

Enterprise Data Automation Strategies for Modern Businesses - Best Practices, Benefits, and Real-World Applications
Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.







Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7


Disclaimer : RealData API functions solely as an independent data infrastructure and technology solutions provider. We build customized automation workflows designed to collect publicly accessible web data based exclusively on client instructions. RealData API neither owns proprietary datasets nor engages in the sale or redistribution of extracted information. Our operations are limited strictly to lawful public web data processing and never involve unauthorized access to restricted systems or private networks. Any company names, trademarks, logos, or brand references displayed on this website are used purely for demonstrative and illustrative purposes to showcase our technical capabilities and do not imply endorsement, partnership, or affiliation. Use of our platform and services remains subject to our Terms of Service.