

Introduction
Unlocking the wealth of information embedded in various websites requires the adept skill of web scraping. This guide delves into the art and science of extracting data from any website. From understanding the fundamentals of HTML structure to implementing advanced scraping techniques, we navigate the nuances of this powerful tool. Whether you're a data enthusiast, researcher, or business professional, this guide aims to provide a comprehensive introduction, guiding you through the ethical, legal, and technical aspects of scraping data from diverse online sources. Discover the potential within your grasp and embark on a journey of informed data extraction.
What are the Reasons to Retrieve Data from a Webpage?
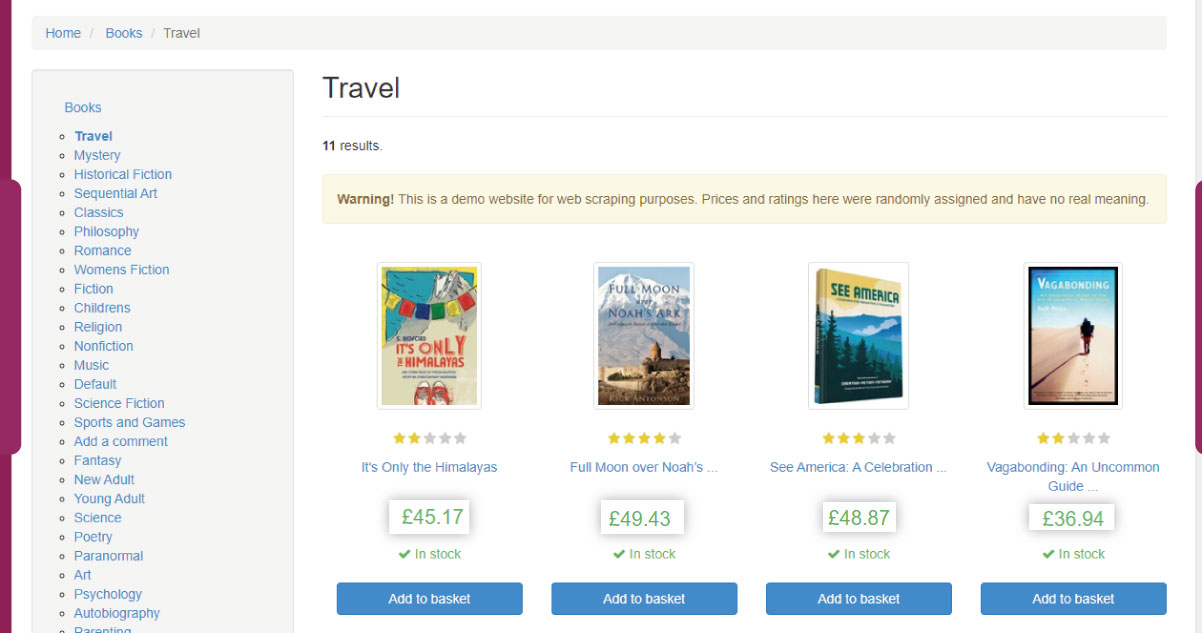
Retrieving data from a webpage serves various essential purposes across industries and applications. The motivations behind extracting data are diverse and include:
Market Research and Competitive Analysis
Web scraping allows businesses to gather insights into market trends, analyze competitors' strategies, and make informed decisions based on up-to-date information.
Price Monitoring and Comparison
Retailers and consumers can utilize web scraping to monitor product prices across different platforms, facilitating informed purchasing decisions.
Content Aggregation and Monitoring
News outlets and content aggregators extract data from multiple sources to provide users with a centralized information hub, ensuring comprehensive coverage.
Lead Generation
Sales and marketing professionals extract data from websites to generate leads, acquiring contact details and relevant information for potential clients.
Academic and Scientific Research
Researchers can collect data from websites to support academic studies, gather statistics, and analyze trends in various fields.
Financial Data Analysis
Analysts use web scraping to retrieve financial data, stock prices, and economic indicators, aiding investment decisions and market analysis.
Social Media Analytics
Companies and influencers leverage web scraping to analyze social media trends, monitor audience engagement, and refine content strategies.
Job Market Analysis
Job seekers and recruiters use web scraping to gather data on job postings, salary trends, and skill requirements, aiding in career decisions and talent acquisition.
Real Estate Market Insights
Real estate professionals extract data to analyze property prices, market trends, and the competitive landscape, guiding investment decisions.
Government and Public Data Access
Researchers and policymakers use web scraping to access publicly available data on government websites, supporting evidence-based decision-making.
While the reasons to retrieve data from a webpage are diverse and beneficial, it's crucial to approach web scraping ethically, respecting the websites' terms of service and complying with legal regulations to ensure responsible and lawful data extraction.
What is the Significance of Data?
Data is paramount in today's digital age, serving as the lifeblood of numerous industries and applications. Several vital aspects highlight the significance of data:
Informed Decision-Making
Data empowers individuals and organizations to make informed decisions by providing insights, trends, and patterns that drive strategic choices.
Business Intelligence
Businesses leverage data to gain competitive advantages, optimize operations, understand customer behavior, and refine marketing strategies.
Innovation and Research
Data fuels innovation as a foundation for research and development, enabling breakthroughs in science, technology, and various fields.
Personalization and User Experience
Companies use data to personalize user experiences, tailoring products, services, and content to individual preferences and needs.
Predictive Analytics
Predictive modeling and analytics utilize historical data to forecast future trends, helping businesses anticipate market shifts and consumer behavior.
Efficiency and Optimization
Data-driven insights enable organizations to optimize processes, streamline workflows, and enhance operational efficiency.
Healthcare Advancements
In the healthcare industry, data facilitates medical research, personalized treatment plans, and the development of innovative therapies.
Security and Fraud Prevention
Data is crucial for cybersecurity efforts, enabling the identification of anomalies and patterns that help prevent fraud and enhance digital security.
Educational Insights
Data supports academic research, helps educators tailor teaching methods, and facilitates personalized learning experiences in education.
Government Policy and Planning
Governments use data to inform policy decisions, allocate resources effectively, and address societal challenges based on evidence and insights.
Social and Economic Analysis
Data is essential for analyzing social and economic trends and supporting policymakers, researchers, and businesses in understanding broader societal dynamics.
Environmental Monitoring
Data plays a crucial role in environmental science, aiding in climate research, resource management, and monitoring ecological changes.
Data is a transformative asset that drives progress, innovation, and efficiency across various domains. As technology continues to evolve, the responsible and ethical use of data becomes increasingly vital for harnessing its full potential and addressing the challenges that come with its abundance.
What is Web Scraping?
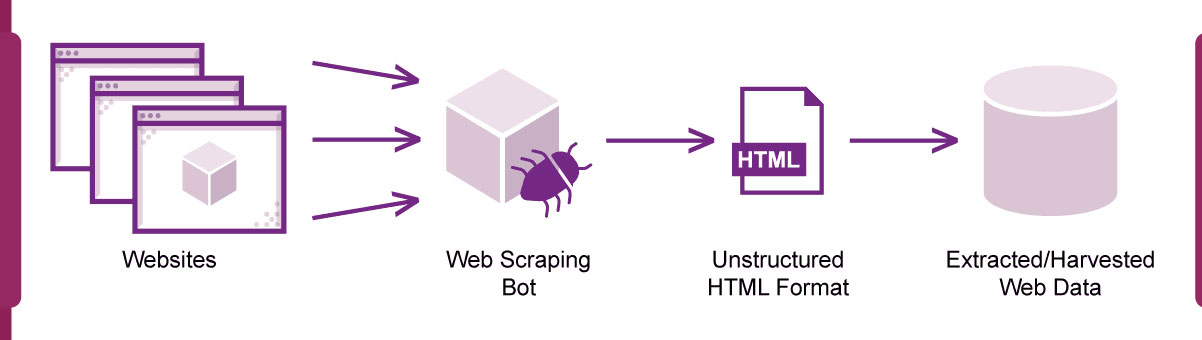
Web scraping is a technique to extract data from websites, converting unstructured web content into a structured and usable format. It involves automated retrieval of information from web pages, typically leveraging programming languages or specialized tools. The process begins by sending HTTP requests to the target website, simulating how a browser interacts. Once the data is fetched, parsing techniques extract specific elements such as text, images, or links.
Web scraping serves various purposes across industries, including market research, competitive analysis, and data aggregation. Businesses use it to track prices, monitor trends, and gather valuable insights. Researchers leverage web scraping for academic studies, while developers use it to build applications that require real-time data updates.
However, ethical considerations are paramount in web scraping. Adherence to website terms of service, respect for privacy policies, and compliance with legal regulations are essential to ensure responsible and lawful data extraction. As the digital landscape evolves, web scraping is a powerful tool, bridging the gap between unstructured web content and structured datasets for informed decision-making.
Step-by-Step Process for Extracting Data from a Product Page
Web scraping offers a powerful means to extract valuable data from product pages. Here's a concise step-by-step process to guide you through this extraction:
Identify Target Product Page
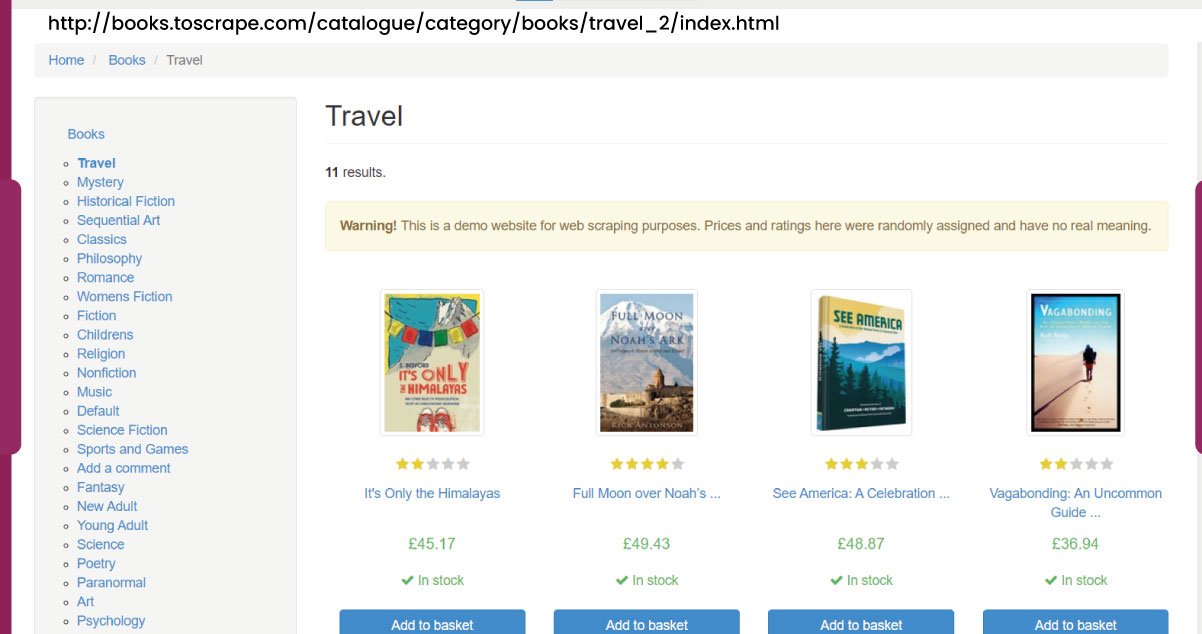
Choose the specific product page from which you intend to extract data. Ensure that your web scraping activities align with the website's terms of service.
Inspect Page Structure
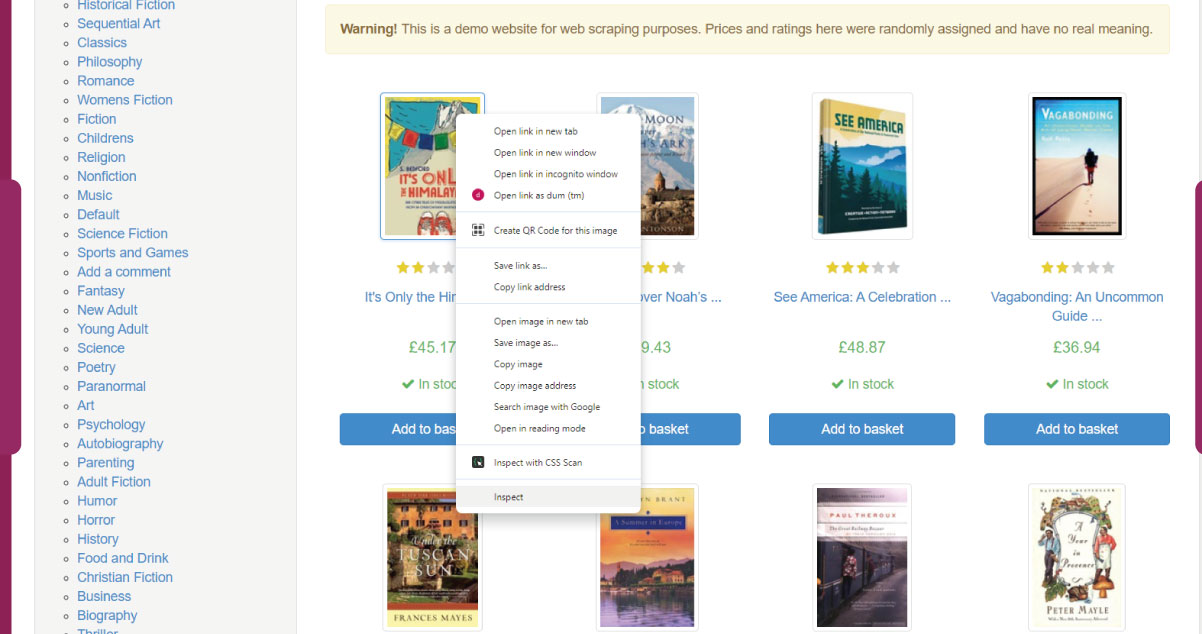
Use browser developer tools to inspect the HTML structure of the product page. Identify the HTML tags containing the relevant information such as product name, price, description, and images.
Create a Scraping Script
Develop a web scraping script using a programming language like Python. Utilize libraries such as BeautifulSoup or Scrapy to initiate HTTP requests, parse HTML, and extract data from the identified tags.
Initiate HTTP Request
Initiate an HTTP request to the product page's URL within your script. Capture the HTML content of the page for subsequent parsing.
Parse HTML Content
Use parsing techniques to navigate the HTML content and locate the target elements. Extract data from specific HTML tags based on your requirements.
Define Data Fields
Clearly define the data fields you intend to extract, such as product name, price, and description. Tailor your script to capture each field accurately.
Handle Pagination (if applicable)
If the product page spans multiple pages, incorporate pagination handling in your script to navigate the pages systematically.
Execute the Script
Run your scraping script, allowing it to fetch and extract data from the product page. Monitor the execution for any errors and refine the script as needed.
Run your scraping script, allowing it to fetch and extract data from the product page. Monitor the execution for any errors and refine the script as needed.
Save the extracted data in a structured format, such as CSV or JSON. This facilitates further analysis and integration into your desired applications.
Respect Ethical Considerations
Always adhere to ethical practices, respect the website's terms of service, and ensure compliance with legal regulations during data extraction.
By following these steps, you can effectively extract data from product pages, enabling you to harness valuable insights for market research, competitor analysis, and business decision-making.
What is the Importance of Utilizing a Sophisticated Proxy for Data Extraction?
Utilizing a sophisticated proxy is crucial for enhancing the effectiveness and ethicality of data extraction processes. An intelligent proxy is an intermediary between the user's system and the target website, offering several key advantages.
Firstly, a sophisticated proxy helps maintain anonymity by masking the user's IP address. This is essential for web scraping, as it prevents the risk of IP blocking or being flagged for suspicious activity by the target website. By rotating IP addresses intelligently, proxies enable a more discreet and sustainable data extraction operation.
Secondly, proxies enhance the scalability of data extraction. They allow users to distribute requests across multiple IP addresses, mitigating the risk of rate-limiting or being blocked due to excessive requests from a single source. This ensures a smoother and more efficient extraction process, especially when dealing with large datasets or frequent updates.
Lastly, the use of intelligent proxies contributes to ethical scraping practices. It helps users adhere to a website's terms of service by preventing server overload, reducing the likelihood of disruptions, and promoting responsible data extraction behavior. In summary, employing a sophisticated proxy is pivotal for achieving anonymity, scalability, and ethicality in data extraction, safeguarding the integrity of the process, and maintaining a respectful relationship with target websites.
Is it legal to Scrape Data from Websites?
The legality of scraping data from websites is a nuanced issue that depends on various factors, including the method used, the nature of the data, and compliance with relevant laws and regulations. While web scraping itself is not inherently illegal, problems arise when it infringes on the terms of service of a website or violates intellectual property rights.
Many websites explicitly prohibit scraping in their terms of service, considering it a breach of their policies. It may be deemed illegal if scraping involves accessing non-public data or circumventing technical barriers. Additionally, scraping personal or sensitive information without consent may violate privacy laws.
In the United States, the Computer Fraud and Abuse Act (CFAA) and the Digital Millennium Copyright Act (DMCA) have been invoked in legal actions against unauthorized scraping. In the European Union, the General Data Protection Regulation (GDPR) sets strict rules on collecting and processing personal data.
To navigate the legal landscape of web scraping, reviewing and adhering to a website's terms of service, privacy policies, and relevant laws is advisable. Engaging in responsible scraping practices, obtaining necessary permissions, and respecting the rights of website owners can help mitigate legal risks associated with data extraction. Always seek legal advice to understand the legal implications based on your specific use case and jurisdiction.
How Can One Scrape Data from a Website Completely Free?
One commonly used approach to extract data from a website for free is leveraging Python with the BeautifulSoup library for web scraping. Begin by installing Python and the BeautifulSoup library using the pip command. Create a Python script, import the necessary libraries (requests and BeautifulSoup), and request an HTTP to the target website. Utilize BeautifulSoup to parse the HTML content retrieved from the website.
Identify the specific HTML elements containing the data you wish to extract and use BeautifulSoup methods to retrieve them, for instance, extracting the title or finding all paragraphs on the page. Finally, print or store the extracted data as needed. Remember that while web scraping is a powerful tool, adhering to ethical guidelines and legal considerations is crucial. Continually review and respect the terms of service of the website you're scraping, and be aware that some sites may have restrictions on automated data extraction. This step-by-step process provides a foundational guide for extracting data from websites using Python and BeautifulSoup.
How can Real Data API Help You Scrape Data from Any Website?
Real Data API can play a pivotal role in facilitating data scraping from various websites by offering comprehensive and tailored solutions. Here's how Real Data API can assist in your data scraping endeavors:
Customized Scraping Approaches
Real Data API specializes in developing customized scraping methods based on the unique requirements of your project. This ensures precision and relevance in data extraction.
Ethical Data Practices
Real Data API prioritizes ethical considerations, promoting responsible data scraping practices that align with websites' terms of service and privacy policies. This helps in avoiding legal issues and maintaining a respectful approach.
Data Enrichment Services
Beyond mere scraping, Real Data API provides data enrichment services. This involves cleaning, organizing, and enhancing the extracted data, ensuring it is ready for insightful analysis.
API Integration Expertise
Real Data API is proficient in integrating APIs and facilitating structured and authorized access to website data. This approach ensures compliance with website guidelines and enhances the efficiency of data extraction.
Scalability and Performance
Real Data API offers scalable solutions optimized for performance and capable of efficiently handling large-scale data scraping requirements. This is crucial for projects involving extensive datasets or frequent updates.
Legal Compliance Assurance
Real Data API is committed to legal compliance. The team guides clients in navigating the intricate legal landscape of web scraping, ensuring the data extraction process adheres to relevant laws and regulations.
Transparent Operations
Transparency is a hallmark of Real Data API's operations. Clients can expect clear communication throughout the project about the data scraping process, potential challenges, and ethical considerations.
Custom Scraping Tools
Real Data API may develop custom scraping tools tailored to the specific needs of your project. This ensures that the scraping process is optimized for efficiency and accuracy.
By engaging with Real Data API, you can leverage their expertise to streamline the data scraping process, ensuring that your project is conducted ethically, efficiently, and in compliance with legal standards. Always consult with Real Data API to discuss the specific requirements of your data scraping project and explore how their services can best meet your needs.
Conclusion
Real Data API emerges as a reliable ally for those seeking to navigate the intricacies of data scraping from diverse websites. With a commitment to ethical practices, customized scraping approaches, and a focus on legal compliance, Real Data API ensures that data extraction is efficient and scalable and conducted with utmost responsibility. Integrating API expertise, transparent operations, and data enrichment services further solidifies Real Data API's position as a comprehensive solution provider. For those embarking on data scraping endeavors, Real Data API stands as a trusted partner, offering tailored and ethical solutions for extracting valuable insights from the digital landscape.
Latest posts
Why Brands Use Competitive Data Intelligence to Increase Market Share in Highly Competitive Markets?

How To Scrape Competitor Data To Support Market Entry Strategy And Expansion Planning For Data-Driven Business Growth?

How Hotel Occupancy Intelligence Through Public Data Sources Is Reshaping Revenue Management

The ZIP Code Advantage: How Hyper-Local Amazon Product Data Collection Is Redefining Retail Intelligence
Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.







Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7


Disclaimer : RealData API functions solely as an independent data infrastructure and technology solutions provider. We build customized automation workflows designed to collect publicly accessible web data based exclusively on client instructions. RealData API neither owns proprietary datasets nor engages in the sale or redistribution of extracted information. Our operations are limited strictly to lawful public web data processing and never involve unauthorized access to restricted systems or private networks. Any company names, trademarks, logos, or brand references displayed on this website are used purely for demonstrative and illustrative purposes to showcase our technical capabilities and do not imply endorsement, partnership, or affiliation. Use of our platform and services remains subject to our Terms of Service.