

Introduction
Twitter data is crucial in diverse fields, offering valuable insights for research, business, and societal trends. In market research, companies utilize Twitter data to understand consumer sentiments, preferences, and emerging trends, enabling informed decision-making and targeted marketing strategies. For price comparison, real-time updates on product prices and user reviews on Twitter contribute to competitive market analysis.
Web scraping, a technique to extract data from websites, is instrumental in harnessing Twitter data. A Twitter data scraper automates extracting information from tweets, profiles, and hashtags, facilitating efficient data collection. This method proves indispensable for researchers aiming to analyze public opinion on various subjects, track trends, and monitor reactions to events.
Extracting Twitter data through web scraping is pivotal in market research, price comparison, and various analytical pursuits. By employing Twitter data collection tools, businesses and researchers gain a competitive edge by staying abreast of market dynamics and consumer sentiments, fostering informed decision-making.
Understanding the Basics
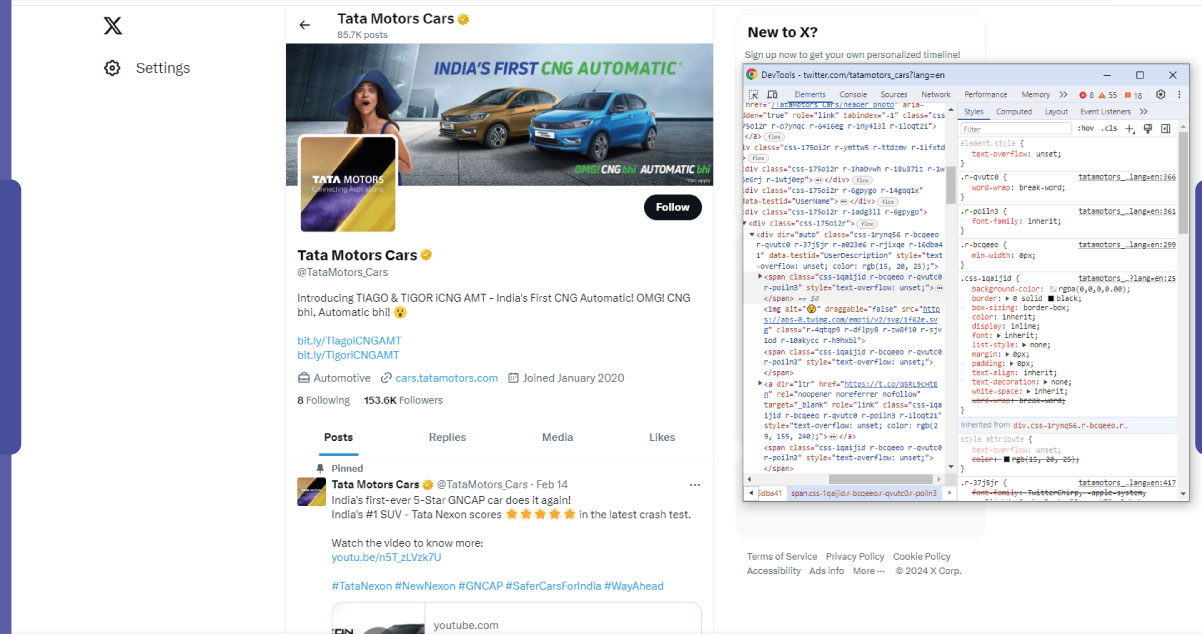
Twitter's API (Application Programming Interface) is a gateway for developers to access and retrieve data from the platform. While it provides a structured and authorized way to collect Twitter data, its limitations impact extensive data extraction. Twitter API limitations include rate restrictions, which limit the number of requests per 15-minute window, and access to only the past seven days of historical tweets through standard endpoints.
To overcome these limitations, web scraping emerges as a viable alternative for collecting Twitter data. Web scraping involves automated data extraction from web pages, allowing for more flexible and extensive information retrieval. A Twitter data scraper employed in web scraping enables users to extract tweets, user profiles, and related data beyond the constraints of the API.
Web scraping becomes an invaluable tool for tasks like price comparison and market research, where real-time and historical data are crucial. It offers the freedom to customize data extraction processes and gather comprehensive insights from Twitter, complementing or surpassing the capabilities of the Twitter API in specific scenarios.
Setting Up Your Environment

To begin scraping data from Twitter or working with its API, you need to set up the necessary tools. Here's a guide to installing Python, a web scraping library (Beautiful Soup or Scrapy), and obtaining Twitter API keys for authentication.
Install Python
- Visit the official Python website and download the latest version.
- During installation, ensure you check the box that says "Add Python to PATH" for easy accessibility.
- Verify the installation by opening a command prompt or terminal and typing python --version.
Install a Web Scraping Library
- For Beautiful Soup:
pip install beautifulsoup4
- For Scrapy:
pip install scrapy
Twitter API Keys:
- If you plan to use the Twitter API, create a Twitter Developer account and set up a new application.
- Once your application is created, go to the "Keys and tokens" tab to obtain your API key, API secret key, Access token, and Access token secret.
- These keys are crucial for authenticating your requests to the Twitter API.
Create a Twitter Data Scraper:
- For Beautiful Soup:
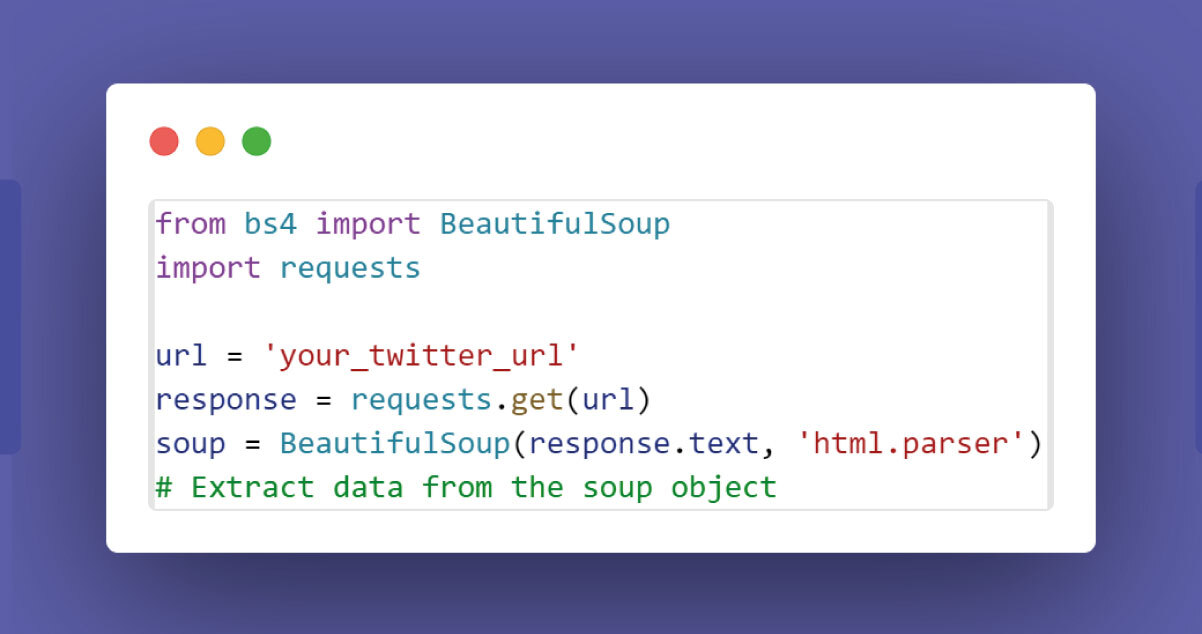
- For Scrapy:

Remember to respect Twitter's terms of service and API usage policies while scraping data. Additionally, handle API keys securely to prevent unauthorized access. This guide sets the foundation for extracting Twitter data for tasks like price comparison and market research.
Choosing the Right Tools
Several web scraping tools and frameworks are suitable for Twitter data extraction, each with its own set of pros and cons. Here's a comparison focusing on factors such as ease of use and scalability:
Beautiful Soup:
Pros:
- Simple and easy to learn, making it ideal for small to medium-scale projects.
- Well-suited for parsing HTML and XML structures.
Cons:
- Limited in terms of scalability for large-scale or complex scraping tasks.
- Requires additional libraries for making HTTP requests.
Scrapy:
Pros:
- A powerful and extensible framework for large-scale web scraping.
- Built-in support for handling requests, following links, and handling common web scraping tasks.
Cons:
- Steeper learning curve compared to Beautiful Soup.
- May be overkill for small projects.
Selenium:
Pros:
- Ideal for scraping dynamic websites, including those with JavaScript-based content (common on Twitter).
- Provides browser automation capabilities.
Cons:
- Slower compared to Beautiful Soup or Scrapy.
- Requires a web browser to be opened, which may not be suitable for headless or server-based scraping.
Tweepy (Twitter API Wrapper):
Pros:
- Specifically designed for interacting with the Twitter API, offering direct access to Twitter data.
- Provides a Pythonic interface for easy integration into Python applications.
Cons:
- Limited to Twitter API constraints, such as rate limits and historical data access.
- May not be suitable for extensive scraping beyond API limitations.
Octoparse:
Pros:
- A user-friendly, visual scraping tool suitable for beginners.
- Offers point-and-click functionality for creating scraping workflows.
Cons:
- Limited flexibility compared to coding-based frameworks.
- Less suitable for complex or customized scraping tasks.
Choosing the right tool depends on the specific requirements of your Twitter data extraction project. Beautiful Soup and Scrapy are powerful for general web scraping, while Tweepy is specialized for Twitter API access. Selenium and Octoparse cater to users who prefer visual, point-and-click interfaces. Consider the scale, complexity, and your familiarity with the tools when making a choice for tasks like price comparison and market research.
Navigating Twitter's Structure
To effectively scrape data from Twitter, it's crucial to understand the HTML structure and identify relevant elements. Keep in mind that web scraping should be done responsibly and in compliance with Twitter's terms of service. Here's an overview of the HTML structure and key elements for scraping tweets, user profiles, and timelines:
Tweets:
- Each tweet is typically contained within a element with a class like tweet or js-stream-tweet.
- The tweet text can be found within a nested
or element with a class such as tweet-text.
- User mentions, hashtags, and links within the tweet are often encapsulated in specific (anchor) elements.
User Profiles:
- The user profile information is commonly found within a element with a class like ProfileHeaderCard.
- Usernames and handles are often located in a or element with a class like username or ProfileHeaderCard-screenname.
- Bio information, follower count, and following count can be extracted from specific
or elements.
Timelines:
- The timeline or feed typically consists of a series of tweets arranged within a container, often a with a class like stream or stream-items.
- Individual tweets within the timeline can be identified using their respective tweet containers.
- Scrolling through the timeline may involve interacting with dynamic elements, such as buttons or infinite scroll features, which can be triggered through scripting.
Images and Media:
- Media elements like images and videos within tweets are commonly embedded within or elements with classes like AdaptiveMedia-container.
- Image URLs or video links can be extracted from the corresponding HTML attributes.
Understanding the HTML structure of Twitter pages allows you to navigate and target specific elements for scraping. It's important to note that Twitter may periodically update its website structure, so scraping code might need adjustments accordingly. Additionally, be mindful of Twitter's terms of service and rate limits to ensure responsible and ethical data collection, especially for market research and price comparison activities.
Crafting Your Web Scraping Script
Writing a Python script for web scraping Twitter data involves several steps, including authentication, sending requests, and parsing HTML content. Below is a simple step-by-step guide using the requests library for sending HTTP requests and BeautifulSoup for HTML parsing. Remember to abide by Twitter's terms of service and avoid violating any rules during scraping.

This example assumes you want to scrape tweets from a specific Twitter user's page. Make sure to replace 'https://twitter.com/TwitterUsername' with the actual Twitter URL you want to scrape.
Note: Twitter may use dynamic loading or AJAX to load more content as you scroll down the page. In such cases, you might need to use additional techniques, like inspecting network requests in your browser's developer tools to understand how data is loaded and adapt your script accordingly.
Additionally, for large-scale scraping, consider incorporating rate limiting and error handling to ensure responsible and ethical scraping practices. Always be aware of Twitter's terms of service and scraping guidelines.
Handling Rate Limits and Ethical Scraping
Twitter imposes rate limits on API requests to prevent abuse and ensure fair usage. These limits apply to the number of requests a user or application can make within specific time intervals. Adhering to these limits is crucial to avoid API restrictions and maintain ethical scraping practices. Here's an explanation of Twitter's rate limits and how to handle them responsibly:
Rate Limits:
- Twitter API has different rate limits for various endpoints, such as Tweets, Users, and Search.
- Rate limits are typically defined as a certain number of requests allowed within a 15-minute window, with different limits for authenticated and unauthenticated requests.
- Exceeding these limits can result in temporary restrictions, preventing further API access.
Handling Rate Limits:
- Monitor the rate limit headers in API responses, such as x-rate-limit-limit (maximum requests allowed), x-rate-limit-remaining (remaining requests), and x-rate-limit-reset (time when the limits will reset).
- Implement rate limit checking in your scraping script to pause or adjust the request frequency when approaching the limit.
- Use backoff strategies: If you hit the rate limit, wait for the specified reset time before making additional requests.
- Utilize Twitter's streaming API for real-time updates instead of polling endpoints repeatedly.
Ethical Scraping Practices:
- Respect Twitter's Robots.txt file, which outlines rules for web crawlers. Ensure your scraping activities comply with these rules.
- Review and adhere to Twitter's Developer Agreement and Policy and Automation Rules.
- Prioritize user privacy by avoiding the collection of personally identifiable information without explicit consent.
- Do not engage in aggressive or disruptive scraping that may impact the user experience on Twitter.
User Consent:
- When applicable, consider obtaining user consent before scraping or collecting data related to specific users.
- Inform users about your data collection practices and how their information will be used.
Adhering to these guidelines is crucial for responsible and ethical scraping practices. Violating Twitter's terms of service or engaging in unethical scraping can lead to API access restrictions, legal consequences, and damage to your reputation. When conducting activities like price comparison and market research, it's essential to prioritize responsible data collection and respect the rules set by the platform.
Conclusion
Scraping Twitter data involves key steps to responsibly gather valuable insights. Begin by installing Python libraries like requests and BeautifulSoup. Set up your Twitter URL, send a GET request, and parse HTML content to extract specific data points, such as tweets, user profiles, and hashtags. Adhere to Twitter's rate limits, ensuring ethical scraping practices and compliance with their terms of service. Respect user privacy and consider obtaining consent for data collection. Filter and refine extracted data based on your needs, using conditional statements.
As you explore Twitter data, it's essential to leverage it responsibly for various purposes, such as market research or price comparison. The acquired insights can inform business strategies, enhance decision-making, and understand user sentiments. However, users must be aware of ethical considerations and legal implications associated with web scraping. It's crucial to stay informed about Twitter's policies, ensuring that your scraping activities align with their guidelines.
For a seamless experience and richer insights, consider exploring Real Data API, a powerful tool for extracting and utilizing Twitter data. Embrace the opportunities it offers, keeping in mind the ethical framework and legal responsibilities associated with data extraction from online platforms.
Latest posts

How to scrape GeM procurement analytics data for manufacturers to Unlock Smarter Government Contract Opportunities?

The future of Data-as-a-Service in 2026 - Trends, Innovations, and Business Opportunities

How To Use AI Agents For Automated Data Collection and Analysis to Improve Business Intelligence And Decision-Making
How to Scrape Dynamic pricing strategies powered by travel data for Smarter Travel Pricing and Revenue Optimization
 Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.
Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.





.png)


Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7
Disclaimer : RealData API functions solely as an independent data infrastructure and technology solutions provider. We build customized automation workflows designed to collect publicly accessible web data based exclusively on client instructions. RealData API neither owns proprietary datasets nor engages in the sale or redistribution of extracted information. Our operations are limited strictly to lawful public web data processing and never involve unauthorized access to restricted systems or private networks. Any company names, trademarks, logos, or brand references displayed on this website are used purely for demonstrative and illustrative purposes to showcase our technical capabilities and do not imply endorsement, partnership, or affiliation. Use of our platform and services remains subject to our Terms of Service.
- The tweet text can be found within a nested

