

Introduction
In the intricate realm of data acquisition from the vast internet landscape, web scraping emerges as a pivotal technique, facilitating the extraction of valuable information from websites. This method, crucial in data science, research, and business intelligence, empowers users to collect, analyze, and interpret data efficiently.
Two prominent tools that have gained widespread recognition in the web scraping domain are Cheerio and Puppeteer. Both are instrumental in navigating the complexities of the web, yet they diverge in their approaches and capabilities. Understanding the nuances of these tools becomes imperative, as the choice between Cheerio and Puppeteer profoundly influences the success of a scraping project.
This exploration delves into the core concepts of web scraping, shedding light on its significance in the data extraction landscape. It serves as a gateway to Cheerio and Puppeteer, unraveling their functionalities, use cases, and comparative advantages. As we embark on this journey, the importance lies in selecting the right tool. This decision hinges on each unique scraping endeavor's specific requirements and intricacies. Let's navigate this comprehensive guide to discern the intricacies of Cheerio and Puppeteer, ultimately empowering you to make informed choices in your web scraping pursuits.
Understanding Cheerio
Introduction to Cheerio
At the forefront of the web scraping arsenal, Cheerio emerges as a lightweight and agile HTML parser designed to navigate and manipulate HTML and XML documents effortlessly. In the expansive world of data extraction, where speed and efficiency are paramount, Cheerio stands out as a versatile tool capable of swiftly parsing static content with finesse.
Lightweight and Fast HTML Parser
Cheerio's distinction lies in its featherlight nature, making it exceptionally fast and resource-efficient. As a dedicated HTML parser, it excels in swiftly traversing documents, extracting pertinent information, and easily manipulating the Document Object Model (DOM). This agility makes Cheerio particularly suitable for projects where speed is of the essence.
Compatibility with Node.js for Server-Side Scraping
What adds to Cheerio's allure is its seamless integration with Node.js, a runtime environment that enables server-side JavaScript execution. This compatibility empowers developers to harness Cheerio's parsing prowess in server-side scraping scenarios. Whether extracting data for backend processes, automating tasks, or conducting server-side analysis, Cheerio is a reliable companion in the Node.js ecosystem.
In the landscape of web scraping, where efficiency meets versatility, Cheerio emerges as a handy and proficient HTML parsing tool. Its compatibility with Node.js further amplifies its utility, offering a streamlined approach to server-side scraping endeavors. Cheerio's significance becomes increasingly apparent as we journey deeper into web scraping tools, laying the groundwork for a nuanced understanding of its capabilities and applications.
Use Cases for Cheerio
In the intricate tapestry of web scraping tools, Cheerio finds its forte in scenarios where precision, speed, and simplicity are paramount. Here are some critical use cases where Cheerio emerges as an optimal choice:
1. Parsing Static HTML Content
Scenario: Cheerio excels in scenarios where the web content is predominantly static, devoid of dynamic elements loaded through JavaScript.
Example: Extracting information from a static product catalog page, where the HTML structure remains constant, and real-time updates are not a primary consideration.
2. Data Extraction for Reporting
Scenario: When the objective is to gather data for reporting purposes, and the target website's structure remains consistent over time.
Example: Scraping financial data from a news website's static pages to generate daily or weekly reports on market trends and stock prices.
3. Content Aggregation for Blogs or News Sites
Scenario: Ideal for projects that aggregate content from static pages of blogs or news websites.
Example: Extracting headlines, article content, and publication dates from static news articles for creating a curated feed.
4. SEO Analysis and Keyword Extraction
Scenario: Cheerio is a valuable asset for static content analysis, making it suitable for SEO-related tasks.
Example: Scraping meta tags, headers, and keyword frequency from static pages to analyze and optimize a website's SEO performance.
5. Automated Data Validation
Scenario: Well-suited for scenarios where periodic validation of static content is required.
Example: Automating the verification of product prices on an e-commerce site to ensure consistency and accuracy.
6. Extracting Structured Data from Documentation
Scenario: Valuable for extracting structured data from static documentation or technical manuals.
Example: Parsing HTML documentation pages to extract code snippets, function references, or technical specifications for knowledge-sharing platforms.
Cheerio's strength lies in its ability to handle scenarios where the web content is predominantly static efficiently. Its lightweight nature and seamless integration with Node.js make it an excellent choice for targeted scraping projects, particularly those focused on precision and simplicity. Cheerio's versatility becomes increasingly evident as we explore its applications in these use cases, laying the foundation for its role in the web scraping toolkit.
Cheerio Features and Syntax
Cheerio is a fast, flexible, and lightweight HTML parsing library for Node.js. It provides a simple API for traversing and manipulating the HTML Document Object Model (DOM) similar to jQuery.
Installation
To use Cheerio, you need to install it using npm (Node Package Manager):
npm install cheerioLoading HTML
Load an HTML document using Cheerio:

Selectors
Cheerio supports a wide range of selectors similar to jQuery for selecting and manipulating elements:

Traversing
Traverse the DOM using Cheerio:

Manipulating the DOM
Change the content and attributes of HTML elements:

Cheerio and AJAX
Cheerio can be used to scrape data from web pages. For example, fetching data from a website using Axios and then using Cheerio for parsing:

Cheerio simplifies HTML parsing and manipulation in Node.js, making it easy to work with HTML documents. Its syntax is similar to jQuery, making it a familiar tool for those who have experience with client-side web development. The combination of selectors, traversing, and manipulation features makes Cheerio a powerful tool for web scraping and data extraction tasks in a Node.js environment.
Understanding Puppeteer
Introduction to Puppeteer
What is Puppeteer?
Puppeteer is a powerful Node.js library developed by Google that provides a high-level API to control headless browsers (browsers without a graphical user interface). It's commonly used for automating tasks such as web scraping, taking screenshots, generating PDFs, and performing automated testing of web pages.
Capabilities of Puppeteer
Headless Browsing
Puppeteer allows developers to perform browser automation in a headless mode, meaning the browser operates without a visible UI. This is particularly useful for tasks that don't require user interaction, improving efficiency.
Rendering Dynamic Content
Puppeteer excels in rendering dynamic content. It can navigate through pages, interact with elements, and capture screenshots of fully rendered pages, even those relying on JavaScript to load content dynamically.
Page Interaction
Puppeteer enables interaction with web pages by allowing the automation of clicks, form submissions, and keyboard input. This makes it a valuable tool for testing user interactions and workflows.
Network Request Handling
Developers can use Puppeteer to intercept and modify network requests, enabling scenarios like network mocking for testing purposes or monitoring network activity during automation.
Screenshots and PDF Generation
Puppeteer simplifies the process of taking screenshots and generating PDFs of web pages. This can be useful for generating reports, visual documentation, or capturing the state of a web page at a specific moment.
Sample Code Snippet
Here's a basic example of using Puppeteer to take a screenshot of a web page:

In this example, Puppeteer is used to launch a headless browser, navigate to a webpage, and capture a screenshot, demonstrating its simplicity and power.
Puppeteer stands out as a versatile tool for automating browser tasks in headless mode. Its capabilities make it an excellent choice for various applications, from web scraping to automated testing, providing developers with a robust and efficient way to interact with and manipulate web pages programmatically.
Use Cases for Puppeteer
Web Scraping
Puppeteer excels in web scraping tasks, especially when dealing with websites that heavily rely on JavaScript to load and render content dynamically. Its ability to interact with the DOM and capture screenshots aids in efficiently extracting data from various types of websites.
Example: Automating the extraction of product details, prices, and reviews from an e-commerce site with dynamic content.
Automated Testing
Puppeteer is widely used for end-to-end testing and regression testing of web applications. Its capability to interact with pages, simulate user interactions, and capture screenshots simplifies the testing process.
Example: Running automated tests to ensure that a login page functions correctly by simulating user login scenarios and capturing screenshots for visual validation.
Screenshots and PDF Generation
Puppeteer's ability to capture screenshots and generate PDFs is handy for creating visual documentation, reports, or archiving the state of web pages at specific points in time.
Example: Generating automated reports that include visual representations of charts and graphs from a data analytics dashboard.
Performance Monitoring
Puppeteer can be used to measure and monitor the performance of web pages. It allows developers to capture performance metrics, analyze network activity, and identify potential bottlenecks.
Example: Analyzing the load times of various assets on a web page to optimize performance and improve the user experience.
Form Submissions and Automation
Puppeteer enables the automation of form submissions on websites. This is valuable for scenarios where repetitive tasks involve filling out forms, submitting data, and capturing the results.
Example: Automating the submission of contact forms on a website to streamline the process of reaching out to customer support.
SEO Testing
Puppeteer can be utilized to render and analyze pages as search engines do, helping to ensure that content is properly indexed and displayed in search results.
Example: Verifying how a webpage appears in search engine results by capturing screenshots after rendering with Puppeteer.
Puppeteer's versatility makes it a valuable tool in various scenarios, from data extraction to testing and performance monitoring. Its ability to navigate complex websites, interact with dynamic content, and automate tasks involving forms and user interactions positions Puppeteer as a powerful solution for web automation in diverse real-world applications.
Puppeteer Features and Syntax
Browser Automation
Puppeteer allows for full control over a headless browser or a browser instance. It provides methods to navigate to pages, interact with elements, and execute scripts, enabling comprehensive browser automation.

Taking Screenshots
Capture screenshots of web pages with Puppeteer, offering a visual representation of the rendered page at a specific point in time.

Generating PDFs
Puppeteer simplifies the process of generating PDFs from web pages, providing options for customization.

Interacting with Elements
Puppeteer allows interactions with DOM elements, such as clicking buttons, filling forms, and capturing input values.

Comparative Analysis
Puppeteer vs. Other Automation Tools
Puppeteer stands out for its integration with the Chrome browser, providing a powerful headless browsing experience. While other tools may offer similar features, Puppeteer's close ties to the Chromium project make it well-suited for tasks involving complex JavaScript and dynamic content.
Syntax Simplicity
Puppeteer's syntax is concise and resembles standard JavaScript, making it accessible to developers familiar with the language. This simplicity contributes to a quick learning curve, allowing developers to leverage its features efficiently.
Performance
Puppeteer is known for its speed and efficiency in browser automation. Its headless mode ensures that tasks run without a graphical interface, optimizing resource usage and allowing for faster execution compared to tools that require a visible browser window.
Community Support
Puppeteer benefits from a robust community and ongoing development by Google. This ensures regular updates, bug fixes, and a wealth of resources for developers. The community-driven nature of Puppeteer fosters a collaborative environment for sharing insights and addressing challenges.
Use Cases
Puppeteer is versatile and widely used for various applications, including web scraping, automated testing, performance monitoring, and generating visual reports. Its flexibility and broad range of features make it suitable for a diverse set of tasks.
Puppeteer's combination of features, simplicity in syntax, and strong community support position it as a leading choice for headless browser automation, particularly in scenarios involving dynamic content, JavaScript execution, and tasks such as taking screenshots or generating PDFs. Its performance and integration with Chrome make it a valuable tool for developers seeking efficient and reliable automation solutions.
Performance Comparison
Cheerio
Speed: Cheerio is a fast and lightweight HTML parsing library. It's designed for server-side DOM manipulation, making it efficient for extracting data from static HTML content.
Resource Usage: Cheerio operates on the server side and does not open a browser. It's memory-efficient and performs well when dealing with static HTML content.
Puppeteer
Speed: Puppeteer is designed for browser automation and can be slower than Cheerio when parsing static HTML. However, it excels in scenarios involving dynamic content and interactions.
Resource Usage: Puppeteer opens a headless browser instance, which consumes more resources than Cheerio. The additional overhead is justified when dealing with dynamic websites that heavily rely on JavaScript.
Scenarios where one tool might outperform the other:
Static HTML Parsing
Cheerio Advantage: Cheerio is more suitable if the task involves parsing static HTML content without the need for browser automation or interaction with dynamic elements. Its lightweight nature ensures faster parsing of static documents.
Dynamic Web Scraping
Puppeteer Advantage: When web scraping requires interaction with dynamic content, such as clicking buttons, filling forms, or capturing dynamically loaded data, Puppeteer's browser automation capabilities become invaluable. Cheerio cannot execute JavaScript and interact with dynamic content.
Resource Efficiency
Cheerio Advantage: Cheerio's lightweight design makes it a more efficient choice for scenarios where resource usage is a critical factor, such as in environments with limited memory or when processing large volumes of static HTML data.
Testing and Automation
Puppeteer Advantage: When the goal is to automate browser-based testing, performance monitoring, or any scenario that involves simulating user interactions on a website, Puppeteer's ability to control a headless browser provides the necessary capabilities.
Data Extraction from Web Pages
Cheerio Advantage: If the primary objective is to extract data from static web pages without dynamic interactions, Cheerio's simplicity and speed make it a straightforward choice.
The choice between Cheerio and Puppeteer depends on the specific requirements of the task at hand. Cheerio is ideal for quickly and efficiently parsing static HTML content, especially in resource-constrained environments. On the other hand, Puppeteer shines in scenarios that involve dynamic web scraping, browser automation, and tasks that require interaction with JavaScript-heavy websites. Consideration of the project's goals, resource constraints, and the nature of the target web pages will guide the selection of the most appropriate tool for the job.
Scalability and Complexity
Scalability
Cheerio
Advantages
Cheerio is highly scalable for projects involving static HTML content. Its lightweight nature makes it suitable for parsing and extracting data from many static web pages.
Since Cheerio operates on the server side and doesn't involve the overhead of opening a browser, it can efficiently handle a high volume of requests concurrently.
Considerations
While Cheerio is scalable for static HTML parsing, it may face limitations when dealing with dynamic content or scenarios that require browser interactions.
Puppeteer
Advantages
Puppeteer's scalability shines in projects that involve browser automation and dynamic web scraping. It can efficiently handle large-scale scraping tasks requiring interaction with JavaScript-driven content.
Puppeteer supports features like parallelism and asynchronous execution, enabling concurrent processing of multiple pages.
Considerations
Opening a headless browser for each task incurs additional resource overhead. While Puppeteer is powerful, scaling horizontally (using multiple instances) may be necessary for extremely high loads.
Complexity
Cheerio
Advantages
Cheerio is known for its simplicity. It operates on the familiar jQuery-like syntax, making it easy for developers to pick up and use quickly.
Cheerio projects are often less complex, especially with static HTML parsing tasks. The straightforward API reduces the learning curve.
Considerations
Cheerio's simplicity might become a limitation when dealing with complex scenarios requiring dynamic content interaction, as it needs a browser environment.
Puppeteer
Advantages
Puppeteer provides a comprehensive set of features for browser automation and dynamic web scraping. Its powerful and flexible capabilities cater to a wide range of complex scenarios.
Puppeteer's API allows for fine-grained control over the browser, making it suitable for intricate tasks.
Considerations
The comprehensive feature set of Puppeteer introduces a steeper learning curve compared to Cheerio. Developers must be familiar with asynchronous JavaScript, promises, and browser concepts.
Conclusion
Scalability: Choose Cheerio for large-scale projects involving static HTML parsing and data extraction.
Opt for Puppeteer when scalability involves browser automation, dynamic content, and JavaScript-driven interactions.
Complexity: Cheerio is preferred for simple projects and tasks requiring basic HTML parsing.
Puppeteer is the choice for more complex projects, especially those involving browser automation, interaction with dynamic content, and advanced scenarios.
The selection between Cheerio and Puppeteer should align with the specific requirements and complexity of the scraping project. While Cheerio excels in simplicity and efficiency for static content, Puppeteer's scalability and feature-rich browser automation make it the go-to choice for dynamic and complex web scraping scenarios.
Handling JavaScript-Heavy Sites
Cheerio
How it Handles JavaScript
Cheerio is a server-side library and doesn't execute JavaScript. It parses static HTML content but doesn't interpret or run scripts.
Cheerio alone may not capture dynamically loaded content if a website relies heavily on client-side rendering through JavaScript.
Challenges
Limited capability to handle JavaScript-dependent rendering or dynamic updates on the client side.
It may not be suitable for scraping content loaded or modified by JavaScript after the initial page load.
Advantages
Speed and efficiency in parsing static HTML, making it well-suited for sites with minimal JavaScript interaction.
Lightweight and resource-efficient for tasks not requiring a browser environment.
Puppeteer
How it Handles JavaScript
Puppeteer is designed to work with dynamic, JavaScript-heavy websites. It launches a headless browser, allowing entire interaction with pages that rely on client-side scripts.
Puppeteer can wait for the complete rendering of a page, including JavaScript-driven updates.
Challenges
Increased resource consumption due to the browser instance makes it heavier than Cheerio for simple HTML parsing tasks.
Slower execution when compared to Cheerio for static content, especially when dealing with many requests.
Advantages
Comprehensive browser automation capabilities, allowing for interaction with elements modified by JavaScript.
Suitable for scraping dynamic content, such as single-page applications (SPAs) or websites with asynchronous updates.
Best Practices
Combine Cheerio and Puppeteer
Use Cheerio for parsing and extracting static content when JavaScript is not a significant factor.
For pages with heavy JavaScript dependencies, consider using Puppeteer for those specific tasks, allowing the best of both worlds.

Optimize Puppeteer Usage
Implement strategies like caching and managing browser instances efficiently to mitigate resource consumption.
Consider using Puppeteer's wait
For functions to ensure that JavaScript-dependent content is fully loaded before interacting with it.

User-Agent Spoofing
Some websites may behave differently based on the user agent. Puppeteer allows you to set a custom user agent to emulate different browsers.

Respect Robots.txt
Ensure your scraping activities comply with the website's robots.txt file to avoid legal and ethical issues.
Choosing between Cheerio and Puppeteer for JavaScript-heavy sites depends on the project's requirements. Cheerio is efficient for static content, while Puppeteer excels in handling dynamic pages. Combining both tools judiciously allows for a versatile and practical approach to web scraping tasks involving a mix of static and JavaScript-dependent content.
Choosing the Right Tool for the Job
When to Choose Cheerio:
Static Content Parsing
Scenario: Cheerio is a lightweight and efficient choice if your project primarily involves parsing static HTML content without the need for browser automation or dynamic interactions.
Example: Extracting data from static web pages where JavaScript doesn't play a significant role.
Resource Efficiency
Scenario: Cheerio's server-side parsing without browser overhead ensures efficient resource utilization in resource-constrained environments or when dealing with a large volume of static HTML data.
Example: Processing a dataset of static HTML documents for data extraction.
Simplicity and Speed
Scenario: Cheerio's simplicity and speed make it an attractive choice for simple parsing tasks and scenarios where a quick and straightforward solution is required.
Example: Parsing and extracting data from uniform and static web pages.
When to Choose Puppeteer:
Dynamic Content and JavaScript Interaction
Scenario: Puppeteer's browser automation capabilities become essential if your project involves scraping dynamic web pages with heavy JavaScript dependencies.
Example: Extracting data from a single-page application (SPA) or a website heavily relying on client-side rendering.
Browser Automation
Scenario: When your scraping tasks require simulating user interactions, filling forms, clicking buttons, or capturing dynamically loaded content, Puppeteer's browser automation features provide the necessary control.
Example: Automated testing scenarios where interacting with a website as a user is essential.
Parallel Execution and Scalability
Scenario: In projects that demand parallel execution or scalability, Puppeteer's ability to handle multiple browser instances concurrently can be advantageous.
Example: Large-scale web scraping projects where speed and parallelism are critical.
Comprehensive Feature Set
Scenario: For complex projects that require a comprehensive set of features, such as capturing screenshots, generating PDFs, or monitoring performance metrics, Puppeteer's rich feature set is beneficial.
Example: Creating a web scraping application with multiple functionalities beyond essential data extraction.
Considerations for Choosing:
Project Complexity
Cheerio: Ideal for simple tasks and static content parsing
Puppeteer: Suited for complex projects involving dynamic content, browser automation, and advanced features.
Resource Utilization
Cheerio: Lightweight and resource-efficient for parsing static HTML.
Puppeteer: Heavier due to browser instances but optimized for handling dynamic content.
Speed and Performance
Cheerio: Faster for static content parsing.
Puppeteer: Slower for simple tasks but excels in handling complex scenarios and dynamic content.
Learning Curve
Cheerio: Simple and easy to learn, especially for developers familiar with jQuery.
Puppeteer: There is a steeper learning curve, particularly for those new to browser automation and asynchronous JavaScript.
Choose Cheerio for simplicity, speed in static content parsing, and resource efficiency. Choose Puppeteer for projects involving dynamic content, browser automation, and a comprehensive feature set. Combining both tools judiciously in a project can provide a versatile and effective solution for handling various web scraping tasks. The decision should align with the specific requirements and complexities of the scraping project at hand.
Optimizing Scraping Projects
Tips for Cheerio:
Parallel Processing
Tip: Implement parallel processing to handle multiple requests concurrently. This can significantly reduce latency and improve overall efficiency.
Example:

Use Cheerio API Efficiently:
Tip: Optimize the use of Cheerio's API. Limit the use of unnecessary selectors and focus on extracting only the required data.
Example:

Caching and Rate Limiting:
Tip: Implement caching mechanisms to store already scraped data, reducing the need to make repeated requests. Additionally, use rate limiting to avoid overloading the target website.
Example:

Tips for Puppeteer:
Headless Mode
Tip: Use headless mode unless a visible browser is required. Headless mode consumes fewer resources and speeds up the scraping process.
Example:

Page Pooling and Reusing Browsers:
Tip: Consider creating a pool of pages or reusing browser instances to optimize resource utilization and reduce the overhead of launching new browsers.
Example:

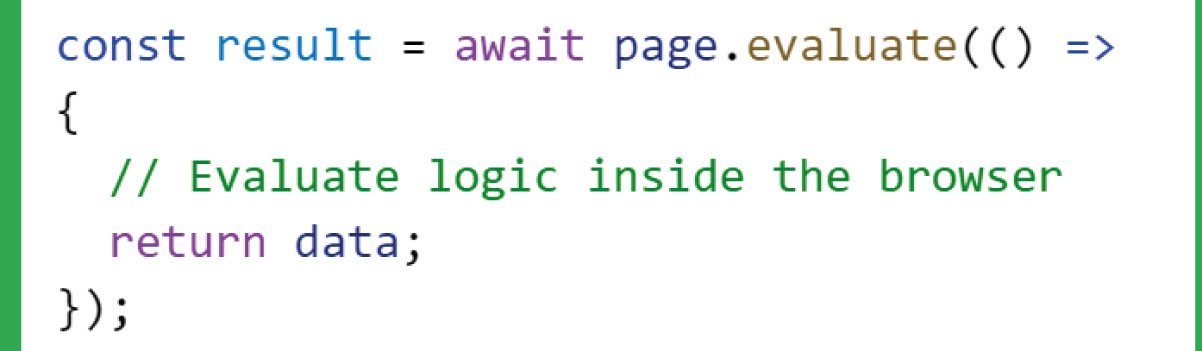
Evaluate in Browser:
Tip: Use page.evaluate efficiently by minimizing the amount of data transferred between the browser and Node.js. This can enhance performance.
Example:
Best Practices for Both:
Use Efficient Selectors
Tip: Optimize selector usage to target elements precisely. Avoid overly generic selectors to reduce the load on the browser or server.
Example:

Handle Asynchronous Operations:
Tip: Understand and handle asynchronous operations properly, especially when dealing with multiple requests or interactions. Utilize promises or async/await to manage asynchronous code.
Example:

Respect Robots.txt:
Tip: Ensure compliance with the website's robots.txt file to avoid legal and ethical issues. Respect the rules specified by the website.
Example:

User Agent Spoofing:
Tip: Occasionally websites may behave differently based on the user agent. Use Puppeteer to set a custom user agent if needed.
Example:

Error Handling:
Tip: Implement robust error handling to gracefully manage issues such as network errors, page load failures, or unexpected changes to the website structure.
Example:

By following these optimization tips and best practices, you can enhance the performance and efficiency of your scraping projects using Cheerio and Puppeteer while avoiding common pitfalls. Always be mindful of the ethical and legal aspects of web scraping and ensure that your scraping activities comply with the terms of use of the target website.
Conclusion: Cheerio vs. Puppeteer for Web Scraping
In summary, Cheerio and Puppeteer are potent tools with distinct strengths tailored for different web scraping scenarios. Let's revisit their key differences and offer insights into when to leverage each tool based on specific project needs.
Cheerio:
Strengths
- Efficient for parsing static HTML content.
- Lightweight and resource-efficient on the server side.
- It is ideal for simple parsing tasks and scenarios with minimal JavaScript interaction.
When to Use
- Projects primarily involve parsing static HTML content.
- Resource efficiency is crucial.
- Speed and simplicity are paramount.
Puppeteer:
Strengths
- Designed for browser automation and handling dynamic content.
- Supports interaction with JavaScript-heavy websites.
- Comprehensive feature set includes taking screenshots, generating PDFs, and monitoring performance.
When to Use
- Projects involve dynamic web pages or single-page applications.
- Browser automation, user interaction simulation, or comprehensive feature requirements are essential.
- Parallel execution and scalability are critical.
Encouragement
Web scraping is a dynamic field, and choosing the right tool depends on the unique demands of your project. Whether you opt for the efficiency of Cheerio in parsing static content or harness the browser automation capabilities of Puppeteer for dynamic scenarios, both tools offer valuable contributions to your web scraping endeavors.
Explore Real Data API
For an advanced and seamless web scraping experience, consider exploring the capabilities of Real Data API. With its robust features and ease of integration, Real Data API takes your data extraction projects to the next level. Empower your scraping efforts and unlock valuable insights from the web.
Ready to Elevate Your Scraping Game? Try Real Data API Today!
Latest posts

How to scrape GeM procurement analytics data for manufacturers to Unlock Smarter Government Contract Opportunities?

The future of Data-as-a-Service in 2026 - Trends, Innovations, and Business Opportunities

How To Use AI Agents For Automated Data Collection and Analysis to Improve Business Intelligence And Decision-Making
How to Scrape Dynamic pricing strategies powered by travel data for Smarter Travel Pricing and Revenue Optimization
Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.







Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7


Disclaimer : RealData API functions solely as an independent data infrastructure and technology solutions provider. We build customized automation workflows designed to collect publicly accessible web data based exclusively on client instructions. RealData API neither owns proprietary datasets nor engages in the sale or redistribution of extracted information. Our operations are limited strictly to lawful public web data processing and never involve unauthorized access to restricted systems or private networks. Any company names, trademarks, logos, or brand references displayed on this website are used purely for demonstrative and illustrative purposes to showcase our technical capabilities and do not imply endorsement, partnership, or affiliation. Use of our platform and services remains subject to our Terms of Service.