

Introduction
Web scraping has become an essential tool for businesses and developers alike. Whether you're conducting market research, performing price comparison, or gathering data for a project, choosing the right tool is crucial. Two of the most popular tools for web scraping are Scrapy and Puppeteer. This blog will help you understand Scrapy web data collection and Puppeteer data collection and guide you on how to choose between them based on your specific needs.
Introduction to Scrapy and Puppeteer
Scrapy: A Powerful Web Scraping Framework
Scrapy is a robust and widely-used web scraping framework in Python. Scrapy web scraping in Python is designed for extracting data from websites and has a simple and efficient API that allows developers to quickly build and run web spiders. Scrapy is especially well-suited for large-scale Scrapy web data collection due to its speed and efficiency.
Key Features of Scrapy
- Fast and Efficient: Scrapy is built to be fast, handling large amounts of data with ease.
- Built-in Data Pipelines: It includes pipelines for cleaning, processing, and storing scraped data.
- Extensive Documentation: Scrapy offers comprehensive documentation and a supportive community.
- Asynchronous Networking: Utilizes Twisted, an asynchronous networking framework, to handle concurrent requests efficiently.
Puppeteer: A Headless Browser Automation Tool

Puppeteer, a Node.js library, provides a high-level API for controlling Chromium browsers or headless Chrome. It is primarily used for Puppeteer data scraping, automated testing, and generating PDFs of web pages. Puppeteer excels in situations where Puppeteer data collection is necessary to render dynamic content on websites.
Key Features of Puppeteer
- Headless Browser: Controls Chrome or Chromium without a graphical user interface, which is perfect for automation tasks.
- JavaScript Execution: Can execute JavaScript on pages to ensure all dynamic content is rendered.
- Screenshot and PDF Generation: Capable of capturing screenshots and creating PDFs of web pages.
- Interactivity: Allows interaction with web pages, such as filling out forms and clicking buttons.
Comparing Scrapy and Puppeteer

Performance and Efficiency
Scrapy is known for its performance and efficiency. It can handle a high volume of requests and is optimized for large-scale data scraping projects. Its asynchronous nature allows it to process multiple requests concurrently, making it significantly faster for static websites.
Puppeteer, on the other hand, is slower because it needs to render the entire web page using a headless browser. This rendering process can be resource-intensive, especially for websites with heavy JavaScript usage. However, Puppeteer is more reliable for scraping dynamic content that relies on JavaScript execution.
Ease of Use
Scrapy has a steeper learning curve compared to Puppeteer. While it is incredibly powerful, setting up a Scrapy project requires a good understanding of Python and the framework itself. Once set up, it is highly customizable and efficient for experienced developers.
Puppeteer is relatively easier to use for those familiar with JavaScript and Node.js. Its API is straightforward, and it is easier to get started with basic scraping tasks. Puppeteer’s ability to interact with web pages as a user would (e.g., clicking buttons, filling forms) can make it simpler for beginners to achieve complex scraping tasks.
Handling Dynamic Content
Scrapy can struggle with websites that rely heavily on JavaScript to load content. While it is possible to use middleware or integrate Scrapy with other tools like Splash (a JavaScript rendering service), it adds complexity to the setup.
Puppeteer excels in handling dynamic content. Since it operates a headless browser, it can execute all the JavaScript on a page, making it ideal for scraping Single Page Applications (SPAs) and other dynamic websites. If your target website relies heavily on JavaScript, Puppeteer is the better choice.
Data Processing and Storage

Scrapy comes with built-in support for data pipelines, allowing you to clean, process, and store data seamlessly. You can export data in various formats, including JSON, CSV, and XML, and store it in databases directly from your Scrapy spiders.
Puppeteer does not have built-in data processing and storage capabilities. You will need to implement your own methods for handling the scraped data, which can be more time-consuming. This makes Scrapy more suitable for projects that require extensive data processing and storage.
Use Cases
Market Research and Price Comparison
For market research and price comparison, where the data is often static and spread across multiple pages, Scrapy is typically more efficient. It can scrape Puppeteer data quickly and process it using its pipelines.
Dynamic Websites and Interactive Pages
When scraping dynamic websites or pages that require user interaction, Puppeteer is the clear winner. It can handle JavaScript-heavy pages and perform actions like clicking buttons and filling out forms, which is crucial for scraping content behind interactive elements.
Web Scraping Services
If you're offering web scraping services to clients, the choice between Scrapy and Puppeteer will depend on the types of websites you'll be dealing with. For static sites, Scrapy will be more efficient. For dynamic, JavaScript-heavy sites, Puppeteer will be necessary.
Instant Data Scraper
For projects that require an instant data scraper solution where you need to get up and running quickly with minimal setup, Puppeteer might be more convenient due to its straightforward API and ease of use.
How to Choose the Right Tool for Your Project?
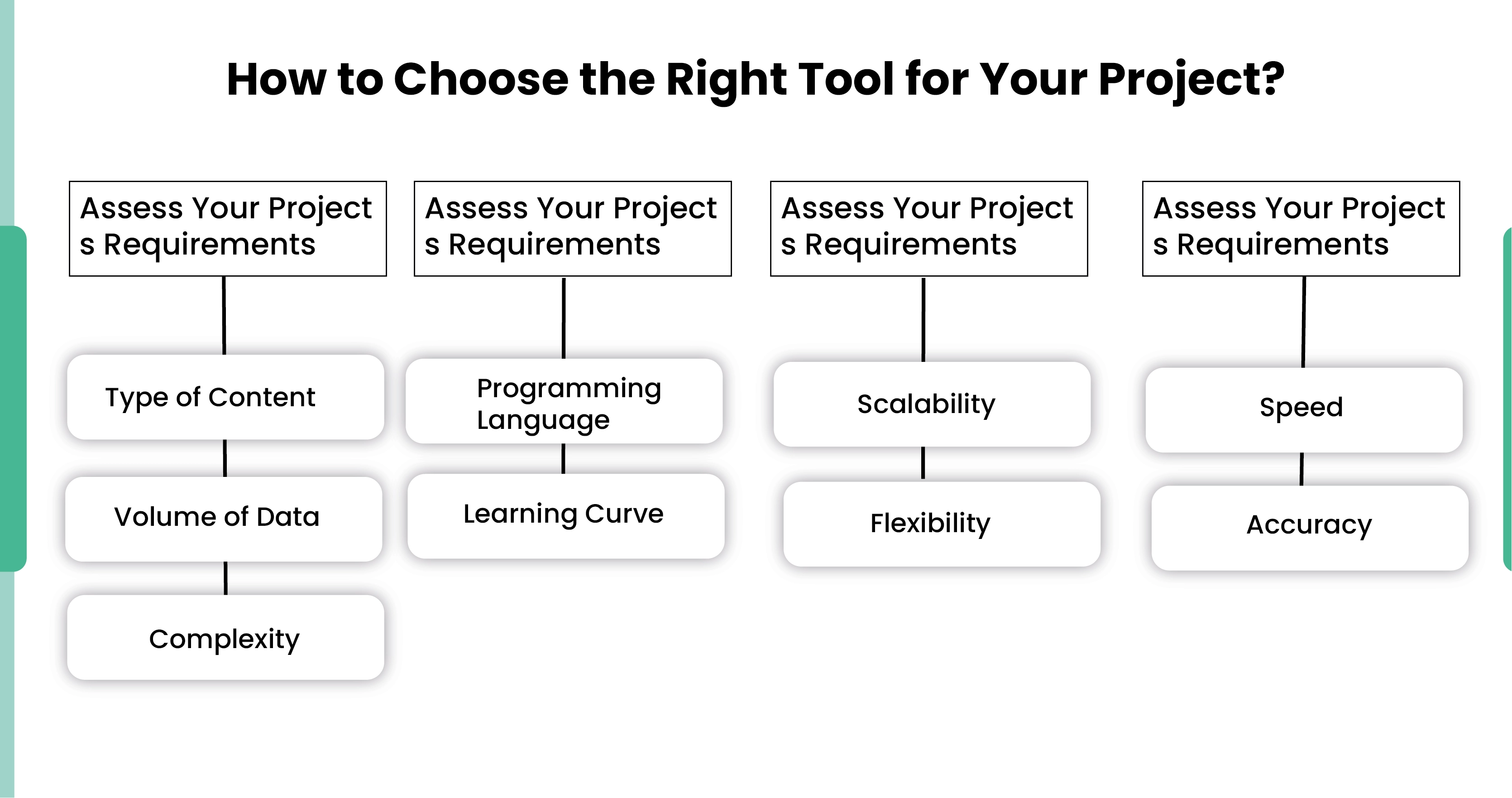
Assess Your Project's Requirements
- Type of Content: Determine whether the target websites are mostly static or dynamic.
- Volume of Data: Consider the amount of data you need to scrape Scrapy data in Python and how frequently you need to perform scraping.
- Complexity: Evaluate the complexity of interactions required on the target websites (e.g., form submissions, navigation).
Evaluate Your Technical Skills
- Programming Language: Choose based on your comfort with Python (Scrapy) or JavaScript (Puppeteer).
- Learning Curve: Assess your ability to learn and implement the necessary tool effectively.
Consider Long-Term Maintenance
- Scalability: Scrapy is more scalable for large projects with extensive data processing needs.
- Flexibility: Puppeteer offers more flexibility for handling dynamic content and interactive web pages.
Performance Needs
- Speed: If speed is critical and the content is static, Scrapy is preferable.
- Accuracy: For dynamic content accuracy, Puppeteer is the better choice.
Conclusion
Puppeteer and Scrapy, designed with different goals and following distinct paradigms, are both effective for scraping web content. Due to their differing approaches, Scrapy is ideal for scraping large volumes of data, while Puppeteer is best suited for navigating websites that render content after specific user interactions.
Despite these differences, these tools share some commonalities. Their communities are comparable, and they are more or less equal when it comes to ease of use. They also have common features, such as browser fingerprinting and proxy rotation, which are essential for effective web scraping services.
To industrialize your scraping efforts with a comprehensive tool stack, consider using Real Data API. You can learn more about Puppeteer data collection and explore integrations with both Puppeteer and Scrapy for enhanced web scraping capabilities.
Latest posts
Why Brands Use Competitive Data Intelligence to Increase Market Share in Highly Competitive Markets?

How To Scrape Competitor Data To Support Market Entry Strategy And Expansion Planning For Data-Driven Business Growth?

How Hotel Occupancy Intelligence Through Public Data Sources Is Reshaping Revenue Management

The ZIP Code Advantage: How Hyper-Local Amazon Product Data Collection Is Redefining Retail Intelligence
Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.







Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7


Disclaimer : RealData API functions solely as an independent data infrastructure and technology solutions provider. We build customized automation workflows designed to collect publicly accessible web data based exclusively on client instructions. RealData API neither owns proprietary datasets nor engages in the sale or redistribution of extracted information. Our operations are limited strictly to lawful public web data processing and never involve unauthorized access to restricted systems or private networks. Any company names, trademarks, logos, or brand references displayed on this website are used purely for demonstrative and illustrative purposes to showcase our technical capabilities and do not imply endorsement, partnership, or affiliation. Use of our platform and services remains subject to our Terms of Service.