

Introduction
Web scraping is a dynamic method that automates data extraction from websites, facilitating various applications across industries. From gathering market insights and competitor analysis to automating repetitive tasks, web scraping has become an invaluable tool for data-driven decision-making. However, ethical considerations are paramount. Respecting websites' terms of service and policies is essential to maintain a fair and legal approach to data extraction. Adhering to these guidelines ensures the sustainability of web scraping practices, fostering a balance between technological innovation and the responsible use of online resources.
Understanding Web Scraping
Web scraping is the automated process of extracting data from websites, enabling users to gather information efficiently. It involves accessing and parsing HTML or other markup languages to retrieve specific data points, providing valuable insights for various applications. However, the legality and ethics of web scraping are crucial considerations. While it can be a powerful tool, scraping should be done concerning the terms of service of the targeted website. Legal implications may arise if scraping violates these terms. Ethical web scraping involves obtaining permission, avoiding disruption to the website, and ensuring responsible data use.
Choosing a Target Website
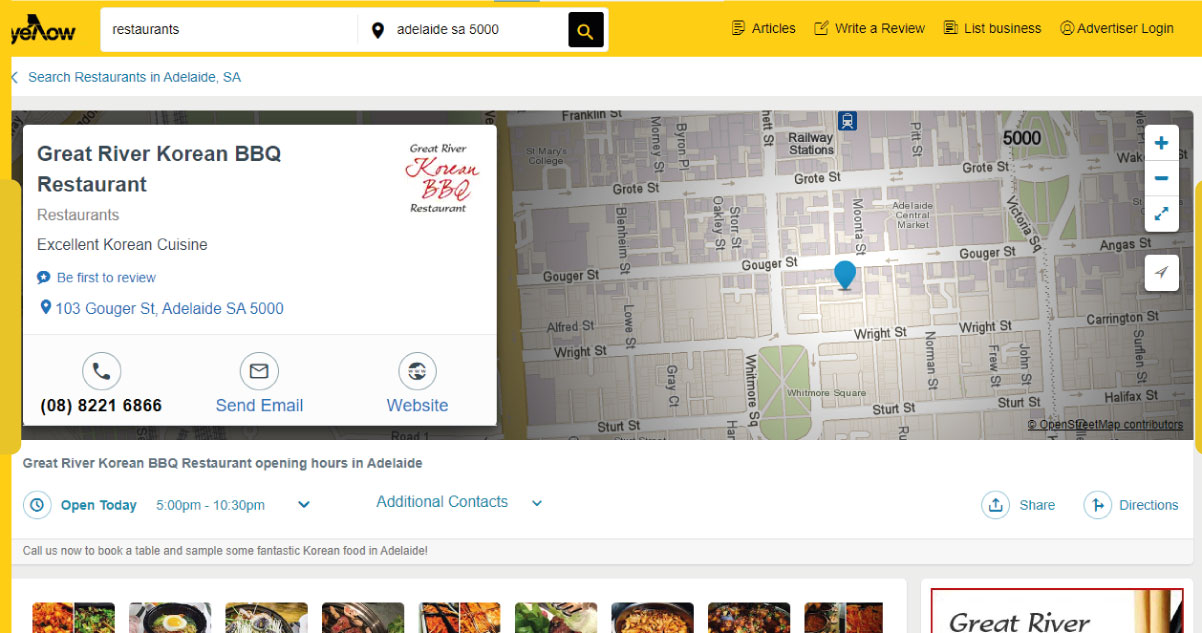
Yellow Pages is a valuable repository of local business information, offering a comprehensive database for those seeking details on restaurants, services, and more. Recognized for its wealth of listings, Yellow Pages is an ideal target for web scraping to compile relevant data. However, ethical considerations are paramount. Reviewing and respecting Yellow Pages' terms of service is imperative, ensuring compliance with usage policies. Adhering to these terms not only fosters responsible web scraping practices but also maintains the integrity of the source, allowing users to extract valuable information while upholding ethical standards.
Setting Up Your Environment
You'll need a well-configured environment to embark on web scraping for local restaurants on Yellow Pages. Two fundamental tools are Python, a versatile programming language, and BeautifulSoup, a Python library for parsing HTML and XML documents. Python is the backbone for scripting, and BeautifulSoup facilitates extracting relevant information from web pages.
Instructions for Installing Required Libraries:
Install Python:
Visit python.org to download the latest version.
Follow the installation instructions for your operating system.
Install BeautifulSoup:
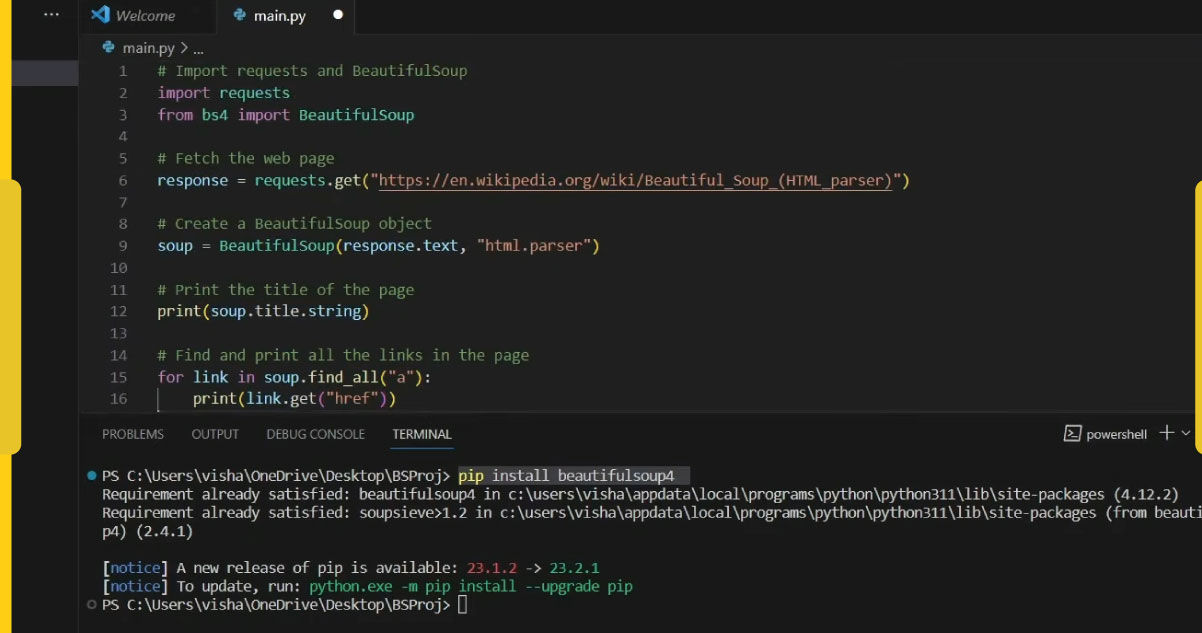
Open your terminal or command prompt.
Type: pip install beautifulsoup4
This command installs the BeautifulSoup library, making it ready for use in your web scraping project.
With Python and BeautifulSoup in place, you're well-prepared to initiate the web scraping process on Yellow Pages.
Inspecting the Website
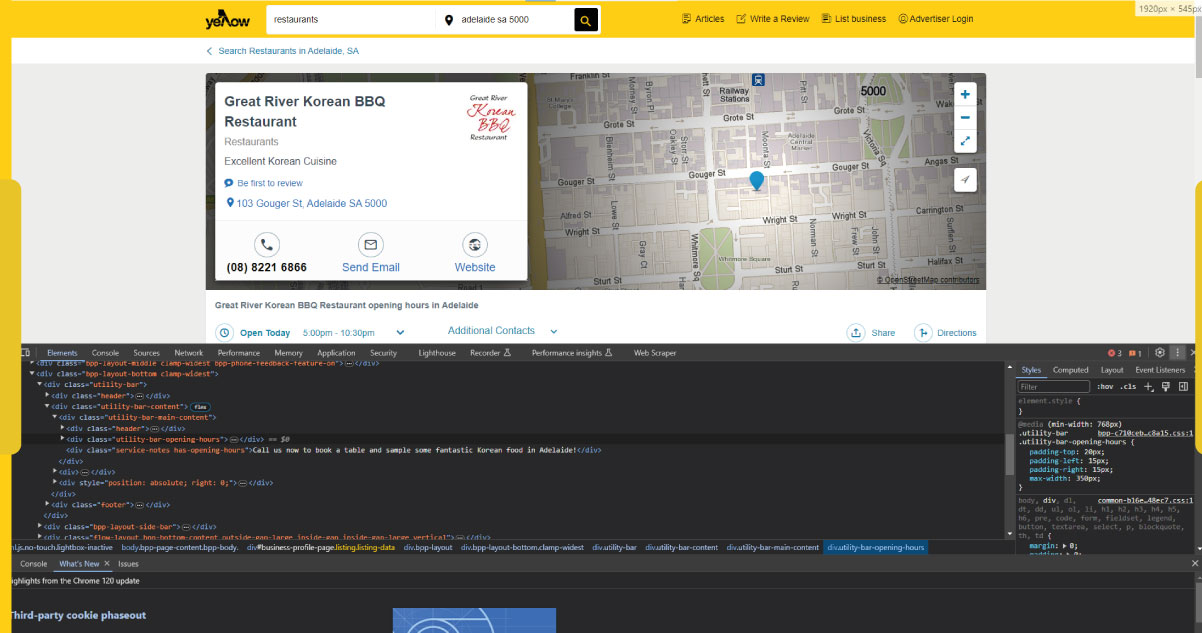
Before diving into web scraping, understanding the HTML structure of the Yellow Pages website is crucial for effectively targeting and extracting the desired information. The HTML structure is a roadmap, guiding the scraper to the specific elements containing your desired data. Here's why inspecting the website is vital:
Importance of Inspecting HTML Structure
Targeted Data Extraction:
Identifying the HTML elements housing the relevant information ensures accurate and focused data extraction.
Avoiding Unnecessary Requests:
Examining the HTML structure helps avoid unnecessary requests to the server, optimizing the scraping process and minimizing the risk of being flagged as suspicious activity.
Using Browser Developer Tools
Open Developer Tools:
To access the browser's developer tools, either right-click at the web page and select "Inspect," or utilize the keyboard shortcut Ctrl+Shift+I (for Windows or Linux) or Cmd+Opt+I (Mac). This will open the developer tools panel, allowing you to inspect the HTML structure of the webpage and identify relevant elements for web scraping.
Navigate the Elements Panel:
In the developer tools, navigate to the "Elements" or "Inspector" panel.
Hover over elements in the HTML code to highlight corresponding sections on the web page.
Identify Relevant Elements:
Inspect the HTML code to identify tags, classes, or IDs associated with the data you want to scrape.
Right-click on an element and use the "Copy" menu to copy its selector, XPath, or other attributes.
By leveraging browser developer tools, you gain insights into the Yellow Pages website's structure, empowering you to tailor your web scraper for precise and efficient data extraction. This meticulous approach ensures your scraper targets the correct elements, enhancing the overall effectiveness of your web scraping project.
Writing the Web Scraping Code
Now, let's delve into crafting a basic Python script for web scraping using the requests library to fetch the webpage and BeautifulSoup to parse its HTML content. This script will help you target specific HTML elements containing restaurant information on the Yellow Pages website.

How to Target Specific HTML Elements?
Inspect HTML
Use browser developer tools to inspect the Yellow Pages webpage and identify the HTML tags and classes associated with restaurant information.
Adjust Selectors
Update the script's find methods to match the HTML structure of the target website. For example, if restaurant names are in
tags, adjust the find method accordingly.
Customize URL
Modify the url variable to reflect your specific location and category on Yellow Pages.
By tailoring the script to match the structure of the Yellow Pages website, you can precisely target and extract restaurant information for your desired location and category.
Running the Scraper
Now that you have your web scraping script, let's customize it for a specific location and category on Yellow Pages. Additionally, it's crucial to highlight responsible testing practices to avoid placing an undue burden on the server.
Customizing the Script

Replace the arguments in scrape_yellow_pages with your desired location and category. In the example above, the script is set to scrape information for coffee shops in Los Angeles.
Responsible Testing Practices
Limit Requests:
When testing, limit the number of requests to avoid overloading the server. You can achieve this by scraping a small subset of data initially.
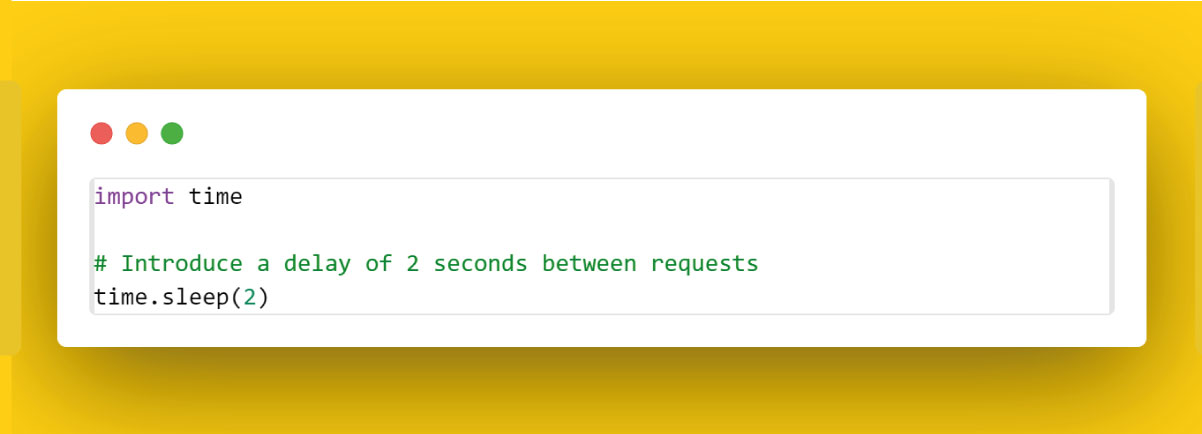
Use Time Delays
Introduce time delays between requests using the time module to simulate human-like interaction and prevent rapid, aggressive scraping.
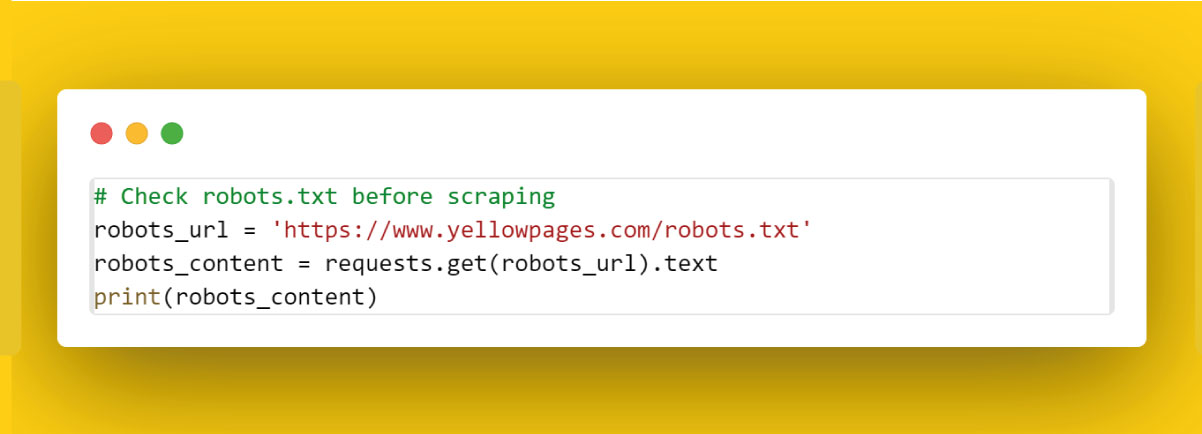
Check Robots.txt
Review the website's robots.txt file to understand any specific rules or restrictions. Respect these rules to maintain ethical scraping practices.
By customizing the script for a specific location and category while incorporating responsible testing practices, you ensure a measured and ethical approach to web scraping. This not only prevents potential server strain but also upholds good scraping etiquette and respects the website's terms of service.
Handling Data
Once you've successfully scraped data from Yellow Pages, it's essential to manage and store that information efficiently. Here are some effective ways to handle the scraped data and best practices for data management and storage:
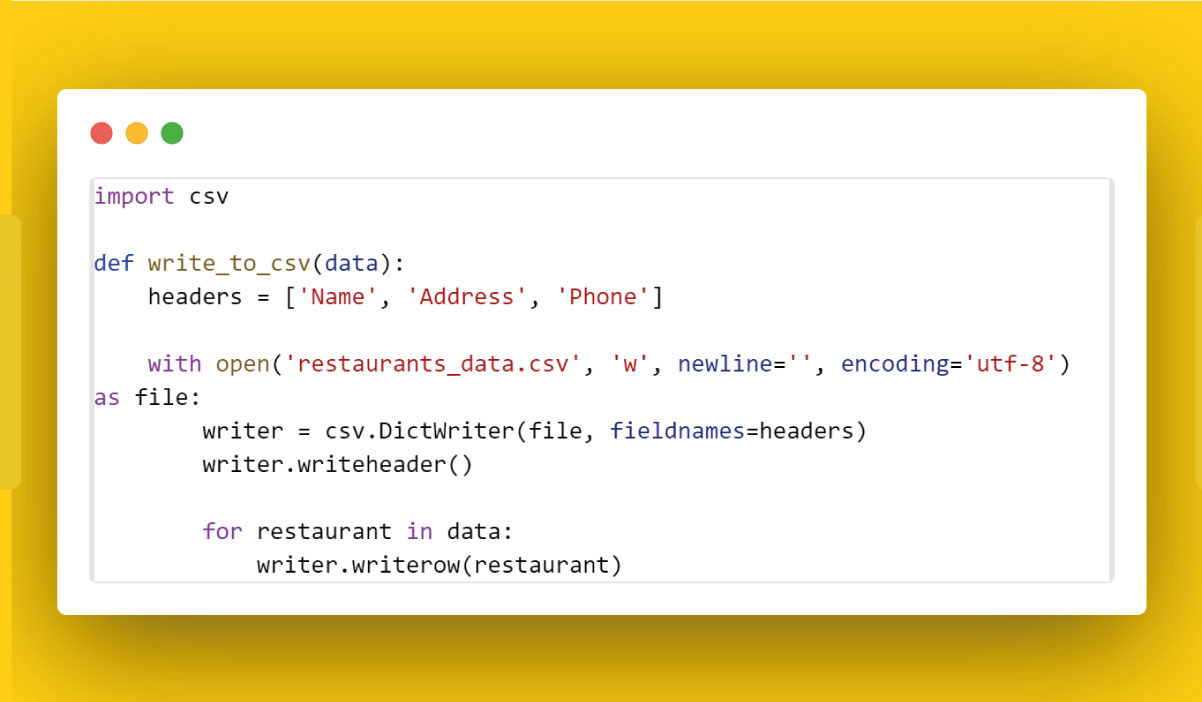
1. Writing to a File:
Example - Writing to a CSV file:
2. Storing in a Database
Example - Using SQLite:

Best Practices for Data Management and Storage
Normalize Data
Structure data in a standardized format for consistency and ease of retrieval.
Backup Data
Regularly back up your scraped data to prevent loss in case of unforeseen issues.
Respect Copyright and Privacy
Be mindful of copyright and privacy laws when storing and sharing scraped data.
Monitor Changes
Periodically check if the website's structure changes, and update your scraping script accordingly.
Handle Errors Gracefully
Implement error-handling mechanisms to manage issues such as network errors or changes in website structure.
By choosing an appropriate storage method, adhering to best practices, and staying vigilant in data management, you ensure that your scraped data remains accessible, organized, and compliant with ethical considerations.
Respecting Yellow Pages' Policies
Respecting Yellow Pages' policies is paramount in ethical web scraping. Adhering to their terms of service ensures legality and responsible data extraction. Employ rate limiting by introducing delays between requests, preventing server overload. Rotate user-agent strings to enhance anonymity and avoid detection. Refrain from aggressive scraping to maintain website functionality and minimize disruptions. Regularly check Yellow Pages' robots.txt file for guidelines on crawling permissions. Upholding ethical practices safeguards your project and contributes to a positive online environment, fostering trust with website owners and the broader web community.
Potential Challenges and Solutions
Web scraping, while powerful, comes with its set of challenges. Recognizing and addressing these challenges is essential for a successful and sustainable scraping project.
Common Challenges
Anti-Scraping Mechanisms:
Challenge: Websites employ anti-scraping measures, such as CAPTCHAs or IP blocking, to deter automated bots.
Solution: Use tools like Selenium for dynamic content or rotating proxies to bypass IP restrictions. Employ CAPTCHA-solving services if necessary.
Website Structure Changes
Challenge: Websites may undergo structural changes, affecting the location of target elements.
Solution: Regularly update and adapt your scraping script to reflect any modifications in the website's HTML structure.
Rate Limiting and Throttling
Challenge: Websites may enforce rate limiting, slowing down, or blocking excessive requests from a single IP address.
Solution: Implement rate limiting in your script to avoid aggressive scraping. Rotate IP addresses or use proxies to distribute requests.
Handling Dynamic Content
Challenge: Some websites load content dynamically using JavaScript, making it challenging to scrape.
Solution: Use tools like Selenium or Puppeteer to simulate browser behavior and access dynamically loaded content.
Legal and Ethical Concerns
Challenge: Scraping without permission can lead to legal consequences and ethical dilemmas.
Solution: Always review and respect the website's terms of service. Obtain permission when necessary, and scrape responsibly.
Tips for Success
Regular Monitoring:
Regularly monitor the scraping process and adjust the script as needed to accommodate any changes on the website.
Error Handling:
Implement robust error-handling mechanisms to manage issues such as network errors or unexpected changes in website structure.
User-Agent Rotation:
Rotate user-agent strings to mimic diverse browser interactions and reduce the risk of detection.
Proxy Usage:
Use proxies to mask your IP address and prevent IP blocking. Rotate proxies to distribute requests.
Documentation:
Keep thorough documentation of your scraping process, including the website's structure, potential challenges, and solutions implemented.
By anticipating and effectively addressing these challenges, you enhance the resilience and reliability of your web scraping project while maintaining ethical and legal standards.
Conclusion
In this comprehensive guide, we've explored the dynamic realm of web scraping, focusing on extracting local restaurant data from Yellow Pages. We began by understanding the fundamentals of web scraping, emphasizing its potential applications across various industries. A crucial aspect highlighted throughout is respecting Yellow Pages' terms of service to maintain ethical standards in data extraction.
We provided a practical walkthrough, demonstrating how to set up your environment using Python and BeautifulSoup, inspect the website effectively, and craft a web scraping script tailored to Yellow Pages. As you run your scraper, we emphasize responsible testing practices, encouraging users to customize their scripts for specific locations and categories while avoiding aggressive requests.
Managing the scraped data was discussed with insights into writing to files or databases, along with best practices for data storage and ethical considerations. The importance of adhering to Yellow Pages' policies and promoting ethical scraping practices, including rate limiting and avoiding aggressive techniques, was reiterated.
In conclusion, responsible web scraping is the cornerstone of a sustainable and ethical approach to data extraction. As you embark on your scraping journey, always prioritize respect for websites' terms of service, implement ethical practices, and consider using Real Data API for a structured and legitimate data access experience. Let's ensure the integrity of the online ecosystem by scraping responsibly and contributing to a positive web environment.
Latest posts

How to scrape GeM procurement analytics data for manufacturers to Unlock Smarter Government Contract Opportunities?

The future of Data-as-a-Service in 2026 - Trends, Innovations, and Business Opportunities

How To Use AI Agents For Automated Data Collection and Analysis to Improve Business Intelligence And Decision-Making
How to Scrape Dynamic pricing strategies powered by travel data for Smarter Travel Pricing and Revenue Optimization
Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.







Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7


Disclaimer : RealData API functions solely as an independent data infrastructure and technology solutions provider. We build customized automation workflows designed to collect publicly accessible web data based exclusively on client instructions. RealData API neither owns proprietary datasets nor engages in the sale or redistribution of extracted information. Our operations are limited strictly to lawful public web data processing and never involve unauthorized access to restricted systems or private networks. Any company names, trademarks, logos, or brand references displayed on this website are used purely for demonstrative and illustrative purposes to showcase our technical capabilities and do not imply endorsement, partnership, or affiliation. Use of our platform and services remains subject to our Terms of Service.