

Introduction
In today's fast-paced eCommerce world, on-demand grocery delivery apps like Krave Mart are reshaping how consumers shop for daily essentials. Based in Pakistan, Krave Mart has become a go-to app for quick and convenient grocery delivery, offering a wide range of products — from household items and snacks to personal care and beverages — all accessible within minutes.
For data-driven businesses, understanding Krave Mart's product ecosystem is invaluable. Conducting a data collection exercise on Krave Mart as well as Krave Mart Data Scraping enables analysts, marketers, and retailers to gain insights into product categories, availability, pricing, and market trends.
This blog discusses the complete process and purpose behind Web Scraping Krave Mart data — capturing all available product categories and other publicly accessible data to build valuable datasets for business intelligence and market research.
What is Krave Mart?
Krave Mart is one of Pakistan's fastest-growing instant delivery platforms, similar to Blinkit, Zepto, or Getir. Through its mobile app and web interface, Krave Mart offers thousands of products across multiple categories with rapid delivery within minutes.
The platform's key features include:
- A wide range of product categories (grocery, beverages, baby care, personal care, snacks, cleaning supplies, etc.)
- Discounted pricing and offers
- Fast delivery (15–30 minutes)
- User-friendly interface with easy navigation
Because Krave Mart's listings, categories, and offers are publicly available, conducting a Krave Mart Data Collection exercise helps businesses understand how its product structure, pricing, and promotions operate.
Objective of the Krave Mart Data Collection Exercise
The main goal of this project is to capture all available product categories listed on the Krave Mart application with the help of Krave Mart Data Scraping — along with any publicly accessible details related to these categories.
This exercise aims to:
- Identify and extract all primary and subcategories available in Krave Mart's catalog.
- Collect structured metadata such as product names, SKUs, brand names, images, and prices.
- Analyze category structure and depth to understand how Krave Mart organizes its inventory.
- Extract additional public data such as product descriptions, availability, offers, and promotional tags.
- Create a structured Grocery dataset for analysis, comparison, or integration into business intelligence tools.
Why Web Scraping Krave Mart Data is Valuable
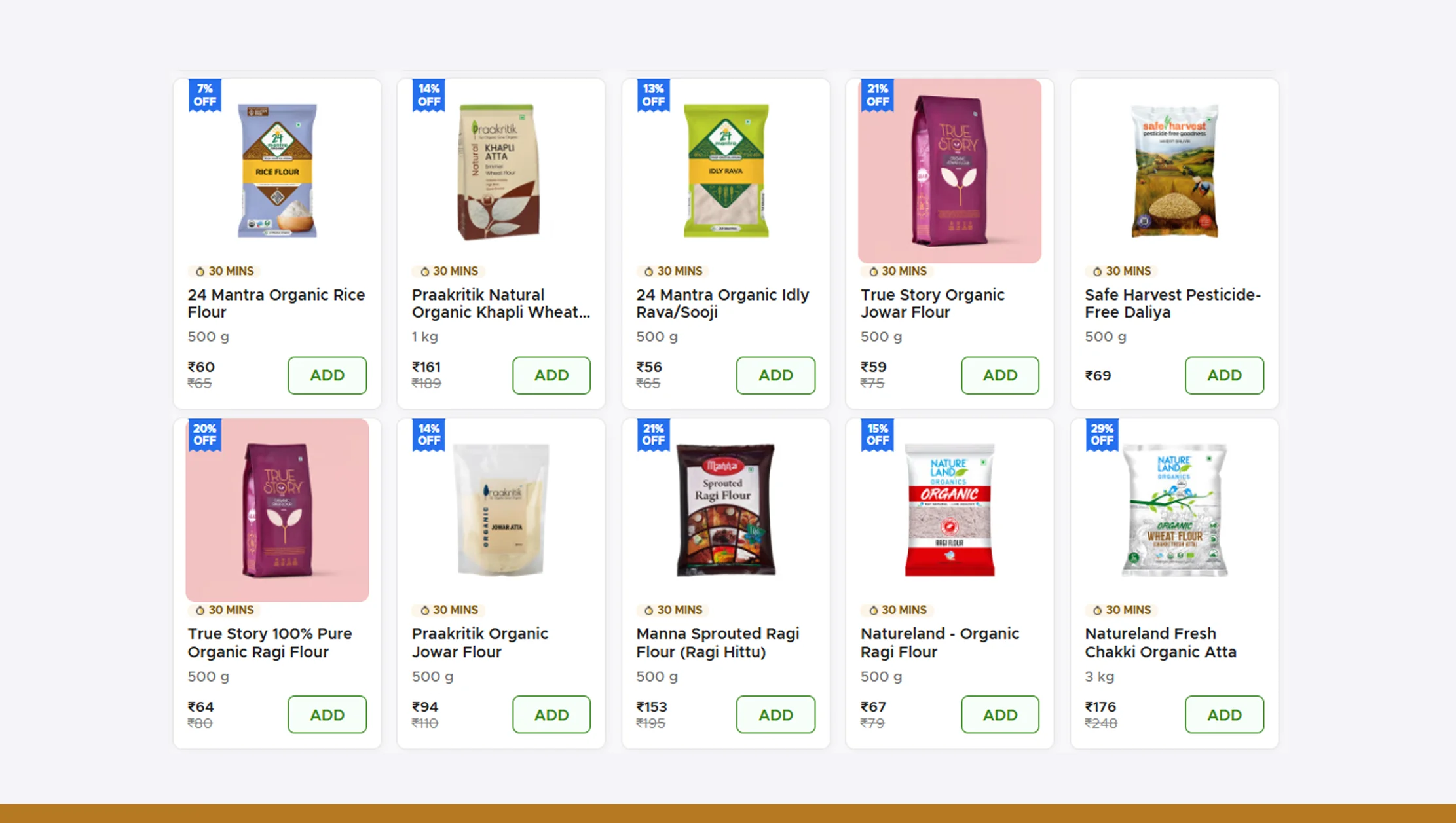
Performing Web Scraping Krave Mart or Krave Mart Data Extraction is not just a technical exercise — it provides a strategic advantage for several types of businesses and researchers.
Here are the main benefits:
- Category Mapping and Market Understanding
By scraping category data, analysts can identify how Krave Mart structures its products — which helps other eCommerce companies improve their own catalog organization and UX. - Competitor Analysis
Tracking product availability and pricing from Krave Mart data scraping helps brands and retailers benchmark themselves against competitors in Pakistan's on-demand delivery ecosystem. - Demand Forecasting
Analyzing category-level trends can help forecast which product types (e.g., snacks, drinks, or baby care items) are gaining traction in specific regions. - Inventory Optimization
Retailers and wholesalers can align their inventory management systems with trending Krave Mart products to meet customer demand efficiently. - Pricing Insights
Capturing price points across categories gives an idea of Krave Mart's pricing strategy and how discounts are applied seasonally or regionally. - Product and Brand Tracking
With regular data collection, businesses can monitor how frequently products or brands appear, go out of stock, or receive promotional visibility automated Web Scraping API solutions.
Scope of Krave Mart Data Collection

During the Krave Mart Data Collection Exercise, the focus is to collect publicly available data accessible through the Krave Mart application or website.
Primary Data Points to Capture
| Data Type | Details Collected |
|---|---|
| Category Data | Main categories, subcategories, and category hierarchy |
| Product Metadata | Product Name, SKU/ID, Brand, Description, Unit Size |
| Pricing Information | Original Price, Discounted Price, Offer Tags |
| Availability | In-stock / Out-of-stock status |
| Visual Data | Product image URLs |
| Promotional Content | Offers, Discount Labels, "Hot Deals" tags |
| Additional Attributes | Packaging size, Quantity, or Product variants |
Process of Web Scraping Krave Mart Data

Conducting a structured Krave Mart Data Extraction involves a combination of data scraping, parsing, and processing steps. Below is the breakdown:
- Step 1: Identifying Publicly Accessible Endpoints
The first step is to analyze Krave Mart's application structure to find URLs or API endpoints that serve data publicly — such as category lists, product details, and search results. - Step 2: Category Discovery
Once endpoints are found, scripts are designed to crawl through category-level data, capturing:- Category IDs and names
- Parent and subcategory relations
- Category URLs and associated metadata
- Step 3: Product Data Extraction
After identifying categories, each category is scanned to fetch product-level data:- Product titles
- Brand names
- Prices and discounts
- Product descriptions
- Availability
- Step 4: Data Structuring
The scraped data is then cleaned and formatted into structured formats like JSON, CSV, or Excel, ensuring easy usability for analytics or visualization. - Step 5: Validation and Quality Check
Data accuracy is verified by cross-checking product counts, duplicates, and category relationships. This ensures the integrity and reliability of the dataset.
Example of Structured Krave Mart Data
| Category | Product Name | Brand | Price (PKR) | Discount | Availability |
|---|---|---|---|---|---|
| Beverages | Pepsi 500ml Bottle | PepsiCo | 90 | 10% Off | In Stock |
| Baby Care | Pampers New Baby Diapers | Pampers | 1550 | 5% Off | In Stock |
| Snacks | Kurkure Masala Munch | PepsiCo | 70 | N/A | In Stock |
| Cleaning Supplies | Surf Excel Detergent 1kg | Unilever | 510 | 8% Off | Out of Stock |
This dataset represents a small glimpse of what can be collected using Krave Mart Data Scraping.
Challenges in Krave Mart Data Collection
While the process is straightforward technically, there are several practical challenges:
- Dynamic App Structure
Krave Mart's mobile app uses dynamic data loading, which requires advanced crawling or reverse-engineering of API calls to fetch complete category data. - Frequent Updates
As prices and product availability change frequently, regular re-scraping schedules must be implemented for up-to-date insights. - Anti-Bot Mechanisms
Modern delivery apps use bot-prevention systems, so ethical and controlled scraping techniques must be applied. - Data Volume
Large category and product lists generate huge data volumes — requiring scalable Enterprise Web Crawling solutions.
Best Practices for Ethical Data Collection
While Krave Mart Data Scraping offers valuable insights, it's essential to ensure the process adheres to ethical and legal standards.
Follow these best practices:
- Collect only publicly available data.
- Respect website terms and conditions.
- Avoid overloading servers with too many requests.
- Use responsible scraping frequencies to maintain ethical standards.
- Anonymize and aggregate data for research or analysis purposes.
At Real Data API, all scraping activities are designed with compliance in mind, ensuring responsible, policy-aligned data practices.
Applications of Krave Mart Data

Once collected, Krave Mart Data Scraping outputs can be applied across multiple domains:
- Category Intelligence Reports
Identify the most populated and popular product categories within Krave Mart for business research or investor reports. - Competitive Product Benchmarking
Compare products, pricing, and availability against other on-demand platforms like Airlift or Pandamart. - Consumer Behavior Insights
Analyze which categories receive higher product counts, more discounts, or faster restocking — reflecting consumer demand patterns. - Marketing and Brand Analysis
Use product listings and descriptions to study how brands position themselves, what offers they provide, and how frequently they appear in featured sections. - Data Integration into BI Dashboards
Integrate structured Krave Mart datasets into Power BI, Tableau, or Google Data Studio to visualize pricing trends, product variety, and market share.
Krave Mart Data Collection API Option

For advanced users and enterprises, a Krave Mart Data API can be developed to automate periodic data updates.
API Features:
- Fetch real-time Krave Mart product and category data
- Structured JSON responses
- Integration with data analytics pipelines
- Scheduling options for hourly/daily refresh
- Scalable infrastructure for thousands of products
This automation ensures seamless integration into enterprise-level workflows via the Grocery Data Scraping API.
Conclusion
Performing a data collection exercise on Krave Mart is a powerful step toward understanding the evolving online grocery ecosystem in Pakistan.
By capturing all available product categories and publicly accessible information, organizations gain actionable insights into how Krave Mart structures its marketplace, manages pricing, and highlights popular brands.
Whether for market research, competitive analysis, or product intelligence, the process of Web Scraping Krave Mart delivers invaluable information that fuels smarter business decisions.
At Real Data API, we specialize in developing custom Krave Mart Scrapers, APIs, and automated data pipelines that help you collect, clean, and analyze market data effortlessly — while adhering to ethical scraping standards.
Latest posts
Why Brands Use Competitive Data Intelligence to Increase Market Share in Highly Competitive Markets?

How To Scrape Competitor Data To Support Market Entry Strategy And Expansion Planning For Data-Driven Business Growth?

How Hotel Occupancy Intelligence Through Public Data Sources Is Reshaping Revenue Management

The ZIP Code Advantage: How Hyper-Local Amazon Product Data Collection Is Redefining Retail Intelligence
Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.







Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7


Disclaimer : RealData API functions solely as an independent data infrastructure and technology solutions provider. We build customized automation workflows designed to collect publicly accessible web data based exclusively on client instructions. RealData API neither owns proprietary datasets nor engages in the sale or redistribution of extracted information. Our operations are limited strictly to lawful public web data processing and never involve unauthorized access to restricted systems or private networks. Any company names, trademarks, logos, or brand references displayed on this website are used purely for demonstrative and illustrative purposes to showcase our technical capabilities and do not imply endorsement, partnership, or affiliation. Use of our platform and services remains subject to our Terms of Service.