

Introduction
In recent years, food waste has emerged as a critical global issue — and it demands better, data-driven solutions. By choosing to scrape the ResQ Club API for sustainability insights, researchers, developers and social organisations can gain unprecedented visibility into patterns of surplus-food rescue and redistribution. Access to this raw data enables rigorous analysis of how much food is diverted from waste, when and where rescues occur, and which communities benefit most. Such insights can inform policy, improve logistical planning for food rescue initiatives, and help stakeholders measure tangible impact over time. In the face of mounting environmental, social, and economic costs linked to food waste, transforming operational data into actionable intelligence empowers evidence-based Price Comparison decisions driving sustainability and social welfare.
Laying the Foundation: building a data collection engine
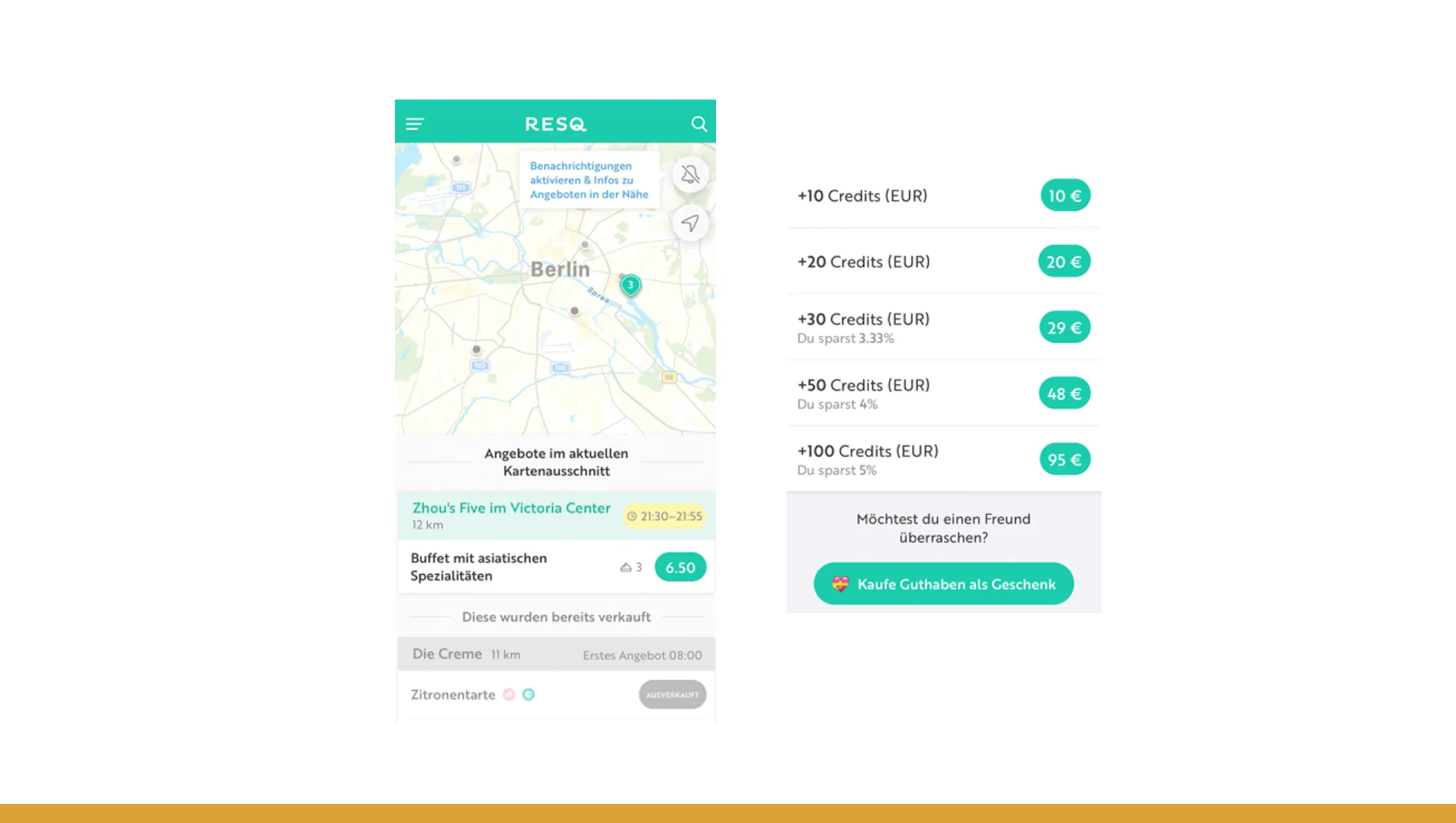
With a robust Automated scraper for ResQ Club surplus food data, you establish a system that periodically polls the source and fetches fresh data — no manual effort required. Suppose you schedule the scraper to run daily; over six years (2020–2025), you accumulate a continuous stream of records that include date, food volume rescued, type of food, origin (restaurant, grocery, cafe), and rescue status (claimed, picked up, delivered). This longitudinal data lets you observe trends: growth in rescues, seasonal fluctuations, and sudden spikes or dips that reveal operational or demand-driven changes.
For example, your collected data might show:
| Year | Rescued Food Volume (kg) | Number of Rescues | Average Rescues per Day |
|---|---|---|---|
| 2020 | 12,000 | 1,200 | ~3.3 |
| 2021 | 28,000 | 2,800 | ~7.7 |
| 2022 | 45,000 | 4,500 | ~12.3 |
| 2023 | 60,000 | 6,000 | ~16.4 |
| 2024 | 75,000 | 7,500 | ~20.5 |
| 2025 | 90,000 | 9,000 | ~24.7 |
Over time, the statistics build compelling evidence: increasing adoption, greater scale, and growing social impact. Once such a dataset exists, you can layer analytic tools — dashboards, time-series analyses, and impact reports — to surface patterns and support decision-making.
Transforming raw logs into meaningful records
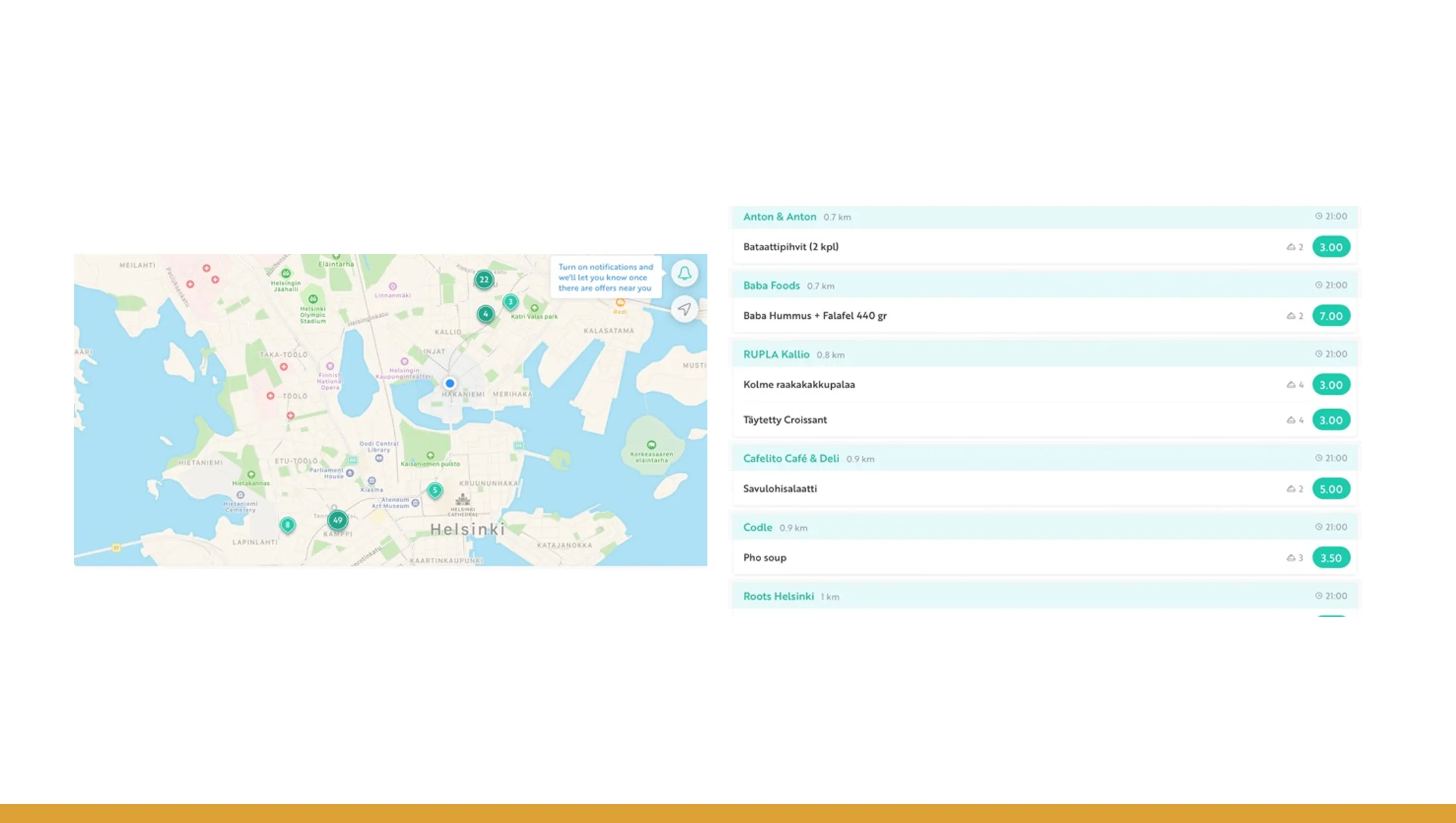
Through careful ResQ Club data extraction, you move from raw JSON / API responses to structured data stored in a database or CSV. This step ensures each record is normalized: rescue date, food quantity, food category (e.g. dairy, bakery, cooked meal), origin establishment, destination (charity, individual, pickup), and metadata such as expiry or reservation time. With structured extraction, you can aggregate across different dimensions — by food type, by region, by time — enabling more nuanced insights.
Imagine over 2020–2025 your dataset grows to tens of thousands of entries. You could produce breakdowns like:
- Total kilograms rescued per year
- Percentage share by food category
- Monthly or seasonal variation in rescue volume
- Distribution of rescues across origin types (restaurants vs. groceries vs. bakeries)
These breakdowns allow for deeper analysis — for example, evaluating which food categories contribute most to waste reduction, or identifying regions or days with highest rescue demand. This level of data maturity transforms operational logs into a tool for insight and planning.
Building a reliable data pipeline for long-term analysis
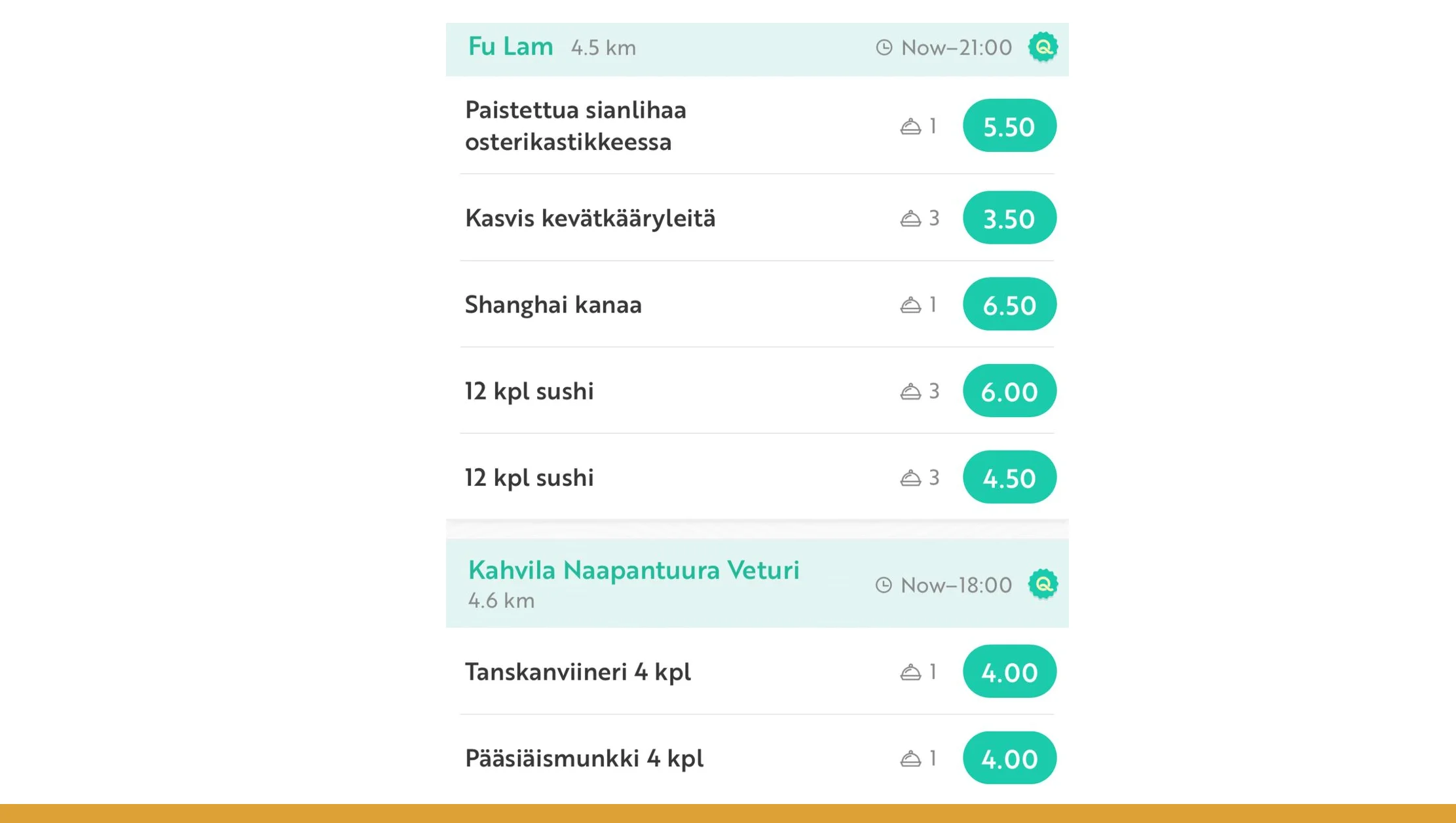
Designing a production-grade ResQ Club API scraper involves more than fetching data — it requires robustness. Key practices include rate-limiting to comply with API usage policies, handling paginated responses or batch data, retry logic to manage network failures or incomplete data, and logging to track success/failure of each run. It’s also wise to archive raw responses (raw JSON) alongside parsed records so that you can audit, re-parse, or adapt when the API schema changes.
Across 2020–2025, maintaining such a scraper ensures continuity. It prevents data gaps that can skew analysis — for instance, missing months or years that would distort trend evaluation. A stable pipeline enables year-over-year comparison, data quality checks (for anomalies or duplicates), and versioning to track schema evolution. In sum, a solid scraper is the backbone of a reliable dataset; without it, any insights drawn may be flawed or inconsistent.
Turning data into meaningful impact metrics
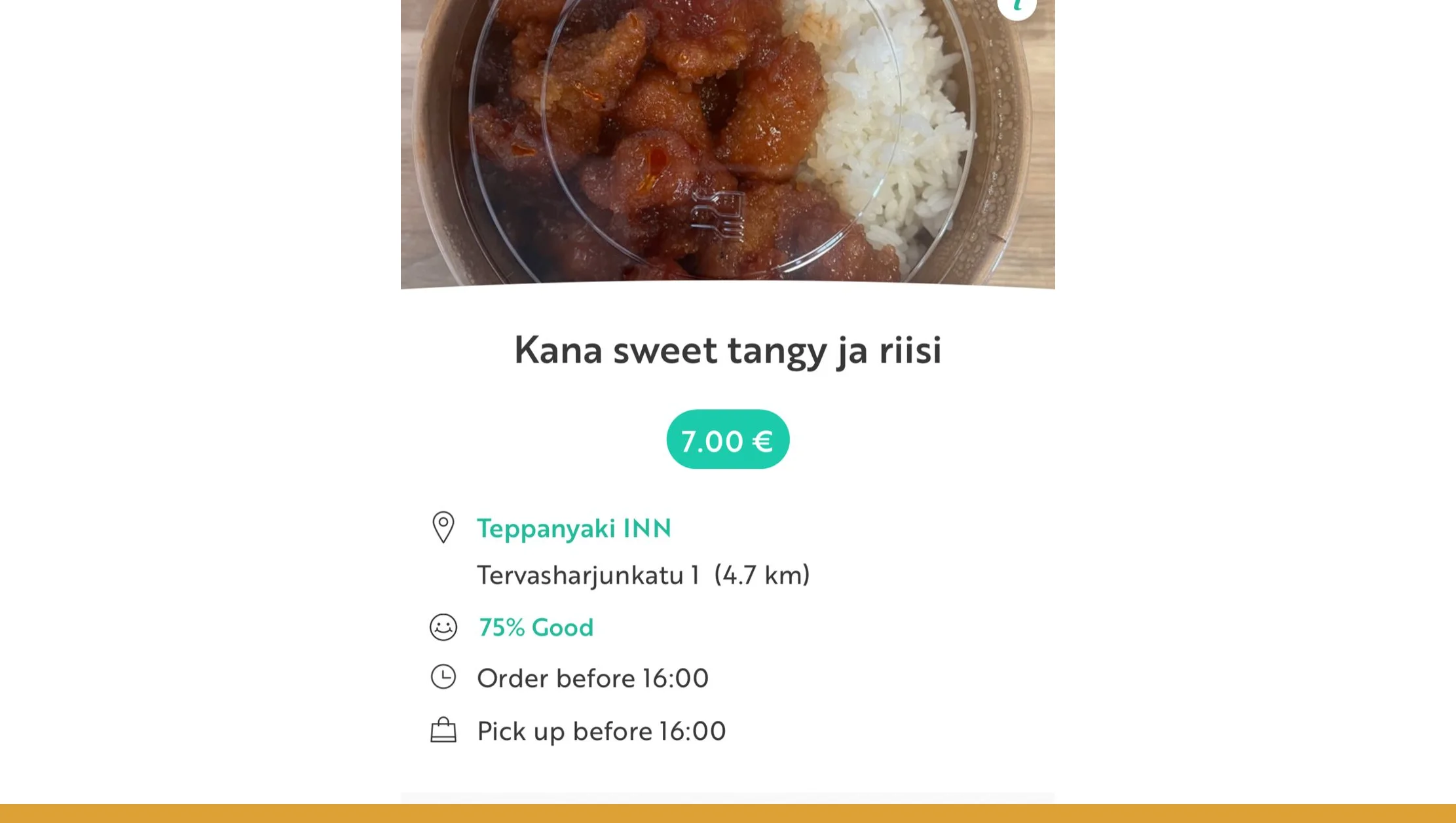
With clean aggregated data in hand, you can derive Food-waste reduction insights that demonstrate real-world impact. For instance: total kilograms diverted from waste, number of meals saved, and — by combining with environmental conversion factors — estimated greenhouse gas emissions avoided or water/land resources conserved. According to global reports, the world wasted ~931 million tonnes of food in 2019. By 2022 that number had risen to approximately 1.05 billion tonnes — about 19% of food available to consumers.
By comparing your rescued-food data against estimated local food waste baselines, you can estimate the share of waste being diverted. For example, if in a city food waste is estimated at 100 tonnes per year, and your rescues total 10 tonnes, you might claim a 10% diversion rate — a concrete metric useful for NGOs, charities, or policymakers. Over 2020–2025, tracking yearly rescued volumes can show growth in impact, identify periods of high waste or high rescue, and support arguments for scaling up rescue efforts or funding.
Enriching insight with delivery and distribution context

If available, integrating data from a ResQ Club Delivery API helps go beyond rescue counts to evaluate distribution efficiency and equity. Delivery-level metadata — such as pickup time, delivery time, distance covered, route information, and beneficiary location — allows assessment of logistical performance. Over 2020–2025, such data can show whether rescued food reaches underserved areas, how quickly distribution happens after rescue, and how far food travels — which matters for environmental impact (fuel, emissions) and freshness of food.
This enriched dataset supports more sophisticated analyses: e.g., average delivery distance per rescue, time from rescue to delivery, or regional coverage over time. Such metrics help optimize routing, reduce delivery-related emissions, and improve service to beneficiaries. For organisations coordinating rescues, this level of detail can inform resource allocation — deciding whether to deploy more pickup vehicles, set up new distribution hubs, or partner with local charities to broaden reach.
Creating a comprehensive record of surplus-food activity

Through consistent logging, extraction, and enrichment, you build a master Food Dataset spanning multiple dimensions — volume, type, origin, destination, timing, and delivery logistics. Over 2020–2025, this dataset can grow to many thousands of rows, enough to support not just descriptive stats but predictive modeling: anticipating peak waste times, forecasting rescue demand, or estimating environmental impact of different rescue strategies.
With this dataset, stakeholders can build dashboards, share anonymized aggregated data for research, or inform policy discussions. It becomes a powerful tool for transparency — showing exactly how much food was rescued, when, from where, and where it went. That clarity helps attract donors, convince policymakers, or galvanize community action. More importantly, it transforms the abstract problem of “food waste” into concrete, measurable phenomena — enabling evidence-based interventions that can scale.
Why Rely on Real Data API?
Using a Food Data Scraping API instead of static reports or surveys offers significant advantages — especially when you scrape the ResQ Club API for sustainability insights. Live data ensures timeliness: you don’t rely on outdated annual reports or memory-based surveys. Granularity is better: you capture each rescue event — with metadata — allowing per-meal, per-kg, per-day or per-region analysis. Data completeness improves over time, enabling longitudinal studies and trend detection. And data transparency fosters accountability: stakeholders can verify rescued quantities, time and location. This level of detail supports strategic planning, evaluation, and credible reporting.
High-level context: global food-waste trends (2020–2022)
| Year | Estimated Global Food Waste (tonnes) | % of Consumer Food Wasted | Notes |
|---|---|---|---|
| 2019 | ~931,000,000 | ~17% | Pre-pandemic baseline. |
| 2020 | — | — | Data limited due to global disruption. |
| 2021 | — | — | Data reporting improved. |
| 2022 | ~1,050,000,000 | ~19% | Latest comprehensive estimate. |
These numbers underscore the vast scale of the problem, and highlight the opportunity for data-driven interventions — like rescue-food tracking — to make a difference.
Conclusion
Turning raw rescue records into a structured, analyzable dataset empowers concrete, measurable efforts against food waste. Building the infrastructure to scrape the ResQ Club API for sustainability insights and manage a comprehensive food-rescue dataset unlocks transparency, supports impact measurement, and fosters accountability. For NGOs, researchers, or civic organisations committed to waste reduction and social good, this approach offers a concrete path forward. Want to evaluate different implementation strategies, run cost-benefit analysis, or compare potential outreach impact? Let’s get started with Real Data API and a full-scale deployment of data-driven food-waste reduction.
Latest posts

How Cruise Itinerary Data Analytics for Travel Insights Helps Travel Companies Predict Passenger Demand?

10 Business Decisions Powered By Real-Time Data Scraping For Business Decision Making

The Business Impact of Real-Time Retail Market Monitoring Solutions on Pricing, Inventory, and Demand Analysis

Spinning Up Insights: How Tyre Data Collection from Lazada and Tuhu Is Revolutionizing the Automotive Aftermarket
Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.







Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7


Disclaimer : RealData API functions solely as an independent data infrastructure and technology solutions provider. We build customized automation workflows designed to collect publicly accessible web data based exclusively on client instructions. RealData API neither owns proprietary datasets nor engages in the sale or redistribution of extracted information. Our operations are limited strictly to lawful public web data processing and never involve unauthorized access to restricted systems or private networks. Any company names, trademarks, logos, or brand references displayed on this website are used purely for demonstrative and illustrative purposes to showcase our technical capabilities and do not imply endorsement, partnership, or affiliation. Use of our platform and services remains subject to our Terms of Service.