

Introduction
Modern enterprises increasingly depend on automated data collection systems to power analytics, AI models, operational monitoring, and strategic decision-making. Businesses across retail, finance, healthcare, logistics, and media require scalable infrastructures capable of continuously gathering and processing large volumes of digital information. Understanding how to design a continuous data extraction pipeline is essential for organizations seeking to improve real-time intelligence and operational agility.
Continuous extraction pipelines automate the process of collecting, validating, transforming, and distributing structured information from websites, APIs, marketplaces, and digital platforms. These systems allow businesses to monitor pricing trends, customer behavior, inventory updates, market sentiment, and competitor activities with minimal manual intervention.
A reliable Web Scraping API plays a critical role in enabling high-frequency data collection and scalable extraction workflows. APIs allow enterprises to integrate extraction capabilities directly into business applications, analytics platforms, and machine learning systems.
Between 2020 and 2026, global investment in cloud analytics, automation infrastructure, and streaming technologies has accelerated rapidly. Businesses now prioritize real-time business intelligence systems that support instant insights and predictive decision-making.
By implementing scalable extraction architectures, organizations can improve operational efficiency, reduce latency, and maintain continuous visibility into fast-changing digital ecosystems.
Building Strong Foundations for Scalable Infrastructure
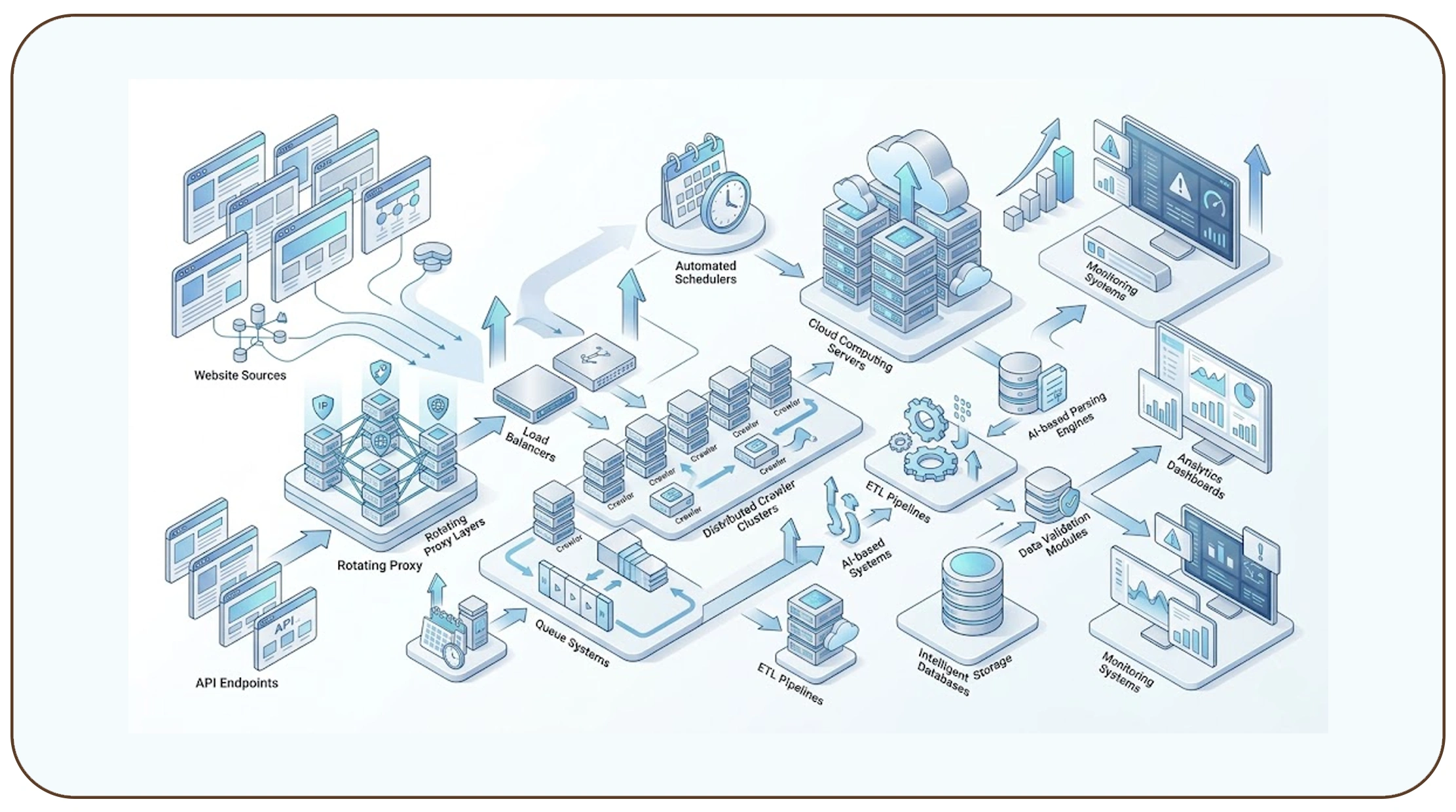
A successful extraction pipeline begins with a scalable architecture capable of handling growing data volumes, changing website structures, and high-frequency extraction schedules. Enterprises require resilient infrastructures that support continuous operations without compromising performance or reliability.
Organizations increasingly build scalable data pipelines for web scraping projects to manage millions of extraction requests across multiple sources simultaneously. These pipelines typically combine cloud infrastructure, distributed crawling systems, automated schedulers, and intelligent storage frameworks.
Global Data Pipeline Market Growth (2020–2026)
| Year | Market Size ($ Billion) |
|---|---|
| 2020 | 7.1 |
| 2021 | 8.9 |
| 2022 | 11.4 |
| 2023 | 14.2 |
| 2024 | 17.6 |
| 2025 | 21.8 |
| 2026 | 26.7 |
Modern extraction pipelines generally include:
- Distributed scraping nodes
- Cloud storage systems
- Queue management platforms
- Real-time monitoring dashboards
- Automated scheduling frameworks
- Structured transformation layers
Retailers, financial firms, and logistics companies increasingly rely on scalable infrastructures to support real-time intelligence operations. These systems process product pricing, stock updates, transaction records, and consumer behavior data continuously.
Scalability is especially important because extraction workloads fluctuate significantly during high-traffic events, promotions, or seasonal campaigns. Organizations therefore implement auto-scaling cloud environments to maintain operational consistency.
The growing adoption of hybrid cloud infrastructures between 2024 and 2026 is expected to further improve pipeline flexibility, cost optimization, and global deployment capabilities.
Enabling Continuous Streaming and Instant Insights

Businesses increasingly demand immediate access to actionable information. Traditional batch workflows are often insufficient for applications requiring instant monitoring, predictive analytics, and rapid decision-making.
A reliable real-time data pipeline architecture for scraping systems enables organizations to ingest, process, and distribute information continuously with minimal latency. These architectures are designed to support streaming analytics, automated event detection, and AI-driven intelligence systems.
Real-Time Streaming Adoption Trends (2020–2026)
| Year | Enterprises Using Streaming Pipelines |
|---|---|
| 2020 | 35% |
| 2021 | 43% |
| 2022 | 52% |
| 2023 | 61% |
| 2024 | 69% |
| 2025 | 76% |
| 2026 | 83% |
Streaming architectures commonly include:
- Event-driven processing systems
- Kafka or RabbitMQ messaging platforms
- Distributed compute engines
- Real-time validation services
- API-based delivery systems
Retail businesses use real-time extraction systems to monitor dynamic pricing and inventory changes instantly. Financial institutions analyze transaction data and market fluctuations in real time to improve trading accuracy and fraud detection.
News aggregators and media companies rely on streaming extraction infrastructures to capture trending topics and breaking updates continuously.
These architectures reduce data latency while enabling businesses to automate operational workflows and accelerate response times. The rise of AI-powered analytics further increases the importance of low-latency data delivery systems.
Real-time infrastructures are expected to remain central to enterprise intelligence strategies throughout the next decade.
Creating Reliable and Maintainable Systems
Designing a sustainable extraction pipeline requires more than speed and scalability. Long-term operational reliability, maintainability, and data consistency are equally critical for enterprise success.
Organizations increasingly adopt best practices for designing data extraction pipelines to improve resilience, reduce downtime, and optimize resource utilization. Proper design frameworks help businesses maintain consistent data quality even as extraction complexity grows.
Key Pipeline Optimization Priorities
| Priority Area | Importance |
|---|---|
| Scalability | High |
| Fault Tolerance | High |
| Data Validation | High |
| Infrastructure Cost Optimization | Medium |
| Monitoring & Alerts | High |
| API Reliability | High |
Effective extraction systems commonly implement:
- Intelligent retry handling
- Proxy rotation systems
- CAPTCHA management
- Structured data normalization
- Monitoring and alert frameworks
- Schema validation layers
Data quality remains one of the biggest challenges in large-scale extraction projects. Websites frequently change layouts, structures, and rendering methods, making adaptable parsing systems essential.
Organizations also prioritize observability tools that monitor extraction performance, API latency, and infrastructure health continuously. Automated alerting systems help engineering teams resolve failures quickly before they impact business operations.
Microservices architectures further improve maintainability by separating extraction, transformation, storage, and delivery services into independently scalable components.
As enterprise extraction demands continue growing, robust architectural design practices will become increasingly important for operational stability and long-term scalability.
Managing Data Processing and Storage Efficiently
Continuous extraction pipelines generate enormous volumes of information that must be processed, cleaned, and stored efficiently. Businesses require scalable storage environments capable of supporting both historical analysis and real-time analytics.
Modern organizations increasingly process and store scraped data in real time to improve decision-making speed and operational responsiveness. Real-time processing frameworks help businesses transform raw extraction outputs into structured intelligence instantly.
Enterprise Data Volume Growth (2020–2026)
| Year | Avg Enterprise Data Volume (Petabytes) |
|---|---|
| 2020 | 2.1 |
| 2021 | 2.8 |
| 2022 | 3.7 |
| 2023 | 4.9 |
| 2024 | 6.4 |
| 2025 | 8.2 |
| 2026 | 10.7 |
Businesses typically use:
- Cloud data warehouses
- Distributed object storage
- Streaming databases
- Data lakes
- Real-time analytics platforms
Retail organizations process inventory, pricing, and customer engagement data continuously to support personalization and demand forecasting. Financial institutions rely on high-speed storage systems to manage market intelligence and transaction monitoring workflows.
Efficient storage management also requires data deduplication, compression, indexing, and archival strategies. These techniques help businesses reduce infrastructure costs while improving query performance.
AI and machine learning applications further increase the importance of structured and continuously updated datasets. Real-time storage systems enable predictive analytics models to operate with greater accuracy and responsiveness.
The continued growth of enterprise data ecosystems will drive further investment in scalable cloud-native storage infrastructures between 2024 and 2026.
Expanding Automation Through Managed Solutions

Many organizations prefer outsourcing extraction infrastructure management to specialized providers that offer scalable and fully managed solutions. Managed services reduce engineering overhead while improving extraction consistency and operational efficiency.
Professional Web Scraping Services enable businesses to automate large-scale extraction workflows without maintaining complex internal infrastructures. These services support continuous monitoring, proxy management, anti-bot handling, and structured data delivery.
Managed Extraction Service Adoption (2020–2026)
| Year | Enterprise Adoption Rate |
|---|---|
| 2020 | 31% |
| 2021 | 39% |
| 2022 | 47% |
| 2023 | 56% |
| 2024 | 64% |
| 2025 | 72% |
| 2026 | 80% |
Managed service providers commonly offer:
- Scalable extraction infrastructure
- Automated browser rendering
- Distributed crawling systems
- Data normalization services
- API integrations
- Real-time monitoring support
Retailers, travel platforms, and market intelligence firms frequently use managed services to collect competitor pricing, inventory updates, and consumer behavior data continuously.
Outsourcing extraction operations also allows businesses to focus internal resources on analytics, strategy, and product development rather than infrastructure maintenance.
As anti-bot technologies and website complexity continue increasing, managed service providers are expected to play an even larger role in enterprise data ecosystems over the next several years.
Supporting Large-Scale Discovery and Monitoring

Continuous extraction systems often require enterprise-scale crawling infrastructures capable of discovering and monitoring millions of web pages simultaneously. Large-scale crawling enables organizations to maintain broad visibility across rapidly changing digital ecosystems.
Advanced Enterprise Web Crawling systems support continuous indexing, monitoring, and discovery operations across marketplaces, news portals, social platforms, and business websites. These systems are critical for search engines, analytics firms, cybersecurity platforms, and AI training operations.
Enterprise Crawling Infrastructure Growth (2020–2026)
| Year | Enterprises Using Large-Scale Crawlers |
|---|---|
| 2020 | 37% |
| 2021 | 45% | 2022 | 53% |
| 2023 | 61% |
| 2024 | 68% |
| 2025 | 75% |
| 2026 | 82% |
Enterprise crawling platforms typically include:
- Distributed crawling agents
- Dynamic rendering engines
- URL prioritization systems
- AI-driven content classification
- Automated scheduling frameworks
Retail and eCommerce businesses use crawling systems to monitor competitor catalogs, promotions, and product availability across multiple regions.
Financial organizations crawl market news, investment reports, and economic indicators to improve predictive analysis and trading strategies.
AI-driven crawling technologies increasingly help businesses identify high-value content, optimize crawl efficiency, and reduce infrastructure overhead.
The combination of large-scale crawling and real-time extraction is becoming essential for organizations seeking continuous visibility into rapidly evolving digital environments.
Why Choose Real Data API?
Real Data API provides enterprise-grade extraction and monitoring solutions designed for modern business intelligence environments. Organizations looking to understand how to design a continuous data extraction pipeline require scalable infrastructures capable of supporting high-frequency extraction, real-time processing, and automated delivery systems.
The platform offers advanced extraction technologies, scalable crawling systems, and structured Web Scraping Datasets optimized for analytics, AI models, and enterprise reporting workflows.
Key advantages include:
- Scalable cloud-based infrastructure
- Real-time extraction and delivery
- Automated proxy and anti-block handling
- API-first integration support
- Structured data normalization
- Enterprise monitoring capabilities
- High-volume crawling support
Real Data API helps businesses automate data collection, improve operational efficiency, and accelerate intelligent decision-making across competitive digital markets.
Conclusion
Understanding how to design a continuous data extraction pipeline is essential for businesses seeking scalable, real-time, and automated intelligence systems. Modern enterprises require flexible architectures capable of supporting high-frequency extraction, streaming analytics, and AI-driven decision-making.
Between 2020 and 2026, the rapid expansion of digital ecosystems, cloud computing, and AI technologies continues driving demand for continuous extraction infrastructures. Organizations that successfully implement scalable pipelines can improve operational agility, reduce manual effort, and gain deeper visibility into competitive markets.
From real-time processing to enterprise crawling and managed extraction services, continuous pipelines now play a foundational role in modern business intelligence strategies.
Ready to build scalable real-time extraction systems for your business? Connect with Real Data API today and create intelligent, high-performance data pipelines designed for continuous business intelligence and growth!
Latest posts
Why Brands Use Competitive Data Intelligence to Increase Market Share in Highly Competitive Markets?

How To Scrape Competitor Data To Support Market Entry Strategy And Expansion Planning For Data-Driven Business Growth?

How Hotel Occupancy Intelligence Through Public Data Sources Is Reshaping Revenue Management

The ZIP Code Advantage: How Hyper-Local Amazon Product Data Collection Is Redefining Retail Intelligence
Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.







Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7


Disclaimer : RealData API functions solely as an independent data infrastructure and technology solutions provider. We build customized automation workflows designed to collect publicly accessible web data based exclusively on client instructions. RealData API neither owns proprietary datasets nor engages in the sale or redistribution of extracted information. Our operations are limited strictly to lawful public web data processing and never involve unauthorized access to restricted systems or private networks. Any company names, trademarks, logos, or brand references displayed on this website are used purely for demonstrative and illustrative purposes to showcase our technical capabilities and do not imply endorsement, partnership, or affiliation. Use of our platform and services remains subject to our Terms of Service.