

Introduction
Businesses today depend heavily on real-time data for competitive analysis, SEO monitoring, pricing intelligence, lead generation, market research, and customer behavior analysis. Web scraping has become one of the most effective methods for collecting publicly available online information at scale. However, as websites implement stricter anti-bot systems and server protection mechanisms, organizations must focus on efficient and ethical crawling techniques to avoid detection, IP blocking, and performance disruptions.
This is where Rate limiting and request optimization strategies for web scraping become essential. Rate limiting helps control the number of requests sent to a target website within a defined time period, while request optimization improves how crawlers interact with websites to maximize efficiency and reduce unnecessary traffic.
Modern businesses use intelligent scheduling, adaptive throttling, proxy rotation, and AI-driven optimization systems to improve crawling performance while reducing server strain. These techniques allow enterprises to maintain stable data extraction workflows without negatively affecting website performance.
Organizations also increasingly rely on scalable Web Scraping API solutions to simplify infrastructure management and improve automation reliability. API-driven scraping systems provide structured extraction environments that support efficient request handling, compliance-focused operations, and enterprise-grade scalability.
This guide explains how optimized request management improves crawling efficiency, reduces detection risks, supports automation scalability, and enables businesses to build sustainable data extraction ecosystems between 2020 and 2026.
Smarter Infrastructure for High-Volume Crawling
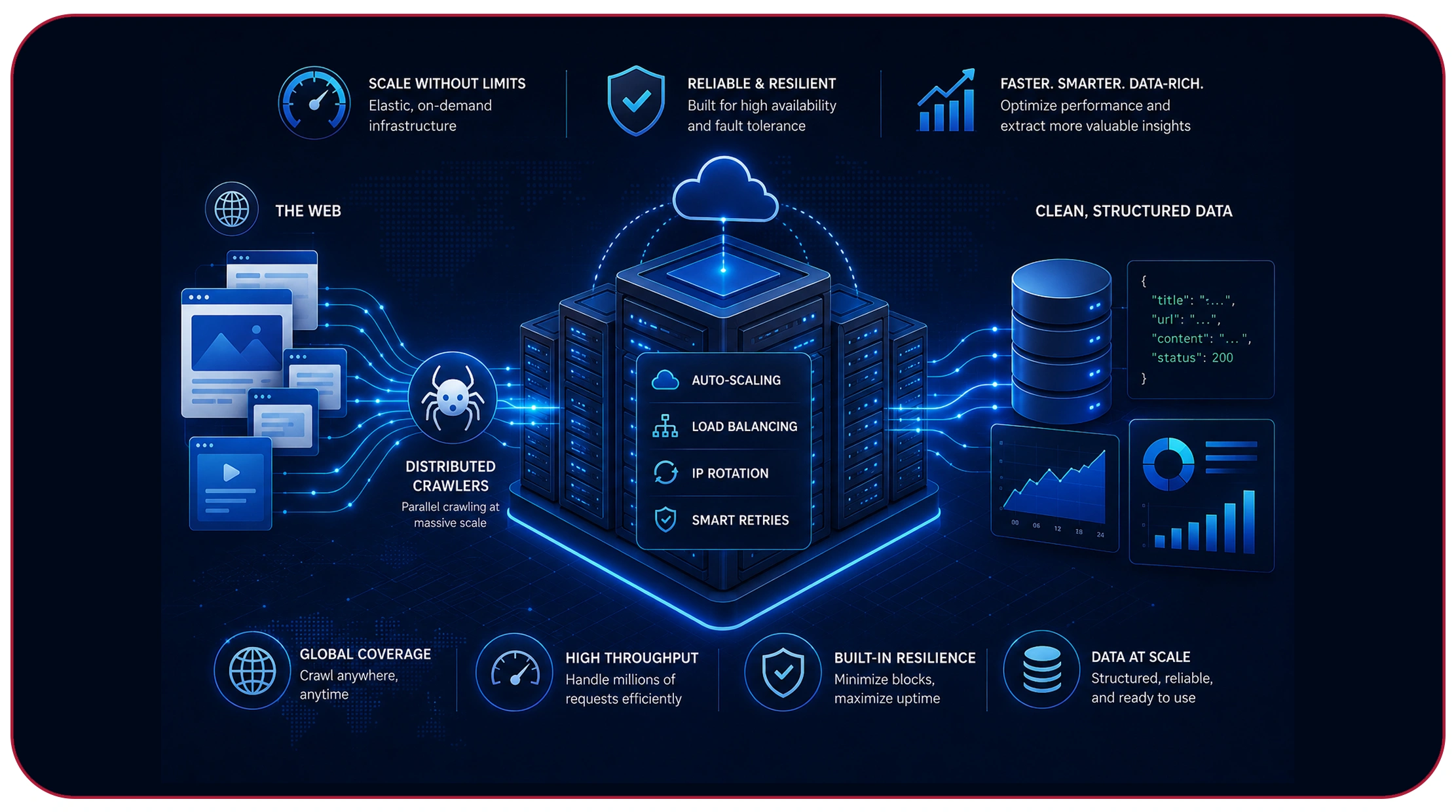
Large-scale data extraction requires intelligent infrastructure capable of balancing speed, scalability, and responsible crawling behavior. One of the most important advancements in enterprise automation is enterprise scraping infrastructure with intelligent rate limiting, which helps organizations maintain efficient operations while minimizing server overload and blocking risks.
Traditional scraping systems often rely on aggressive request patterns that trigger anti-bot protections and lead to incomplete datasets. Intelligent rate limiting solves this problem by dynamically adjusting request frequency based on website response behavior, traffic patterns, and server conditions.
From 2020 to 2026, enterprise adoption of intelligent rate-limiting infrastructure increased significantly as organizations expanded their automation capabilities.
| Year | Enterprise Scraping Adoption | Intelligent Rate Limiting Usage | Blocking Reduction |
|---|---|---|---|
| 2020 | 34% | 22% | 18% |
| 2021 | 41% | 29% | 25% |
| 2022 | 48% | 37% | 33% |
| 2023 | 56% | 45% | 41% |
| 2024 | 63% | 53% | 48% |
| 2025 | 69% | 61% | 54% |
| 2026 | 75% | 68% | 61% |
Intelligent infrastructure also improves operational scalability by distributing requests across multiple sessions, proxies, and geographic regions. Businesses using adaptive request scheduling experience fewer interruptions and improved extraction stability.
Modern scraping platforms integrate machine learning algorithms that automatically optimize request timing according to server response latency. This reduces failed requests and improves overall crawling performance.
As enterprise data operations continue expanding, scalable infrastructure with intelligent rate limiting will become essential for maintaining efficient and sustainable web scraping systems.
Minimizing Traffic Pressure on Target Websites
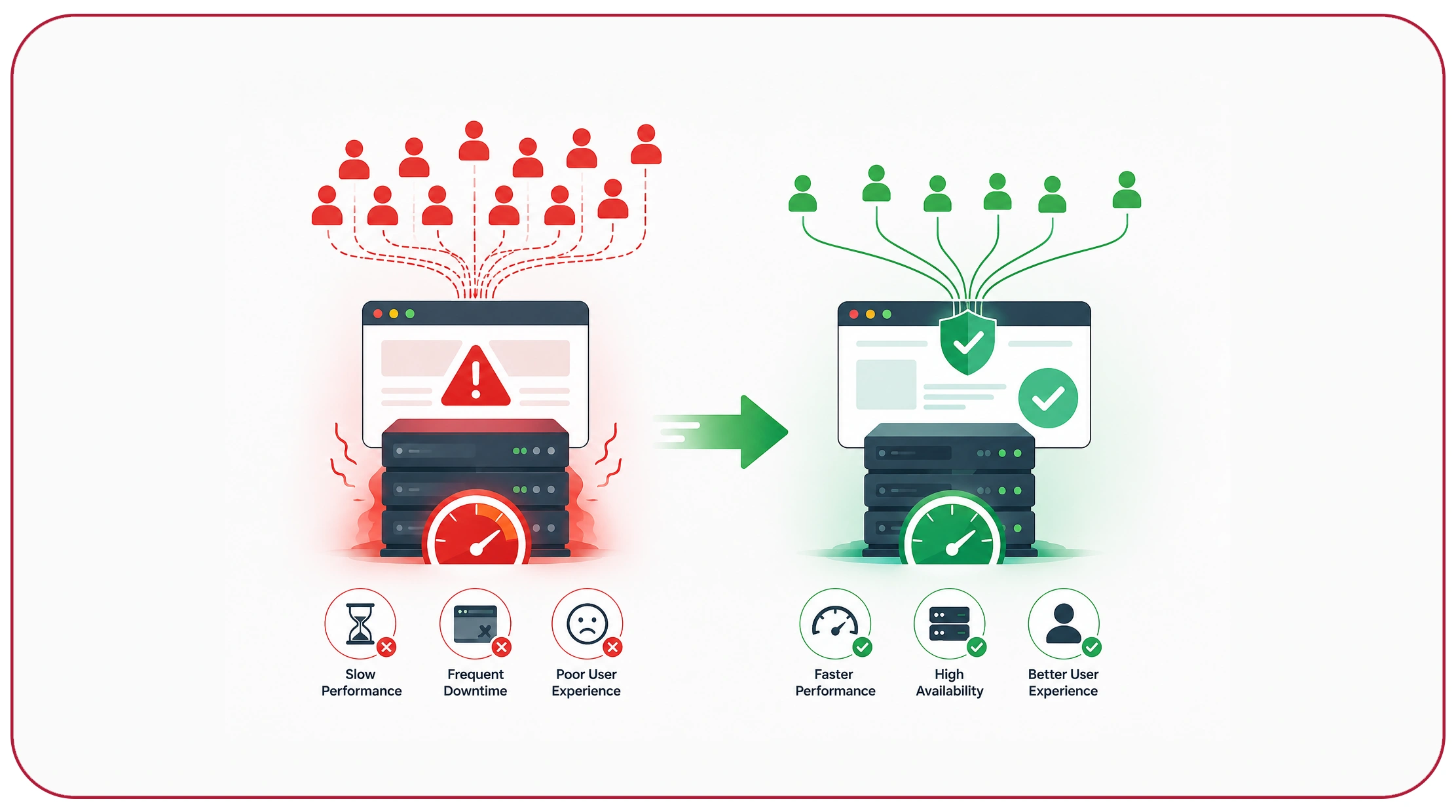
Responsible data extraction requires balancing operational efficiency with server stability. Businesses that overload websites with excessive requests often experience blocking, reduced data quality, and inconsistent scraping performance. This has increased the importance of strategies designed to reduce server load during automated data extraction.
Request optimization helps organizations minimize unnecessary traffic by targeting only relevant pages, filtering duplicate requests, and implementing efficient extraction workflows. Smart crawlers also use caching systems and incremental scraping methods to avoid repeatedly requesting identical content.
Industry reports from 2020–2026 show that businesses implementing optimized traffic management systems experienced significantly lower rejection rates and higher data reliability.
| Optimization Method | Server Load Reduction | Crawling Stability Improvement |
|---|---|---|
| Incremental Crawling | 42% | 37% |
| Selective Page Targeting | 39% | 31% |
| Intelligent Caching | 35% | 28% |
| Adaptive Scheduling | 44% | 36% |
| Retry Optimization | 33% | 25% |
Reducing server pressure is not only an ethical practice but also a technical advantage. Websites experiencing lower crawler strain are less likely to trigger anti-bot systems or restrict access to automated requests.
Businesses also increasingly deploy distributed scraping architectures that spread requests across multiple endpoints to avoid traffic concentration. These systems improve extraction reliability while reducing the risk of server overload.
Organizations focusing on optimized crawling strategies achieve better operational efficiency, stronger scalability, and more sustainable long-term data collection capabilities.
Building Adaptive Request Management Systems
Modern web scraping operations depend heavily on intelligent request control systems that optimize extraction speed while minimizing detection risks. One of the most effective approaches involves implementing request throttling techniques for web crawlers to improve stability and maintain ethical crawling behavior.
Request throttling controls how frequently crawlers interact with websites. Instead of sending continuous high-volume requests, throttling systems gradually distribute traffic over time based on server conditions and response patterns.
Between 2020 and 2026, organizations adopting adaptive throttling technologies reported major improvements in uptime reliability and reduced IP blocking incidents.
| Throttling Strategy | Blocking Reduction | Request Efficiency Gain |
|---|---|---|
| Dynamic Delays | 41% | 34% |
| Traffic Balancing | 38% | 29% |
| AI-Based Scheduling | 45% | 37% |
| Session Rotation | 43% | 33% |
| Intelligent Retry Logic | 36% | 27% |
Adaptive throttling systems are particularly valuable for enterprise scraping environments handling millions of requests daily. These systems continuously analyze response behavior and adjust request timing automatically.
Organizations also use distributed proxy pools combined with throttling mechanisms to maintain stable extraction performance across multiple geographic regions. This improves scalability while reducing request concentration on individual servers.
Another important advantage of request throttling is improved data quality. Websites are more likely to return complete and accurate information when crawlers interact at sustainable request rates.
Businesses implementing advanced throttling frameworks gain stronger operational resilience and more reliable automation performance in competitive digital environments.
Automation Technologies Driving Enterprise Efficiency
Automation continues transforming enterprise data operations across industries including finance, retail, healthcare, logistics, and eCommerce. One major driver of this transformation is Robotic Process Automation, which enables businesses to automate repetitive extraction workflows and improve operational productivity.
RPA systems automate browser interactions, data entry, report generation, and extraction processes with minimal human intervention. From 2020 to 2026, organizations increasingly integrated RPA into web scraping workflows to improve efficiency and reduce operational costs.
| Year | RPA Adoption Rate | Automated Extraction Tasks | Productivity Improvement |
|---|---|---|---|
| 2020 | 31% | 24% | 18% |
| 2021 | 38% | 29% | 23% |
| 2022 | 45% | 36% | 31% |
| 2023 | 53% | 44% | 39% |
| 2024 | 61% | 51% | 46% |
| 2025 | 68% | 58% | 54% |
| 2026 | 74% | 65% | 61% |
Automation technologies improve consistency and reduce manual errors in high-volume extraction environments. Modern RPA systems also integrate with AI platforms, APIs, and cloud infrastructure to support enterprise scalability.
Businesses using automation-driven request optimization systems can dynamically manage crawl scheduling, prioritize high-value content, and improve extraction reliability.
However, organizations must ensure automation systems operate responsibly and avoid excessive traffic generation. Combining RPA with intelligent throttling and optimization frameworks helps maintain sustainable scraping performance while reducing operational risks.
As automation technologies continue advancing, enterprises using optimized RPA-driven extraction systems will gain significant competitive advantages in large-scale data operations.
Artificial Intelligence and Predictive Crawling Systems
Artificial intelligence is revolutionizing how enterprises manage web scraping infrastructure and optimize large-scale extraction operations. One of the most influential technologies driving this evolution is Generative AI, which enables intelligent, adaptive, and predictive crawling systems.
From 2020 to 2026, enterprises rapidly increased AI integration across automation workflows to improve extraction accuracy, reduce manual intervention, and optimize request efficiency.
| AI Capability | Efficiency Improvement | Data Accuracy Increase |
|---|---|---|
| Predictive Crawl Scheduling | 43% | 36% |
| Intelligent Content Recognition | 46% | 41% |
| Automated Error Recovery | 37% | 29% |
| AI-Based Request Optimization | 44% | 38% |
| Dynamic Response Analysis | 39% | 32% |
AI-powered scraping systems can monitor server response behavior in real time and automatically adjust crawling frequency to avoid triggering anti-bot systems. These systems also detect structural website changes and adapt extraction logic dynamically.
Generative AI further enhances automation workflows by summarizing extracted datasets, categorizing information, generating reports, and identifying trends within large-scale digital environments.
Businesses increasingly rely on AI-driven scraping systems for SEO intelligence, competitor analysis, market forecasting, and customer sentiment monitoring.
Despite these advancements, organizations must continue following ethical crawling standards and responsible traffic management practices. AI-powered optimization works best when combined with sustainable and compliance-focused extraction frameworks.
As AI technologies mature, predictive crawling systems will become a central component of enterprise data intelligence infrastructure.
Scalable Data Extraction for Modern Businesses

Organizations operating in data-driven industries require reliable infrastructure capable of handling large-scale extraction workflows efficiently. This has increased global demand for enterprise-grade Web Scraping Services that combine scalability, automation, and intelligent request optimization.
Professional scraping services provide businesses with managed extraction systems that include proxy rotation, adaptive throttling, intelligent scheduling, and AI-powered monitoring capabilities. These services help organizations reduce operational complexity while improving extraction reliability.
Between 2020 and 2026, adoption of managed scraping services grew steadily as enterprises expanded digital intelligence operations.
| Year | Managed Scraping Adoption | Enterprise Data Demand | Automation Scalability Growth |
|---|---|---|---|
| 2020 | 29% | 36% | 24% |
| 2021 | 35% | 43% | 31% |
| 2022 | 42% | 51% | 39% |
| 2023 | 50% | 58% | 47% |
| 2024 | 57% | 65% | 54% |
| 2025 | 64% | 72% | 61% |
| 2026 | 71% | 78% | 68% |
Managed scraping solutions also improve request optimization by continuously analyzing extraction performance and adjusting crawl behavior dynamically.
Businesses using enterprise scraping services benefit from higher uptime, lower maintenance requirements, and more consistent data delivery. These platforms also simplify infrastructure management and support faster deployment across global operations.
As online ecosystems become increasingly complex, scalable extraction services with intelligent request optimization will remain essential for businesses seeking reliable and sustainable access to public web data.
Why Choose Real Data API?
Modern enterprises require scalable and performance-focused extraction infrastructure capable of handling complex automation workflows efficiently. Real Data API delivers advanced scraping solutions designed to support intelligent crawling, adaptive request management, and large-scale automation environments.
Our platform specializes in Rate limiting and request optimization strategies for web scraping, helping businesses improve crawling efficiency while reducing server strain and blocking risks. We provide enterprise-grade infrastructure that supports adaptive scheduling, proxy management, AI-powered optimization, and distributed extraction systems.
Real Data API also offers secure and scalable solutions for SEO monitoring, competitor intelligence, pricing analysis, market research, and lead generation operations. Our infrastructure is designed to improve extraction reliability while simplifying automation management for modern businesses.
Whether organizations require high-volume scraping, real-time intelligence collection, or scalable automation support, Real Data API delivers optimized extraction systems built for long-term performance and operational scalability.
Conclusion
As digital ecosystems continue evolving, businesses must adopt smarter and more sustainable scraping strategies to maintain reliable access to online data. Efficient request management, adaptive throttling, intelligent scheduling, and AI-powered optimization systems are now essential components of modern automation infrastructure.
Developing expertise in Rate limiting and request optimization strategies for web scraping helps organizations improve crawling efficiency, reduce server strain, avoid blocking risks, and achieve scalable long-term data extraction performance.
From enterprise automation frameworks to AI-driven crawling systems, optimized request management is shaping the future of large-scale digital intelligence operations. Businesses that prioritize responsible and efficient scraping practices will gain stronger scalability, higher-quality datasets, and improved operational resilience in increasingly competitive markets.
Ready to optimize your web scraping infrastructure? Partner with Real Data API for scalable, intelligent, and enterprise-ready data extraction solutions today!
Latest posts

Web Scraping Competitor Product Monitoring Using Marketplace Data for Real-Time E-commerce Insights and Business Growth?

How to Scrape Product Intelligence Platform Using Marketplace Data to Help Brands Optimize Pricing, Inventory, and Product Strategy?

Why Companies scrape business data from Google Maps using keywords to Build Accurate Business Lists and Competitive Insights?

How Review scraping and monitoring services Help Businesses Track Customer Sentiment and Protect Brand Reputation in 2026?

How Real Estate Investment Insights Using RERA Data Scraping Help Investors Minimize Risk and Maximize Returns
Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.







Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7


Disclaimer : RealData API functions solely as an independent data infrastructure and technology solutions provider. We build customized automation workflows designed to collect publicly accessible web data based exclusively on client instructions. RealData API neither owns proprietary datasets nor engages in the sale or redistribution of extracted information. Our operations are limited strictly to lawful public web data processing and never involve unauthorized access to restricted systems or private networks. Any company names, trademarks, logos, or brand references displayed on this website are used purely for demonstrative and illustrative purposes to showcase our technical capabilities and do not imply endorsement, partnership, or affiliation. Use of our platform and services remains subject to our Terms of Service.