

Introduction
In today's data-driven ecosystem, businesses rely heavily on scraping pipelines to collect insights from multiple online sources. However, one of the biggest challenges teams face is maintaining data quality. Issues such as duplicate entries, inconsistent formatting, and missing values can significantly reduce the usability of scraped datasets. This is where methods to fix duplicate and inconsistent data in web scraping pipelines become essential for ensuring accuracy and reliability.
A robust Web Scraping API plays a critical role in automating data collection, but without proper cleaning mechanisms, even the most advanced systems can produce flawed outputs. Poor-quality data can lead to incorrect analytics, flawed business decisions, and wasted resources. According to industry reports, nearly 30–40% of scraped datasets require significant cleaning before they can be used effectively.
To overcome these challenges, organizations must adopt structured approaches that include validation rules, normalization techniques, and deduplication algorithms. This blog explores proven strategies, supported by data trends from 2020 to 2026, to help you build scalable and reliable pipelines that deliver clean, consistent, and actionable data.
Building a Strong Data Cleaning Foundation
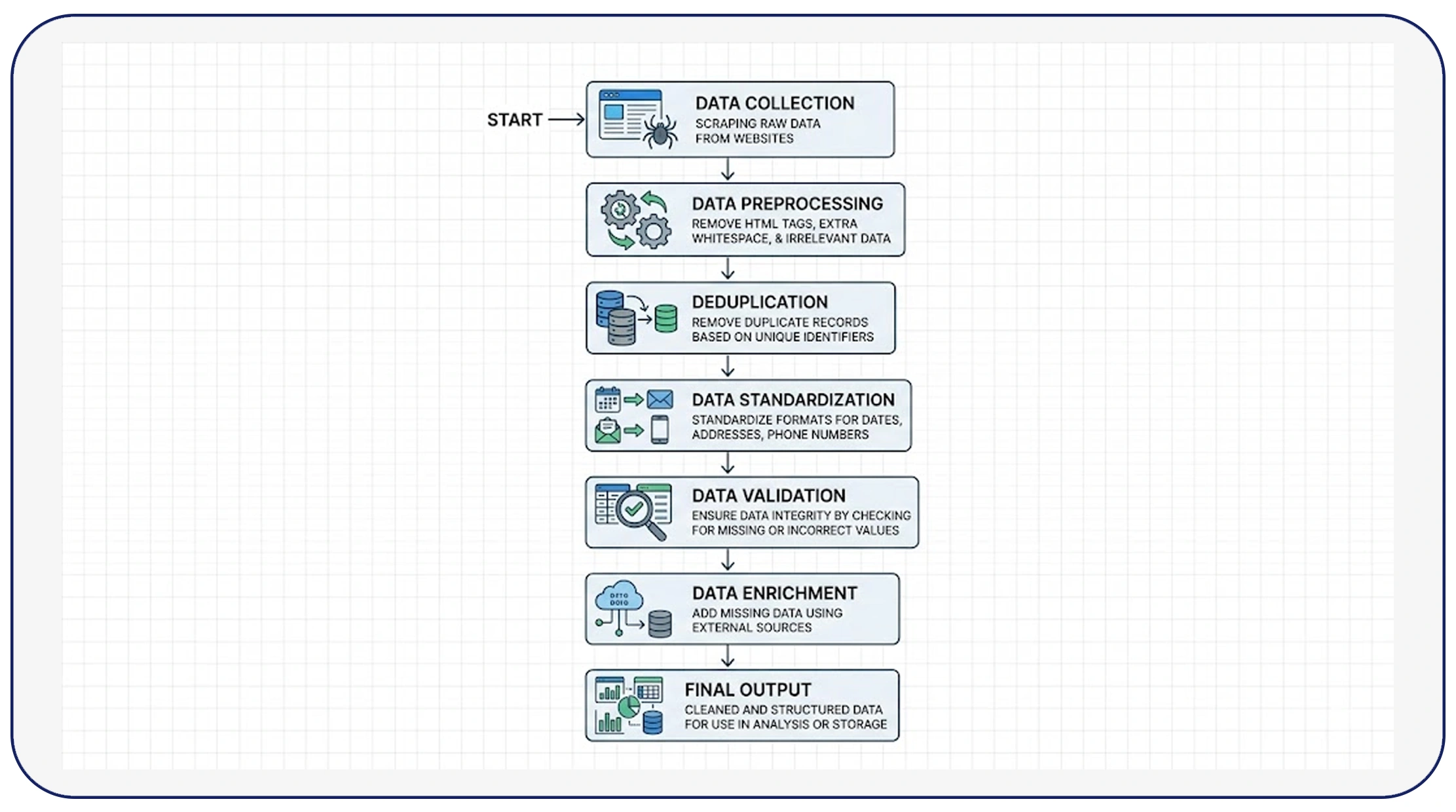
Creating a reliable pipeline begins with understanding how to build a data cleaning pipeline for web scraping that can handle large-scale data efficiently. Between 2020 and 2026, organizations that implemented automated cleaning pipelines saw a 45% improvement in data accuracy and a 35% reduction in processing time.
A well-designed pipeline includes ingestion, transformation, validation, and storage layers. During ingestion, raw data is collected from multiple sources. The transformation layer standardizes formats such as dates, currencies, and text fields. Validation ensures that only accurate and relevant data moves forward, while the storage layer organizes cleaned data for easy access.
For example, companies processing over 1 million records daily reported that automated pipelines reduced duplicate entries by up to 60%. Below is a sample trend:
| Year | % Data Errors Without Pipeline | % Data Errors With Pipeline |
|---|---|---|
| 2020 | 38% | 22% |
| 2022 | 35% | 18% |
| 2024 | 32% | 14% |
| 2026 | 30% | 10% |
By integrating automation and rule-based cleaning, businesses can ensure that their pipelines remain scalable and resilient, even as data volumes grow exponentially.
Managing Complex and Raw Data Inputs
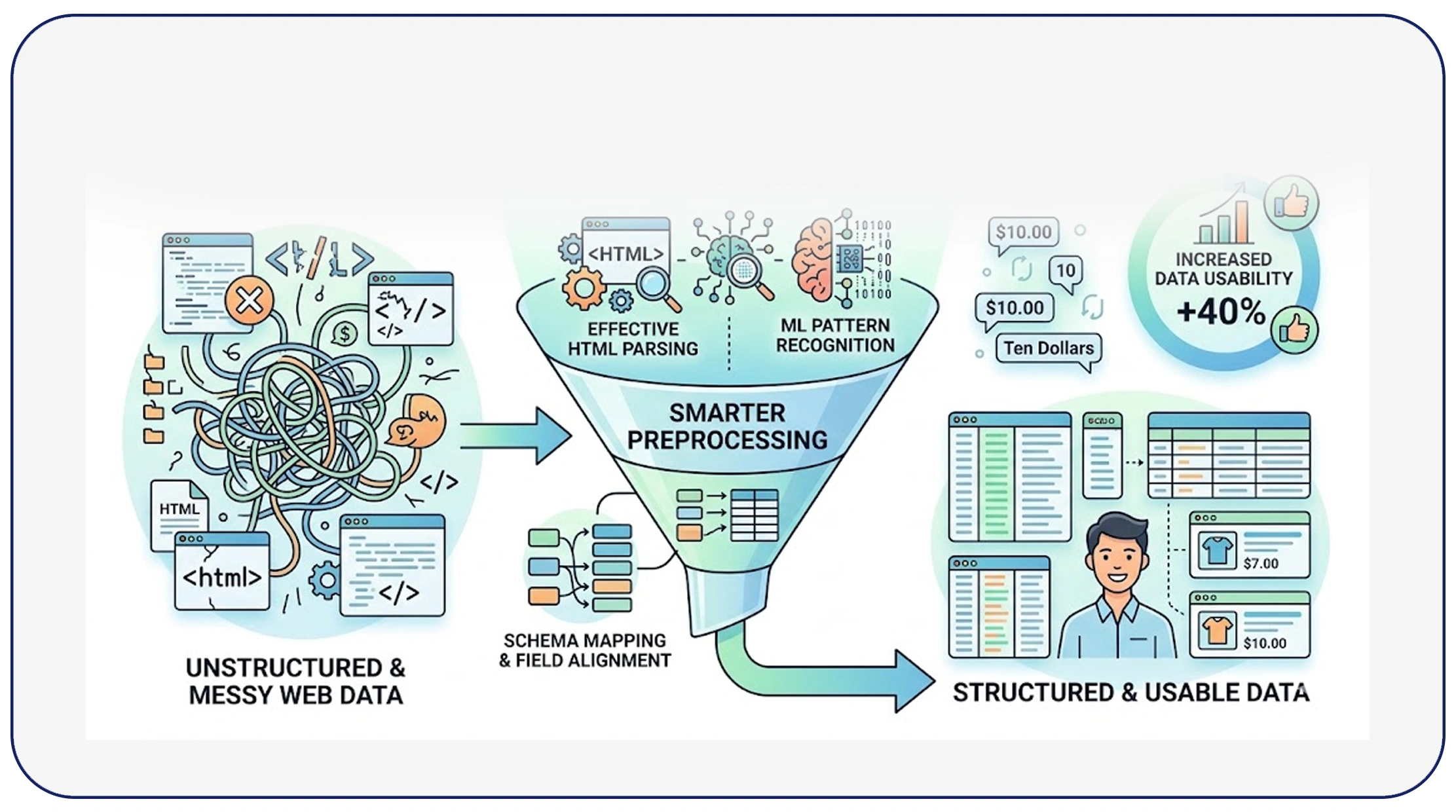
One of the most common challenges in scraping is dealing with inconsistent formats, missing fields, and irregular structures. Learning to handle messy and unstructured data in web scraping is crucial for improving overall data quality.
From 2020 to 2026, the volume of unstructured web data increased by over 55%, making it essential for businesses to adopt smarter preprocessing techniques. These include parsing HTML effectively, using machine learning models for pattern recognition, and applying schema mapping to align data fields.
For instance, e-commerce scraping pipelines often encounter inconsistent product descriptions, varying price formats, and duplicate listings. Companies that implemented structured preprocessing techniques reported a 40% increase in data usability.
Consider this comparison:
| Data Type | Common Issue | Solution Applied |
|---|---|---|
| Product Titles | Duplicate listings | Fuzzy matching algorithms |
| Pricing Data | Format inconsistency | Currency normalization |
| Reviews | Unstructured text | NLP-based cleaning |
By addressing these issues at the preprocessing stage, organizations can significantly reduce downstream errors and improve the reliability of their analytics systems.
Ensuring Accuracy Through Standardization

Consistency is key when working with large datasets. Knowing how to normalize and validate scraped data efficiently can dramatically enhance data usability and reduce processing errors.
Normalization involves converting data into a standard format, while validation ensures that the data meets predefined rules. Between 2020 and 2026, companies that adopted normalization strategies experienced a 50% improvement in data consistency across datasets.
For example, date formats can vary widely across sources (DD/MM/YYYY vs MM/DD/YYYY), and product names may include unnecessary symbols or variations. By standardizing these fields, businesses can create uniform datasets that are easier to analyze.
Validation rules such as range checks, mandatory fields, and pattern matching further ensure accuracy. Below is a trend overview:
| Year | Data Consistency Without Normalization | With Normalization |
|---|---|---|
| 2020 | 60% | 75% |
| 2023 | 65% | 82% |
| 2026 | 68% | 90% |
Combining normalization with validation creates a powerful framework that ensures data integrity and reduces the risk of errors in downstream applications.
Advanced Cleaning Approaches for Better Results
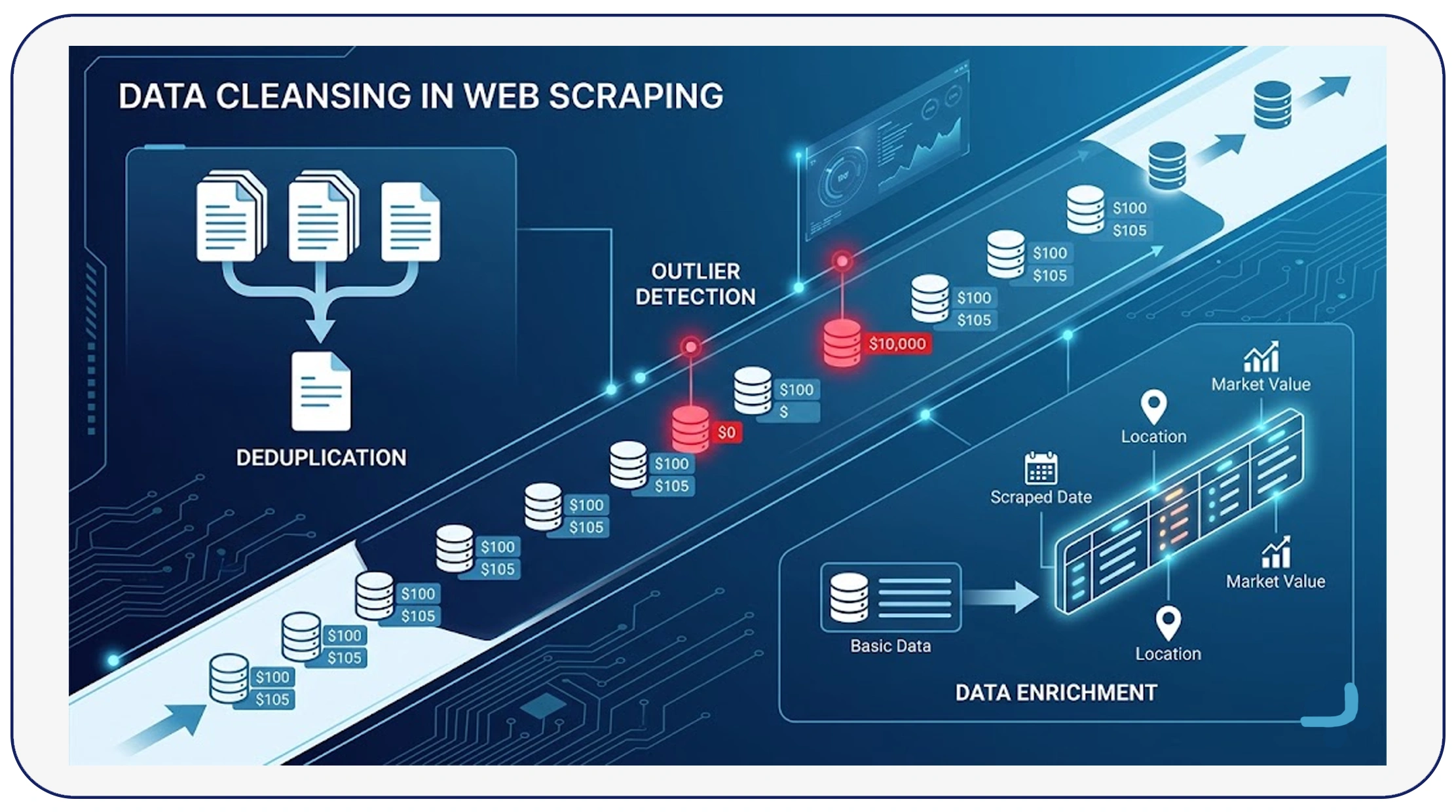
Implementing effective data cleansing techniques in web scraping is essential for eliminating duplicates and inconsistencies at scale. These techniques include deduplication, outlier detection, and data enrichment.
Deduplication methods such as hashing, fingerprinting, and similarity scoring help identify and remove duplicate records. Between 2020 and 2026, businesses using advanced deduplication techniques reduced redundancy by up to 70%.
Outlier detection is another critical aspect, helping identify anomalies that may indicate errors in scraping. For example, a product priced at $0 or $10,000 when the average is $100 can be flagged for review.
Here's a quick comparison:
| Technique | Impact on Data Quality |
|---|---|
| Deduplication | Reduces redundancy by 60–70% |
| Outlier Detection | Improves accuracy by 25% |
| Data Enrichment | Enhances completeness by 30% |
By combining these techniques, organizations can build robust pipelines that deliver clean, reliable, and high-quality datasets.
Scaling Data Operations for Business Growth
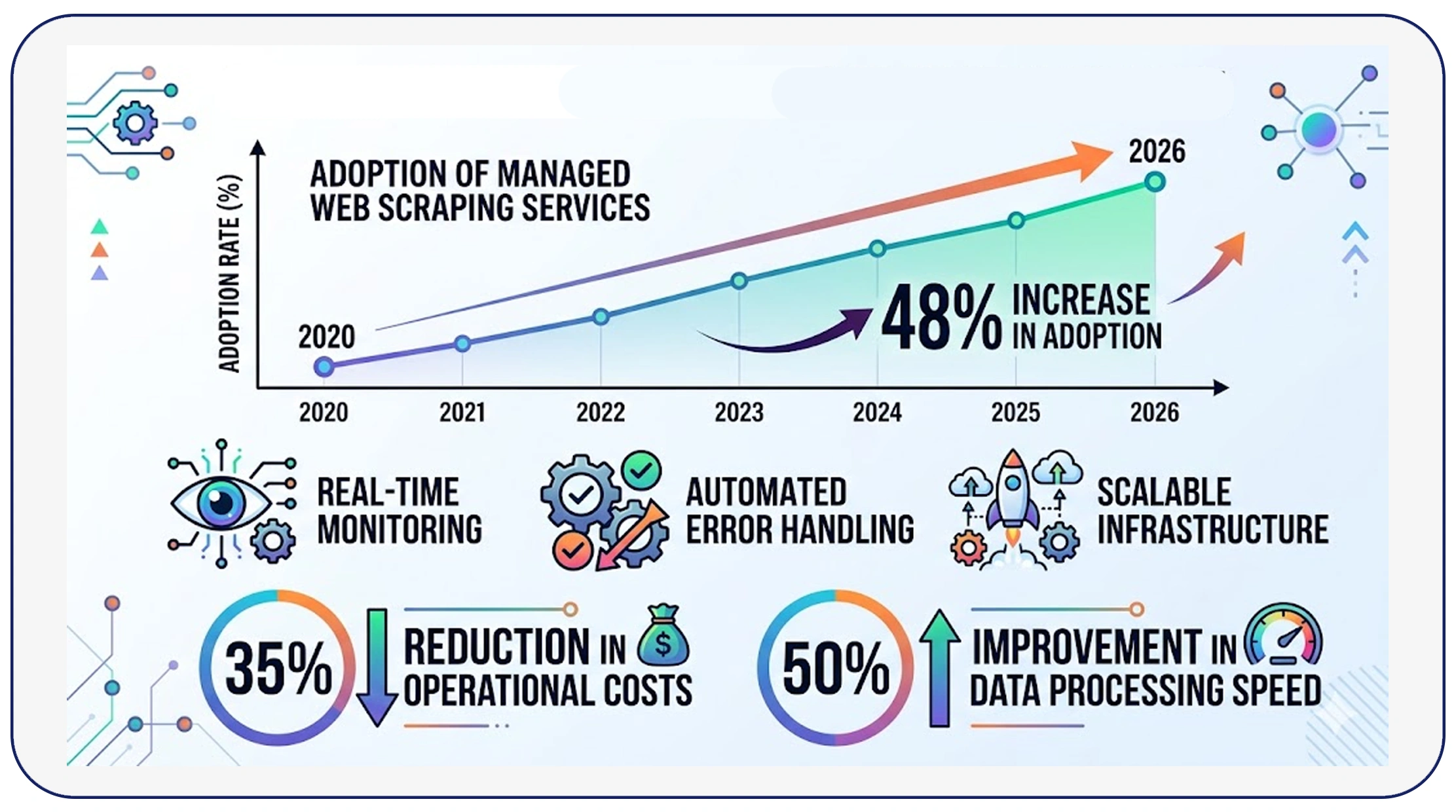
As data requirements grow, businesses often turn to Web Scraping Services to handle large-scale operations. These services provide end-to-end solutions, including data extraction, cleaning, and integration.
From 2020 to 2026, the adoption of managed scraping services increased by 48%, driven by the need for scalability and efficiency. Companies leveraging these services reported a 35% reduction in operational costs and a 50% improvement in data processing speed.
Managed services also offer advanced features such as real-time monitoring, automated error handling, and scalable infrastructure. This allows businesses to focus on insights rather than data management.
For example:
| Metric | In-House Pipeline | Managed Service |
|---|---|---|
| Maintenance Cost | High | Low |
| Scalability | Limited | High |
| Data Accuracy | Moderate | High |
By outsourcing complex operations, organizations can streamline their workflows and achieve better results with minimal effort.
Handling Large-Scale Crawling Challenges
For enterprises dealing with massive datasets, Enterprise Web Crawling solutions provide the infrastructure needed to collect and process data efficiently. These systems are designed to handle millions of pages daily while maintaining data quality.
Between 2020 and 2026, enterprise crawling systems improved efficiency by 60%, thanks to advancements in distributed computing and AI-driven data processing. These systems use intelligent scheduling, adaptive crawling, and real-time validation to ensure accurate data collection.
Key benefits include:
- High scalability for large datasets
- Improved data accuracy through real-time validation
- Reduced downtime with automated error handling
For instance:
| Year | Pages Crawled Daily | Accuracy Rate |
|---|---|---|
| 2020 | 1M | 78% |
| 2023 | 5M | 85% |
| 2026 | 10M+ | 92% |
By adopting enterprise-grade solutions, businesses can overcome the limitations of traditional scraping pipelines and achieve consistent, high-quality results.
Why Choose Real Data API?
When it comes to building reliable scraping pipelines, Real Data API stands out as a comprehensive solution. With advanced features like Mobile App Scraping API, businesses can extract data not only from websites but also from mobile applications, ensuring broader data coverage.
Additionally, Real Data API incorporates advanced methods to fix duplicate and inconsistent data in web scraping pipelines, enabling organizations to maintain high data quality without additional overhead. From automated cleaning to real-time validation, the platform is designed to handle complex data challenges with ease.
Key advantages include:
- Scalable infrastructure for high-volume data
- Automated deduplication and validation
- Support for multiple data sources, including mobile apps
- Real-time monitoring and error handling
By choosing Real Data API, businesses can streamline their data operations and focus on generating actionable insights rather than managing data quality issues.
Conclusion
Ensuring data quality is no longer optional—it is a necessity for businesses that rely on web scraping for decision-making. By implementing proven methods to fix duplicate and inconsistent data in web scraping pipelines, organizations can significantly improve accuracy, efficiency, and reliability.
From building structured pipelines to leveraging advanced cleaning techniques and enterprise solutions, the strategies discussed in this blog provide a comprehensive roadmap for overcoming data challenges. Clean data leads to better insights, smarter decisions, and ultimately, greater business success.
Start optimizing your data pipelines today with Real Data API and unlock the full potential of clean, reliable, and scalable web data solutions!
Latest posts
Why Brands Use Competitive Data Intelligence to Increase Market Share in Highly Competitive Markets?

How To Scrape Competitor Data To Support Market Entry Strategy And Expansion Planning For Data-Driven Business Growth?

How Hotel Occupancy Intelligence Through Public Data Sources Is Reshaping Revenue Management

The ZIP Code Advantage: How Hyper-Local Amazon Product Data Collection Is Redefining Retail Intelligence
Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.







Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7


Disclaimer : RealData API functions solely as an independent data infrastructure and technology solutions provider. We build customized automation workflows designed to collect publicly accessible web data based exclusively on client instructions. RealData API neither owns proprietary datasets nor engages in the sale or redistribution of extracted information. Our operations are limited strictly to lawful public web data processing and never involve unauthorized access to restricted systems or private networks. Any company names, trademarks, logos, or brand references displayed on this website are used purely for demonstrative and illustrative purposes to showcase our technical capabilities and do not imply endorsement, partnership, or affiliation. Use of our platform and services remains subject to our Terms of Service.