

Introduction
In today's hyper-competitive digital commerce landscape, businesses deal with massive volumes of product information scattered across marketplaces, brand websites, and supplier databases. To stay competitive, companies must build a centralized product catalog using scraped data that consolidates information into a single, reliable source of truth. This approach not only enhances data accuracy but also accelerates Product Development by providing structured, real-time insights into product trends, pricing strategies, and customer preferences.
From 2020 to 2026, global eCommerce data volume has grown by over 150%, driven by marketplace expansion and cross-border trade. Managing this data manually is inefficient and error-prone. By leveraging automated scraping and integration pipelines, organizations can unify product attributes such as descriptions, SKUs, images, and prices. This enables seamless decision-making, better inventory control, and improved omnichannel experiences.
A centralized catalog powered by scraped data is no longer optional—it's essential. Businesses that implement it effectively gain a strategic advantage by transforming fragmented data into actionable intelligence that drives growth and innovation.
Unifying Disparate Product Data Streams
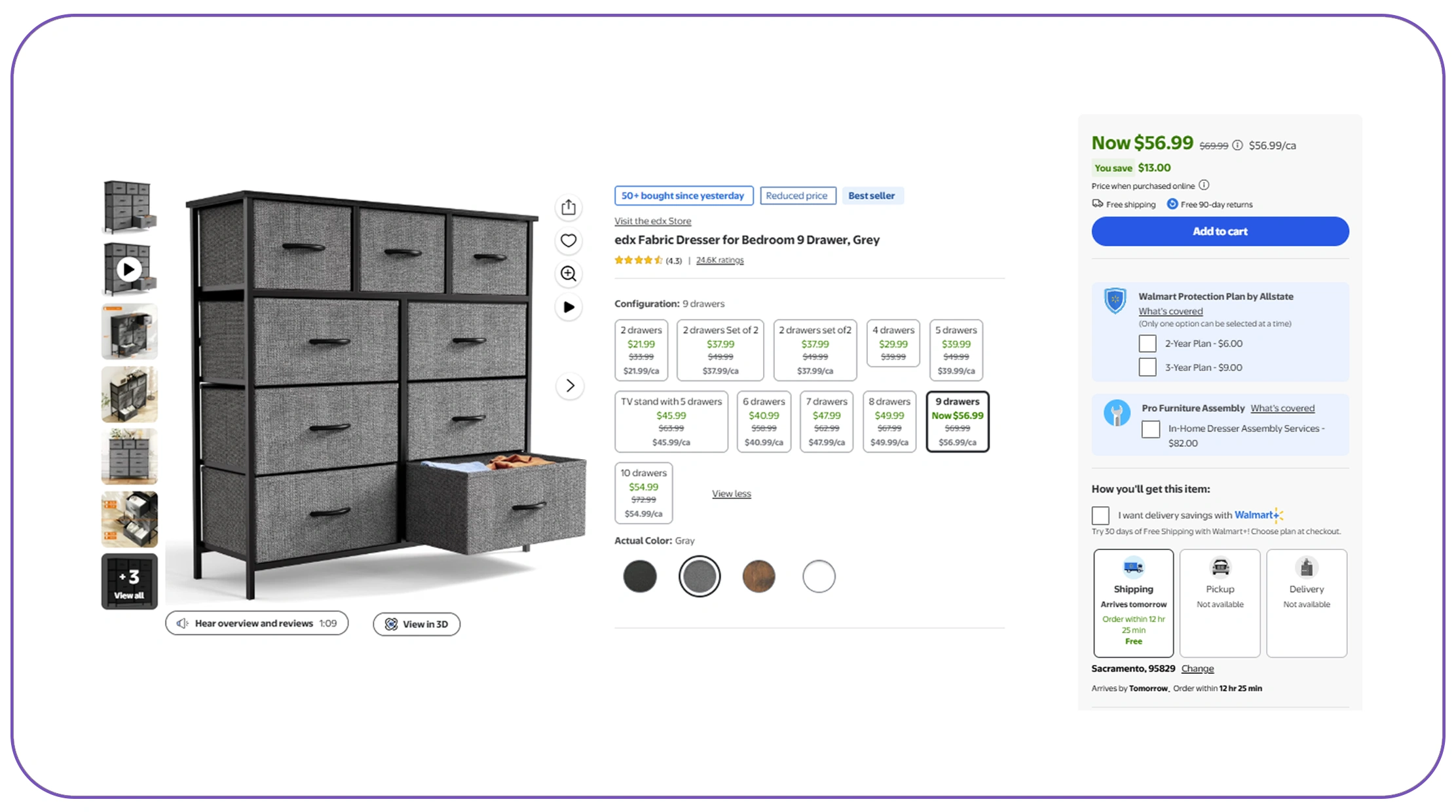
One of the biggest challenges in catalog creation is integrating product data from different ecommerce platforms where formats, naming conventions, and attributes vary significantly. Platforms like Amazon, Shopify, and Walmart often use different schemas, making direct consolidation difficult.
Between 2020 and 2026, studies show that over 65% of retailers expanded to at least three marketplaces, increasing the complexity of product data management. Without proper integration, duplicate listings, inconsistent pricing, and mismatched attributes become common issues.
Key Data Integration Challenges (2020–2026)
| Year | Avg. Platforms per Retailer | Data Inconsistency Rate | Duplicate Listings (%) |
|---|---|---|---|
| 2020 | 2.1 | 28% | 15% |
| 2022 | 2.8 | 34% | 21% |
| 2024 | 3.5 | 41% | 27% |
| 2026 | 4.2 | 48% | 32% |
To address this, businesses must standardize schemas, normalize attributes, and use mapping rules to align data fields. Automated ETL (Extract, Transform, Load) pipelines help merge datasets while preserving data integrity. This ensures consistent product representation across all channels and lays the foundation for a scalable centralized catalog.
Selecting the Right Technology Stack for Data Aggregation
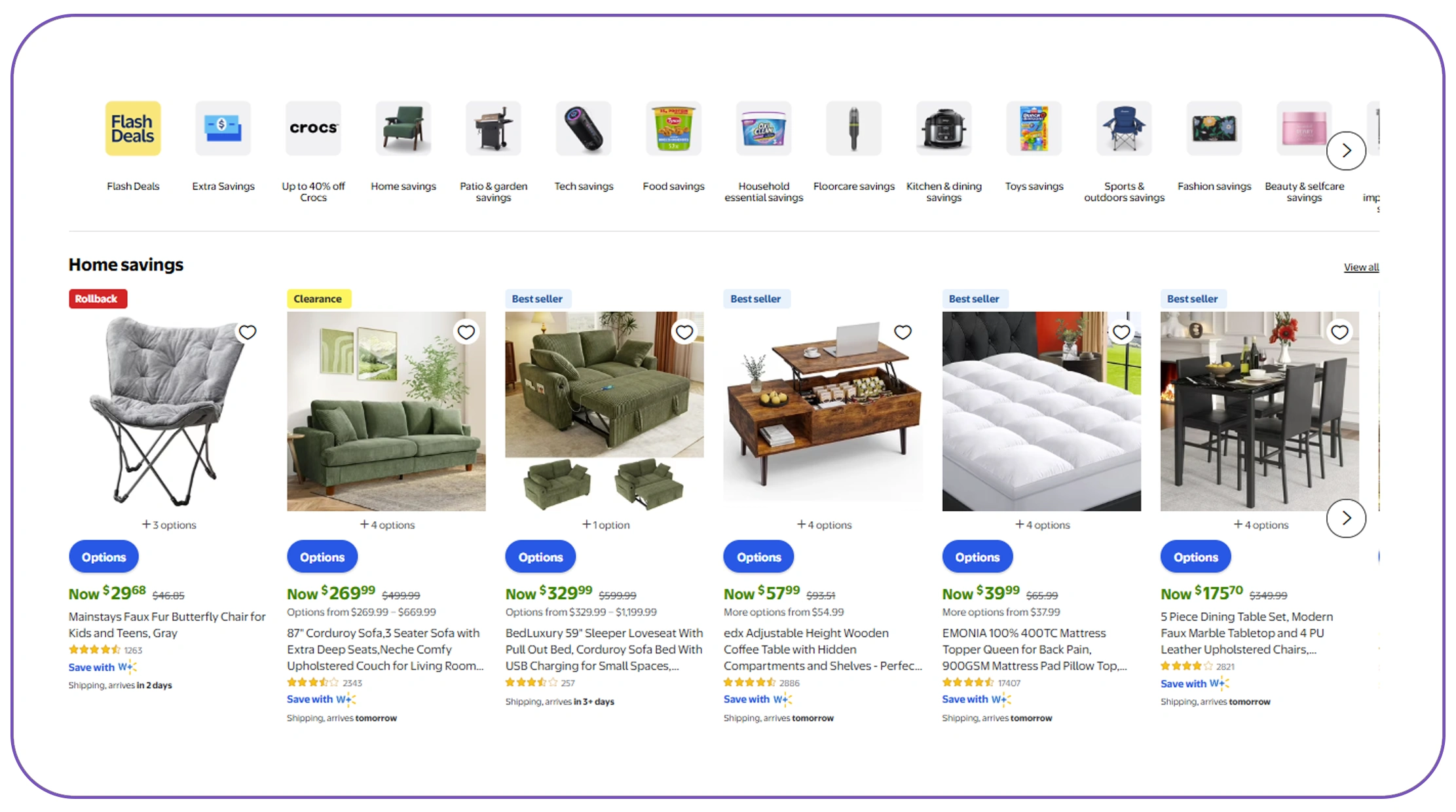
Choosing the right Web Scraping tools for product catalog integration and management is critical for building a reliable data pipeline. The effectiveness of your catalog depends heavily on how efficiently you can collect, process, and update product data from multiple sources.
From 2020 to 2026, the adoption of AI-powered scraping tools increased by over 70%, enabling businesses to extract structured data even from dynamic and JavaScript-heavy websites. Modern tools now offer features such as proxy rotation, CAPTCHA bypassing, and real-time data extraction.
Technology Adoption Trends (2020–2026)
| Tool Capability | 2020 Adoption | 2023 Adoption | 2026 Projection |
|---|---|---|---|
| Basic Scraping Tools | 60% | 45% | 30% |
| AI-powered Scrapers | 20% | 40% | 65% |
| Cloud-based Pipelines | 25% | 50% | 75% |
| Real-time Data Sync | 15% | 35% | 60% |
Businesses should prioritize tools that support scalability, automation, and integration with analytics platforms. A robust tech stack ensures continuous data flow, minimizes downtime, and enhances catalog accuracy.
Efficient Methods for Multi-Source Data Extraction
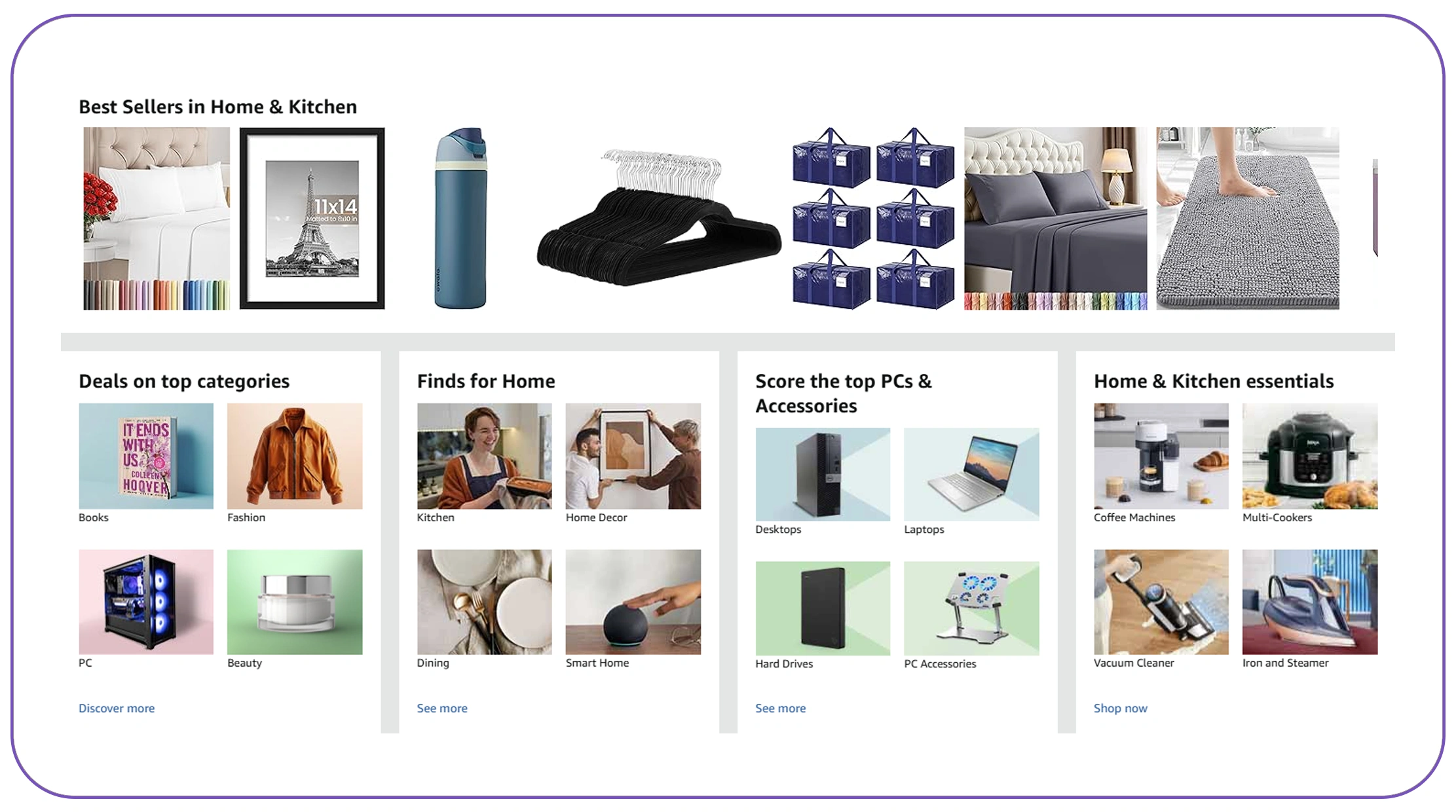
To successfully consolidate data, organizations must use reliable tools to extract product catalog data from multiple sources. These tools should handle structured and unstructured data, ensuring comprehensive coverage of product attributes.
Between 2020 and 2026, multi-source extraction became a standard practice, with companies leveraging APIs, crawlers, and data feeds simultaneously. This hybrid approach improves data completeness and reduces dependency on a single source.
Data Source Utilization (2020–2026)
| Source Type | Usage in 2020 | Usage in 2023 | Usage in 2026 |
|---|---|---|---|
| Marketplaces | 70% | 80% | 90% |
| Brand Websites | 50% | 65% | 78% |
| Supplier Feeds | 40% | 55% | 70% |
| APIs | 30% | 50% | 75% |
Advanced extraction methods include DOM parsing, headless browsing, and AI-based data recognition. These techniques ensure accurate capture of product details such as specifications, images, and pricing. By combining multiple extraction methods, businesses can create a richer and more reliable product dataset.
Structuring and Standardizing the Master Catalog
Once data is extracted, the next step is to create a master product catalog step by step using data scraping. This involves cleaning, transforming, and organizing data into a unified schema.
From 2020 to 2026, companies that implemented structured data pipelines saw a 35% improvement in catalog accuracy and a 25% reduction in operational costs. Data standardization includes attribute mapping, unit conversion, and taxonomy alignment.
Catalog Structuring Impact (2020–2026)
| Metric | Before Structuring | After Structuring |
|---|---|---|
| Data Accuracy | 65% | 90% |
| Processing Time | 10 hrs/day | 4 hrs/day |
| Error Rate | 22% | 8% |
| Update Frequency | Weekly | Real-time |
A step-by-step approach includes data ingestion, validation, normalization, enrichment, and storage. Implementing automated workflows ensures consistency and scalability, allowing businesses to maintain an up-to-date and reliable product catalog.
Resolving Duplicate and Similar Listings
A critical component of catalog management is Product Matching, which ensures that identical or similar products from different sources are correctly identified and merged.
Between 2020 and 2026, duplicate product listings increased by 40% due to multi-platform expansion. Without proper matching, catalogs become cluttered and unreliable.
Duplicate Data Trends (2020–2026)
| Year | Duplicate Rate | Matching Accuracy |
|---|---|---|
| 2020 | 18% | 70% |
| 2022 | 24% | 78% |
| 2024 | 30% | 85% |
| 2026 | 36% | 92% |
Modern matching techniques use AI algorithms, fuzzy logic, and attribute comparison to identify duplicates. These methods analyze product titles, descriptions, SKUs, and images to ensure accurate matching. Implementing robust matching systems improves catalog quality and enhances user experience by eliminating redundancy.
Leveraging APIs for Real-Time Data Synchronization
To maintain an up-to-date catalog, businesses must rely on a Web Scraping API that enables real-time data synchronization. APIs provide seamless integration with data sources, ensuring continuous updates without manual intervention.
From 2020 to 2026, API-driven data pipelines became the backbone of modern catalog systems, with adoption rates exceeding 75% among large enterprises.
API Adoption and Benefits (2020–2026)
| Benefit | Impact Level |
|---|---|
| Real-time Updates | High |
| Scalability | High |
| Data Accuracy | Very High |
| Operational Efficiency | High |
APIs allow businesses to fetch updated product information, monitor changes, and trigger automated workflows. This ensures that the catalog remains accurate and competitive in dynamic market conditions.
Why Choose Real Data API?
When it comes to Web Scraping Services, Real Data API stands out as a trusted partner for businesses looking to scale efficiently. With advanced capabilities and robust infrastructure, it helps organizations build a centralized product catalog using scraped data with precision and reliability.
Real Data API offers high-quality data extraction, real-time updates, and seamless integration with existing systems. Its solutions are designed to handle large-scale data requirements while maintaining accuracy and compliance. Businesses benefit from reduced operational costs, faster deployment, and improved decision-making.
By leveraging Real Data API, companies can transform fragmented product data into a unified, actionable resource that drives growth and innovation.
Conclusion
Building a centralized catalog is essential for modern businesses aiming to stay competitive in a data-driven world. By leveraging advanced tools and strategies, organizations can build a centralized product catalog using scraped data that enhances accuracy, efficiency, and scalability.
From data extraction to matching and real-time synchronization, every step plays a crucial role in creating a reliable catalog. Businesses that invest in this approach gain a significant advantage by turning raw data into actionable insights.
Ready to transform your product data strategy? Partner with Real Data API today and unlock the full potential of centralized catalog management!
Latest posts
Why Brands Use Competitive Data Intelligence to Increase Market Share in Highly Competitive Markets?

How To Scrape Competitor Data To Support Market Entry Strategy And Expansion Planning For Data-Driven Business Growth?

How Hotel Occupancy Intelligence Through Public Data Sources Is Reshaping Revenue Management

The ZIP Code Advantage: How Hyper-Local Amazon Product Data Collection Is Redefining Retail Intelligence
Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.







Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7


Disclaimer : RealData API functions solely as an independent data infrastructure and technology solutions provider. We build customized automation workflows designed to collect publicly accessible web data based exclusively on client instructions. RealData API neither owns proprietary datasets nor engages in the sale or redistribution of extracted information. Our operations are limited strictly to lawful public web data processing and never involve unauthorized access to restricted systems or private networks. Any company names, trademarks, logos, or brand references displayed on this website are used purely for demonstrative and illustrative purposes to showcase our technical capabilities and do not imply endorsement, partnership, or affiliation. Use of our platform and services remains subject to our Terms of Service.