

Introduction
In today's data-driven economy, businesses rely heavily on web scraping to gather competitive intelligence, pricing insights, and product information. However, as data volumes grow exponentially, scalability becomes a major challenge. Organizations must adopt a real-time data transformation pipeline for scraped datasets to ensure seamless processing, structuring, and delivery of data at scale. Without such a system, bottlenecks in data ingestion, processing latency, and inconsistencies can severely impact decision-making and operational efficiency.
From 2020 to 2026, global data generation has increased by over 180%, with scraped datasets contributing significantly across industries like eCommerce, travel, and finance. Traditional batch processing systems struggle to keep up with this surge, leading to delays and outdated insights. A real-time pipeline eliminates these issues by transforming raw data instantly as it is collected, enabling businesses to respond faster to market changes.
By integrating automation, cloud computing, and AI-driven transformation processes, companies can streamline workflows and enhance Product Development. This ensures that data is not only collected but also refined into actionable intelligence, helping organizations scale efficiently and maintain a competitive edge.
Building a Strong Foundation for Scalable Transformation
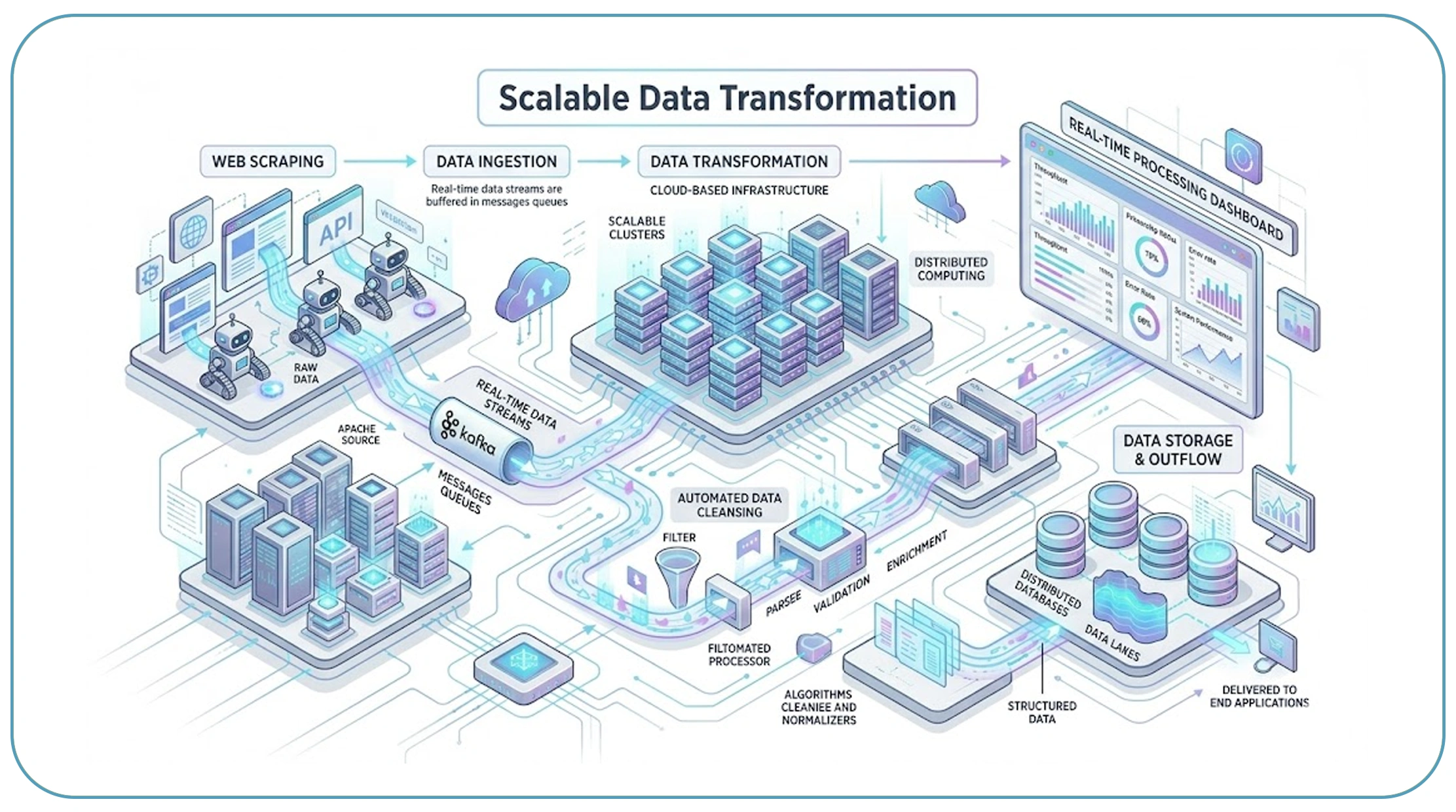
Selecting the best tools for data transformation in web scraping is the first step toward eliminating scalability bottlenecks. Modern tools offer advanced capabilities such as real-time processing, distributed computing, and automated data cleansing, which are essential for handling large datasets.
Between 2020 and 2026, adoption of cloud-based data transformation tools has surged significantly, driven by the need for scalability and flexibility. These tools enable businesses to process millions of data points without compromising speed or accuracy.
Tool Adoption Trends (2020–2026)
| Year | Cloud-Based Tools Adoption | On-Premise Tools Usage | Real-Time Processing Adoption |
|---|---|---|---|
| 2020 | 35% | 65% | 20% |
| 2022 | 50% | 50% | 35% |
| 2024 | 65% | 35% | 55% |
| 2026 | 80% | 20% | 70% |
By leveraging scalable tools like Apache Spark, Kafka, and cloud-native ETL platforms, organizations can process data streams efficiently. These technologies distribute workloads across multiple nodes, reducing processing time and preventing system overloads. Choosing the right tools ensures that your pipeline can scale alongside your business needs.
Advanced Methods to Handle High-Volume Data
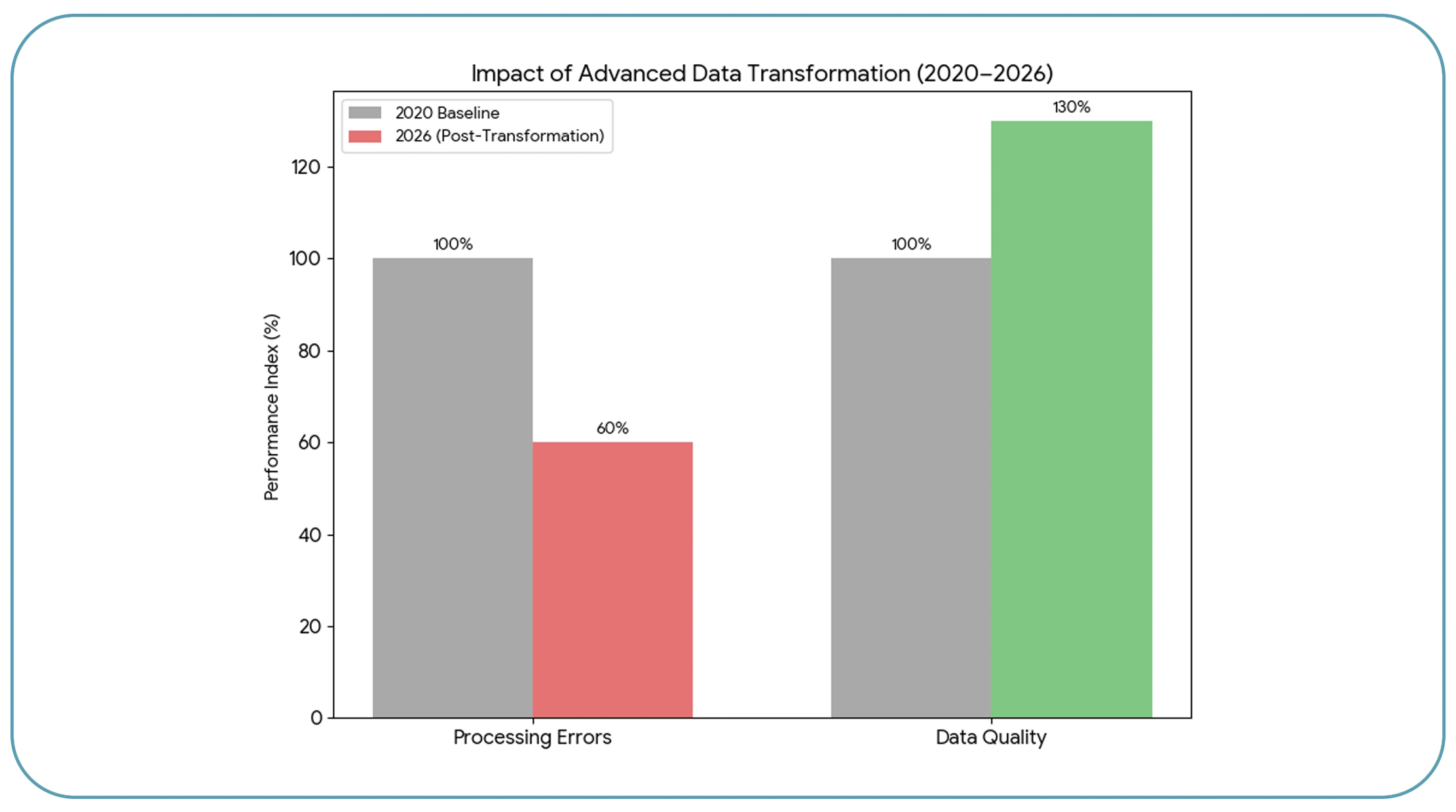
Implementing effective data transformation techniques for large-scale scraping is crucial for managing high data volumes. Techniques such as data normalization, deduplication, and schema mapping help ensure consistency and accuracy across datasets.
From 2020 to 2026, businesses adopting advanced transformation techniques reported a 40% reduction in processing errors and a 30% improvement in data quality. These improvements are essential for maintaining reliable analytics and decision-making processes.
Impact of Transformation Techniques (2020–2026)
| Technique | Error Reduction | Efficiency Gain |
|---|---|---|
| Data Normalization | 25% | 20% |
| Deduplication | 30% | 25% |
| Schema Mapping | 35% | 30% |
| AI-Based Enrichment | 45% | 40% |
Real-time transformation pipelines apply these techniques automatically as data flows through the system. This eliminates the need for manual intervention and ensures that data remains clean and structured. By adopting these methods, businesses can handle large-scale scraping operations without compromising performance or accuracy.
Designing a Robust and Scalable Pipeline Framework

A well-structured end-to-end data pipeline architecture for scraped data is essential for overcoming scalability challenges. This architecture typically includes data ingestion, processing, storage, and delivery layers, each optimized for performance and reliability.
Between 2020 and 2026, companies investing in end-to-end pipeline architectures experienced a 50% increase in data processing speed and a 35% reduction in system downtime. These improvements highlight the importance of a robust framework in managing large datasets.
Pipeline Performance Metrics (2020–2026)
| Metric | Traditional Systems | Modern Pipelines |
|---|---|---|
| Processing Speed | Medium | High |
| Scalability | Limited | High |
| Downtime | 15% | 5% |
| Data Latency | High | Low |
Key components of a scalable pipeline include distributed processing engines, real-time streaming platforms, and cloud storage solutions. By integrating these components, businesses can ensure continuous data flow and minimize bottlenecks, enabling efficient data transformation at scale.
Enhancing Data Accuracy Through Intelligent Matching

One of the most critical aspects of data transformation is Product Matching, which ensures that identical or similar products from different sources are accurately identified and merged.
From 2020 to 2026, the volume of duplicate product listings increased significantly due to the expansion of multi-channel selling. Without proper matching mechanisms, these duplicates can lead to inconsistencies and inaccurate analytics.
Duplicate Data Trends (2020–2026)
| Year | Duplicate Rate | Matching Accuracy |
|---|---|---|
| 2020 | 18% | 70% |
| 2022 | 24% | 78% |
| 2024 | 30% | 85% |
| 2026 | 36% | 92% |
Modern matching techniques use AI and machine learning algorithms to analyze product attributes such as titles, descriptions, and images. These techniques improve matching accuracy and reduce redundancy, ensuring that the final dataset is clean and reliable.
Enabling Seamless Data Flow with API Integration
Integrating a Web Scraping API into your pipeline is essential for achieving real-time data transformation. APIs provide a seamless connection between data sources and transformation systems, enabling continuous data flow without manual intervention.
From 2020 to 2026, API-driven pipelines became the standard for large-scale data operations, with adoption rates exceeding 75% among enterprises. APIs allow businesses to fetch, process, and update data in real time, ensuring that insights are always current.
API Benefits (2020–2026)
| Benefit | Impact Level |
|---|---|
| Real-Time Updates | Very High |
| Scalability | High |
| Data Accuracy | Very High |
| Automation | High |
By leveraging APIs, organizations can automate data workflows and reduce latency. This ensures that the pipeline remains efficient and scalable, even as data volumes continue to grow.
Leveraging Managed Solutions for Efficiency
Outsourcing to professional Web Scraping Services can significantly reduce the complexity of building and managing a real-time data transformation pipeline. These services provide end-to-end solutions, including data extraction, transformation, and integration.
Between 2020 and 2026, businesses that adopted managed services reported a 45% reduction in operational costs and a 35% improvement in data processing efficiency. These benefits make managed services an attractive option for organizations looking to scale quickly.
Managed Services Impact (2020–2026)
| Metric | Improvement |
|---|---|
| Operational Cost | -45% |
| Processing Efficiency | +35% |
| Deployment Speed | +40% |
| Maintenance Effort | -50% |
By partnering with experienced providers, businesses can focus on core activities while ensuring that their data pipelines remain efficient and scalable.
Why Choose Real Data API?
Real Data API is a leading provider of advanced data solutions designed to help businesses overcome scalability challenges. By implementing a real-time data transformation pipeline for scraped datasets, the platform enables organizations to process and utilize data with unmatched speed and accuracy.
With cutting-edge technology, Real Data API offers real-time data extraction, transformation, and integration capabilities. Its solutions are built to handle large-scale datasets, ensuring seamless performance even under heavy workloads. Businesses benefit from improved efficiency, reduced costs, and enhanced decision-making capabilities.
Real Data API also provides customizable solutions tailored to specific business needs, making it a reliable partner for organizations across industries. Whether you are managing eCommerce data or conducting market research, Real Data API ensures that your data pipeline is optimized for success.
Conclusion
Scalability bottlenecks can significantly hinder the effectiveness of data-driven operations. By adopting a real-time data transformation pipeline for scraped datasets, businesses can eliminate these challenges and unlock the full potential of their data.
From selecting the right tools to implementing advanced transformation techniques and leveraging APIs, every step plays a crucial role in building a scalable and efficient pipeline. Organizations that invest in these strategies gain a competitive advantage by transforming raw data into actionable insights in real time.
Ready to scale your data operations? Partner with Real Data API today and build a future-proof data pipeline that drives growth and innovation!
Latest posts
Why Brands Use Competitive Data Intelligence to Increase Market Share in Highly Competitive Markets?

How To Scrape Competitor Data To Support Market Entry Strategy And Expansion Planning For Data-Driven Business Growth?

How Hotel Occupancy Intelligence Through Public Data Sources Is Reshaping Revenue Management

The ZIP Code Advantage: How Hyper-Local Amazon Product Data Collection Is Redefining Retail Intelligence
Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.







Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7


Disclaimer : RealData API functions solely as an independent data infrastructure and technology solutions provider. We build customized automation workflows designed to collect publicly accessible web data based exclusively on client instructions. RealData API neither owns proprietary datasets nor engages in the sale or redistribution of extracted information. Our operations are limited strictly to lawful public web data processing and never involve unauthorized access to restricted systems or private networks. Any company names, trademarks, logos, or brand references displayed on this website are used purely for demonstrative and illustrative purposes to showcase our technical capabilities and do not imply endorsement, partnership, or affiliation. Use of our platform and services remains subject to our Terms of Service.