

Introduction
In today's data-driven economy, businesses rely heavily on scraped data to power analytics, pricing strategies, and competitive intelligence. However, raw scraped data is often messy, unstructured, and filled with duplicates or inconsistencies. This is why understanding how to remove duplicates and inconsistencies in scraped data is critical for ensuring accurate insights and reliable decision-making.
Using an E-Commerce Data Scraping API, organizations can collect vast amounts of product, pricing, and competitor data. But without proper data cleaning processes, this information can lead to misleading conclusions and poor business outcomes.
Between 2020 and 2026, companies that invested in robust data cleaning pipelines reported up to 40% improvement in analytics accuracy and significantly reduced operational errors. Clean data enables better forecasting, more precise pricing strategies, and improved customer insights.
This blog explores practical methods, tools, and strategies to clean scraped datasets effectively—helping businesses transform raw data into actionable intelligence.
Building a structured cleaning workflow
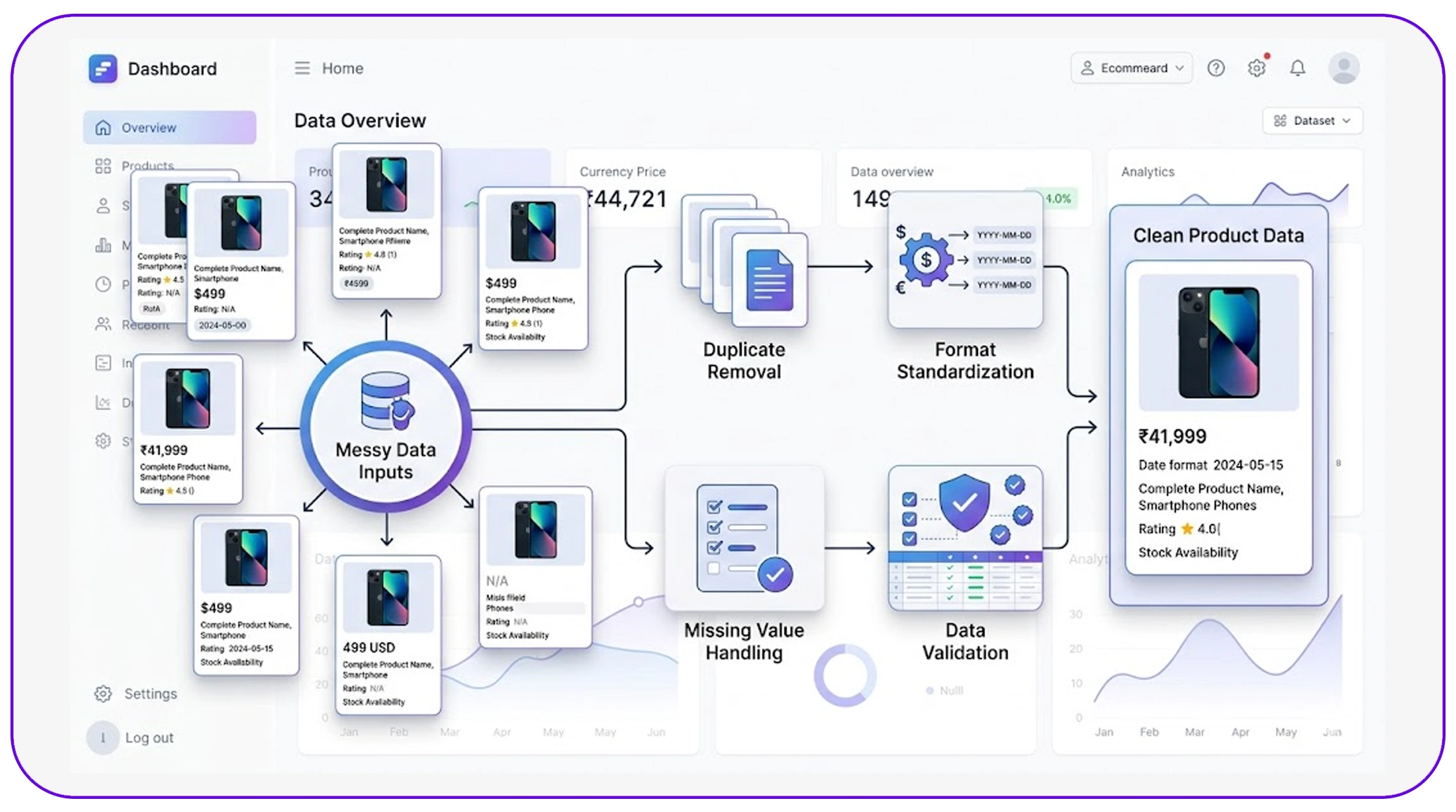
A systematic approach is essential when cleaning scraped product data step by step. Without a defined workflow, inconsistencies can persist and affect downstream analytics.
A typical cleaning process includes:
- Removing duplicate entries
- Standardizing formats (dates, currency, units)
- Handling missing or null values
- Validating data consistency
Data cleaning efficiency trends (2020–2026):
| Year | Cleaning Accuracy | Duplicate Removal Efficiency | Processing Speed |
|---|---|---|---|
| 2020 | 60% | 55% | Low |
| 2022 | 72% | 70% | Moderate |
| 2024 | 85% | 83% | High |
| 2026 | 95% | 92% | Real-time |
By following a structured workflow, businesses can ensure that their datasets are accurate, complete, and ready for analysis.
Applying advanced data cleaning techniques
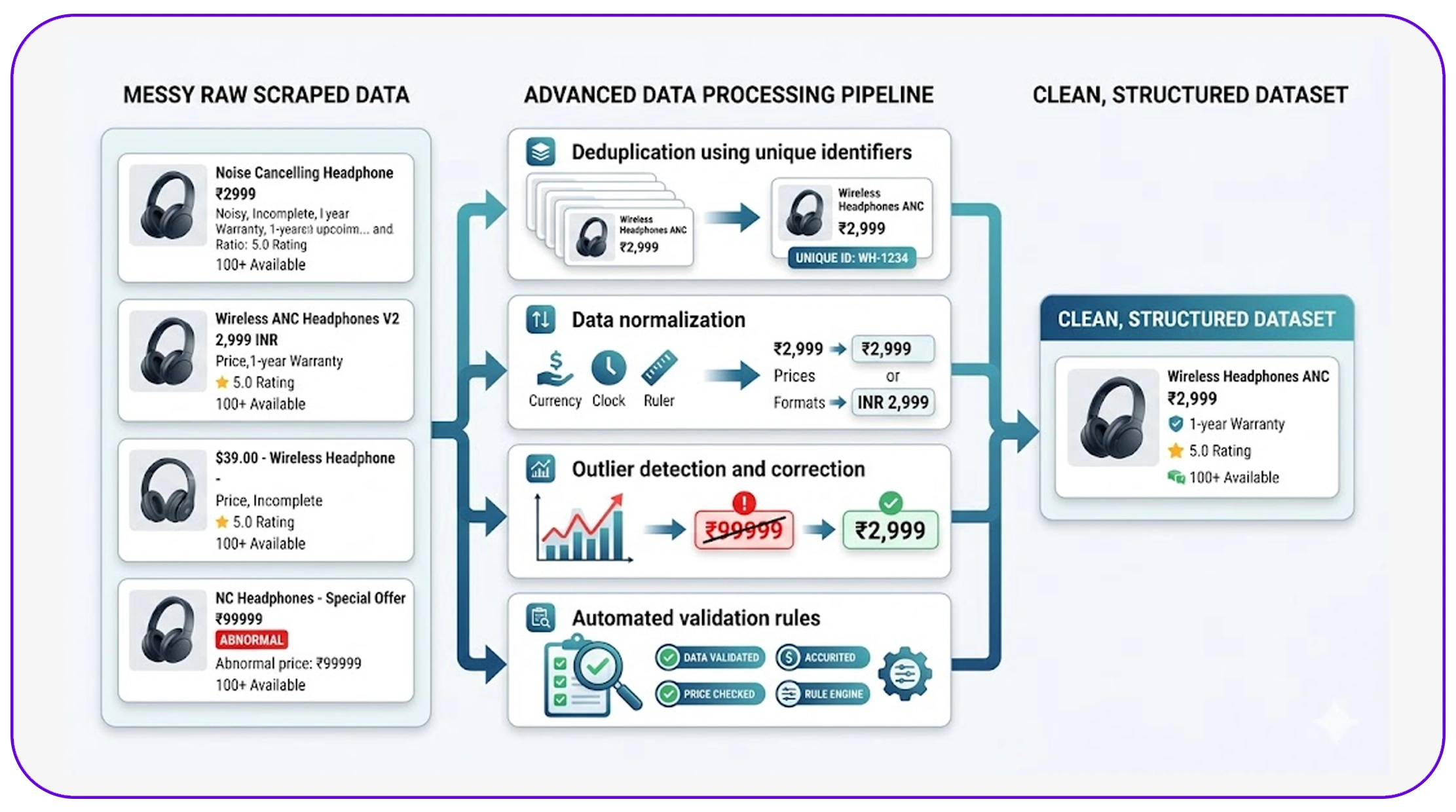
Modern organizations use data cleaning techniques for scraped retail datasets to handle large-scale data challenges efficiently.
These techniques include:
- Deduplication using unique identifiers
- Data normalization across formats
- Outlier detection and correction
- Automated validation rules
Impact of advanced cleaning techniques (2020–2026):
| Metric | 2020 | 2026 |
|---|---|---|
| Data Accuracy | 65% | 96% |
| Error Reduction | 50% | 90% |
| Processing Efficiency | 55% | 88% |
Automation plays a key role in scaling these techniques. Machine learning algorithms can detect anomalies and inconsistencies that manual processes might miss.
These methods ensure that businesses can maintain high-quality datasets even as data volume grows exponentially.
Managing messy data in analytics pipelines
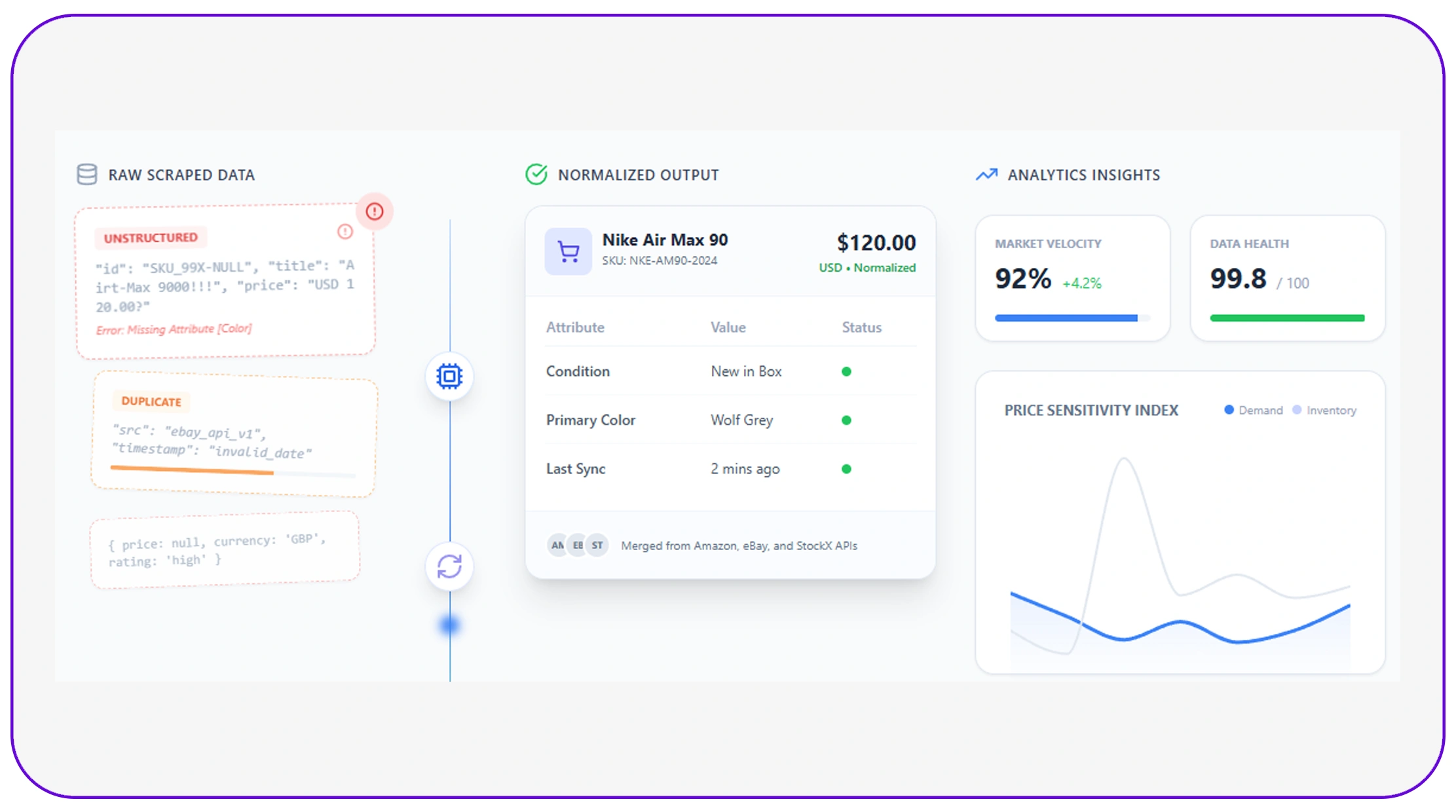
Handling large datasets requires efficient systems for handling messy scraped data for analytics pipelines.
Data pipelines must be designed to:
- Clean data in real time
- Integrate multiple data sources
- Maintain consistency across datasets
Pipeline performance improvements (2020–2026):
| Metric | 2020 | 2026 |
|---|---|---|
| Pipeline Reliability | 60% | 94% |
| Data Consistency | 58% | 92% |
| Processing Time | High | Low |
By integrating cleaning processes into pipelines, businesses can:
- Reduce manual intervention
- Ensure continuous data quality
- Enable real-time analytics
This approach is essential for organizations that rely on fast and accurate insights.
Standardizing product and SKU data
One of the biggest challenges in ecommerce analytics is to normalize SKU and product data across retailers.
Different platforms often use varying naming conventions, formats, and identifiers for the same product. This creates inconsistencies that can distort analysis.
SKU normalization impact (2020–2026):
| Metric | 2020 | 2026 |
|---|---|---|
| Matching Accuracy | 62% | 95% |
| Data Consistency | 60% | 93% |
| Analysis Reliability | 58% | 91% |
Normalization techniques include:
- Standardizing product names
- Mapping SKUs across platforms
- Using product matching algorithms
This ensures that businesses can compare products accurately and derive meaningful insights.
Leveraging datasets for accurate insights
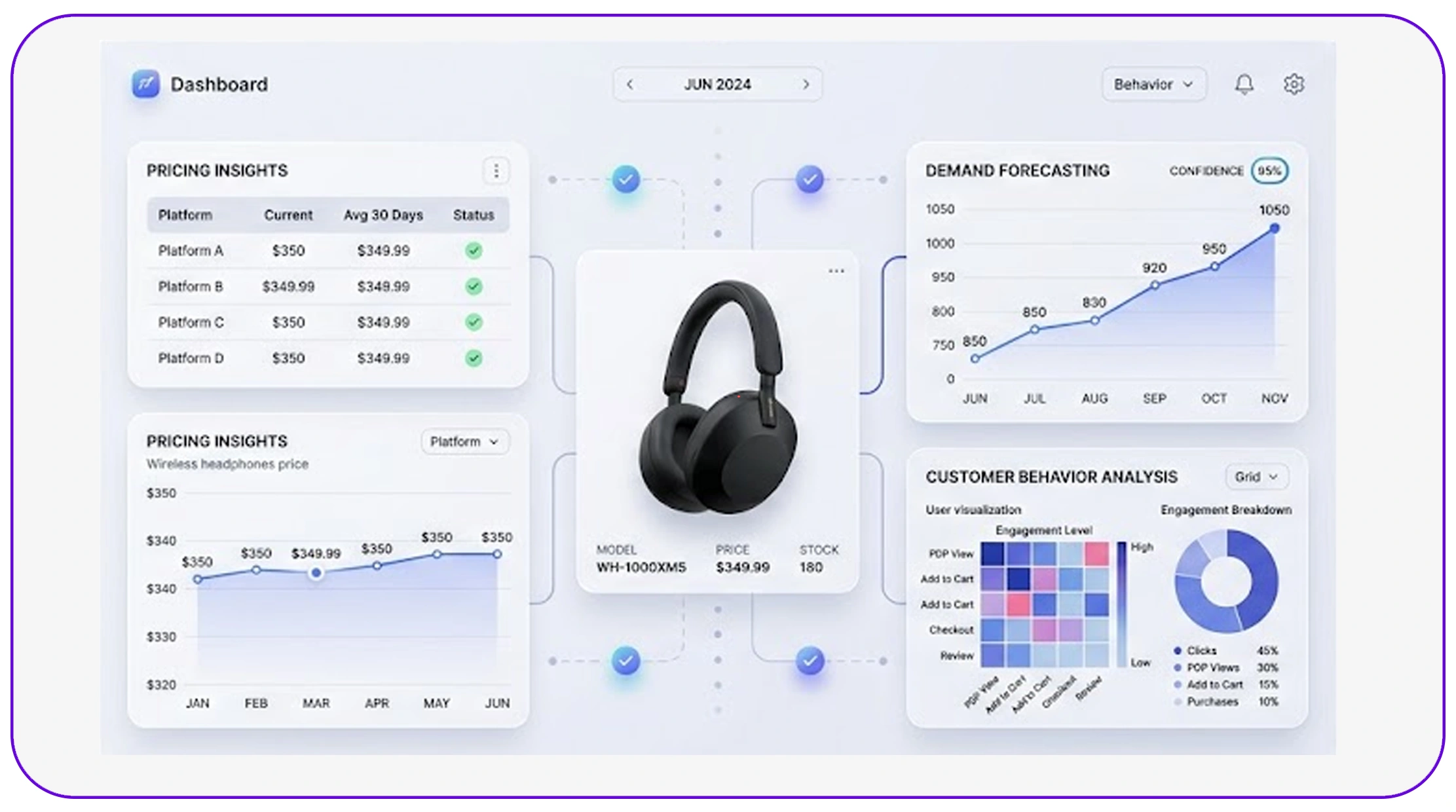
High-quality E-Commerce Dataset plays a crucial role in enabling accurate analytics and decision-making.
Clean datasets provide:
- Reliable pricing insights
- Accurate demand forecasting
- Better customer behavior analysis
Dataset quality improvements (2020–2026):
| Year | Data Quality Score | Insight Accuracy | Decision Confidence |
|---|---|---|---|
| 2020 | 65% | 60% | 58% |
| 2022 | 78% | 75% | 72% |
| 2024 | 88% | 85% | 83% |
| 2026 | 96% | 93% | 92% |
By maintaining clean datasets, businesses can:
- Improve analytics accuracy
- Reduce errors in reporting
- Enhance strategic decision-making
Expanding capabilities with API-driven solutions
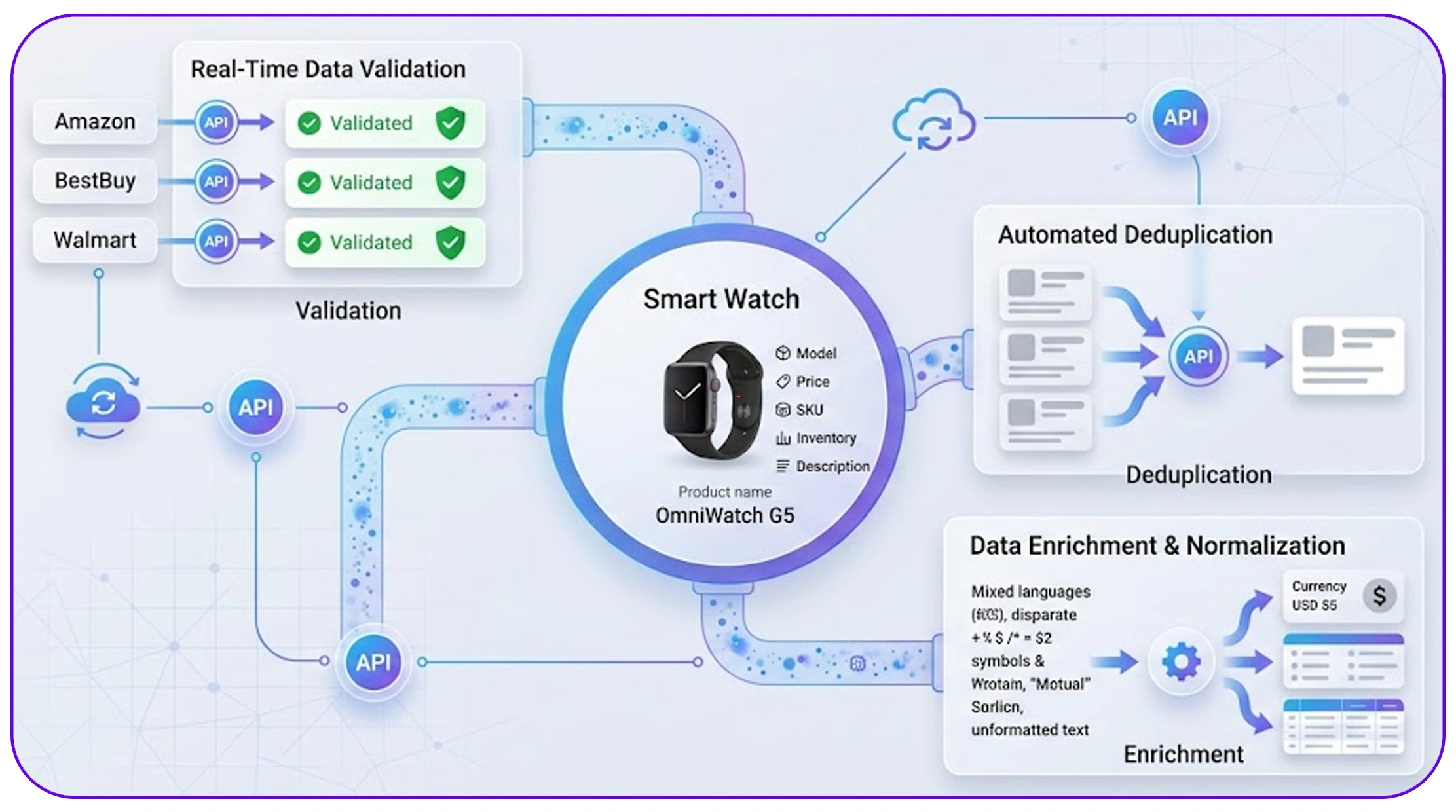
Businesses are increasingly adopting Top Ecommerce Scraping API Use Cases to automate data cleaning and improve efficiency.
Key use cases include:
- Real-time data validation
- Automated deduplication
- Data enrichment and normalization
API adoption trends (2020–2026):
| Year | API Adoption | Automation Level | Business Impact |
|---|---|---|---|
| 2020 | 30% | Low | Moderate |
| 2022 | 50% | Medium | High |
| 2024 | 75% | High | Very High |
| 2026 | 92% | Advanced | Critical |
API-driven solutions enable businesses to scale their data cleaning processes and maintain consistent data quality across operations.
Ensuring consistency with automated validation systems
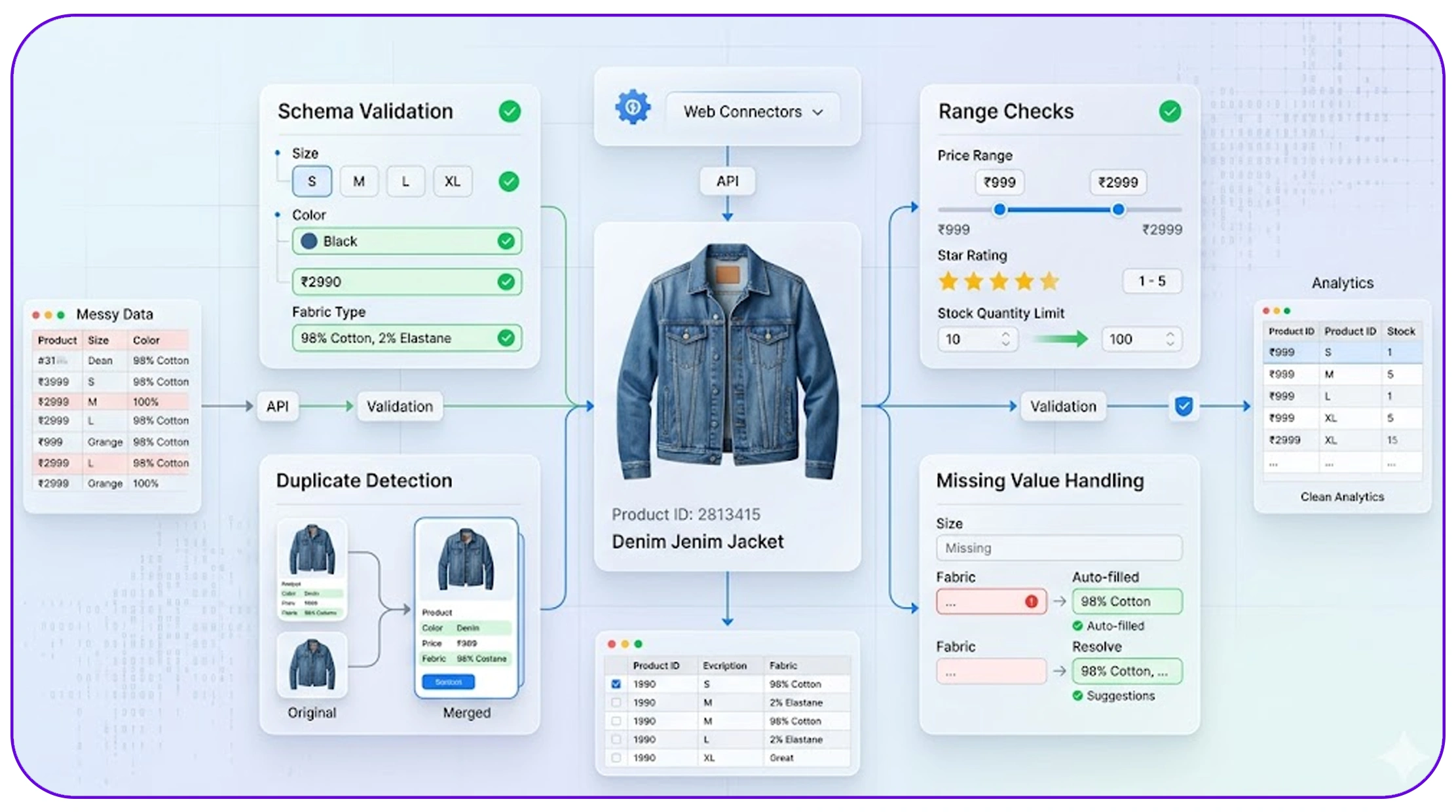
Maintaining data accuracy at scale requires robust validation processes. Businesses now rely on automated data validation for scraped datasets to ensure that incoming data meets predefined quality standards before entering analytics systems.
Automated validation includes:
- Schema validation (correct data formats)
- Range checks (price, ratings, quantities)
- Duplicate detection rules
- Missing value handling
Validation system impact (2020–2026):
| Metric | 2020 | 2026 |
|---|---|---|
| Validation Accuracy | 62% | 96% |
| Error Detection Rate | 58% | 94% |
| Data Reliability Score | 60% | 93% |
By implementing automated validation, businesses can:
- Detect anomalies in real time
- Prevent incorrect data from entering pipelines
- Reduce manual intervention
This approach is especially useful for high-frequency scraping environments where large volumes of data are processed continuously. Automated validation ensures that datasets remain clean, consistent, and ready for analysis without delays.
Enhancing data quality with enrichment and standardization
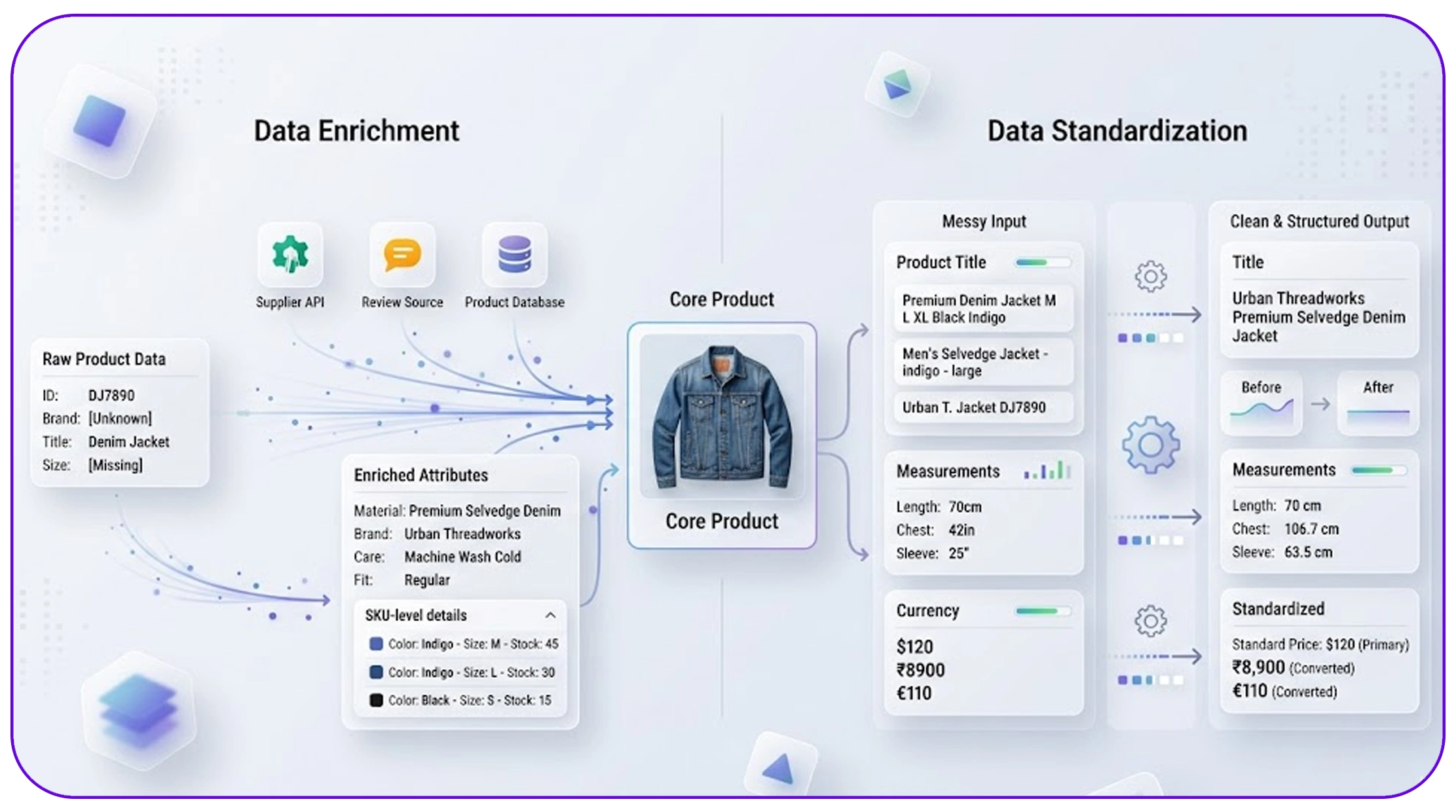
Beyond cleaning, businesses must focus on improving dataset usability through data enrichment and standardization in ecommerce scraping.
Data enrichment involves:
- Adding missing product attributes
- Enhancing SKU-level details
- Integrating external datasets for completeness
Standardization ensures:
- Uniform naming conventions
- Consistent measurement units
- Harmonized currency formats
Data enrichment impact (2020–2026):
| Metric | 2020 | 2026 |
|---|---|---|
| Data Completeness | 65% | 97% |
| Insight Depth | 60% | 92% |
| Analytics Accuracy | 62% | 95% |
These processes enable businesses to:
- Improve product matching accuracy
- Generate deeper insights
- Enhance reporting capabilities
With enriched and standardized data, companies can unlock the full potential of their datasets and drive more informed business decisions.
Why Choose Real Data API?
Maintaining high-quality data requires reliable tools and infrastructure. With Web Scraping Services, businesses can collect, clean, and process data efficiently.
Real Data API helps organizations understand how to remove duplicates and inconsistencies in scraped data by providing structured datasets, automated cleaning processes, and real-time data validation.
These capabilities enable businesses to:
- Ensure data accuracy
- Improve analytics performance
- Reduce operational inefficiencies
With Real Data API, companies can confidently rely on their data for strategic decision-making.
Conclusion
Data quality is the foundation of effective analytics and decision-making. Without proper cleaning processes, scraped data can lead to inaccurate insights and missed opportunities.
By learning how to remove duplicates and inconsistencies in scraped data, businesses can transform raw datasets into reliable and actionable intelligence. This enables better forecasting, improved pricing strategies, and stronger competitive positioning.
As data volumes continue to grow, automation and advanced cleaning techniques will play an increasingly important role in maintaining data integrity.
Start using Real Data API today to master how to remove duplicates and inconsistencies in scraped data—enhance your data quality, improve decision-making, and unlock the full potential of your analytics!
Latest posts
Why Brands Use Competitive Data Intelligence to Increase Market Share in Highly Competitive Markets?

How To Scrape Competitor Data To Support Market Entry Strategy And Expansion Planning For Data-Driven Business Growth?

How Hotel Occupancy Intelligence Through Public Data Sources Is Reshaping Revenue Management

The ZIP Code Advantage: How Hyper-Local Amazon Product Data Collection Is Redefining Retail Intelligence
Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.







Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7


Disclaimer : RealData API functions solely as an independent data infrastructure and technology solutions provider. We build customized automation workflows designed to collect publicly accessible web data based exclusively on client instructions. RealData API neither owns proprietary datasets nor engages in the sale or redistribution of extracted information. Our operations are limited strictly to lawful public web data processing and never involve unauthorized access to restricted systems or private networks. Any company names, trademarks, logos, or brand references displayed on this website are used purely for demonstrative and illustrative purposes to showcase our technical capabilities and do not imply endorsement, partnership, or affiliation. Use of our platform and services remains subject to our Terms of Service.