

Introduction
In today's data-driven ecosystem, understanding the performance comparison between API and browser-based scraping is essential for choosing the right data extraction strategy. Businesses increasingly rely on automated solutions to gather large volumes of web data, but the method they choose significantly impacts speed, scalability, and efficiency. A robust Web Scraping API offers structured and fast data access, while browser-based scraping excels in handling dynamic, JavaScript-heavy websites.
Between 2020 and 2026, API-based scraping adoption has grown by over 60%, primarily due to its efficiency and lower resource consumption. Meanwhile, browser automation tools continue to evolve, enabling better handling of complex web environments. Each approach has its strengths and limitations, making it critical for organizations to evaluate their specific use cases.
This blog explores a detailed comparison of APIs and browser-based scraping, highlighting performance metrics, scalability factors, and real-world applications to help businesses make informed decisions.
Evaluating Data Extraction Methods
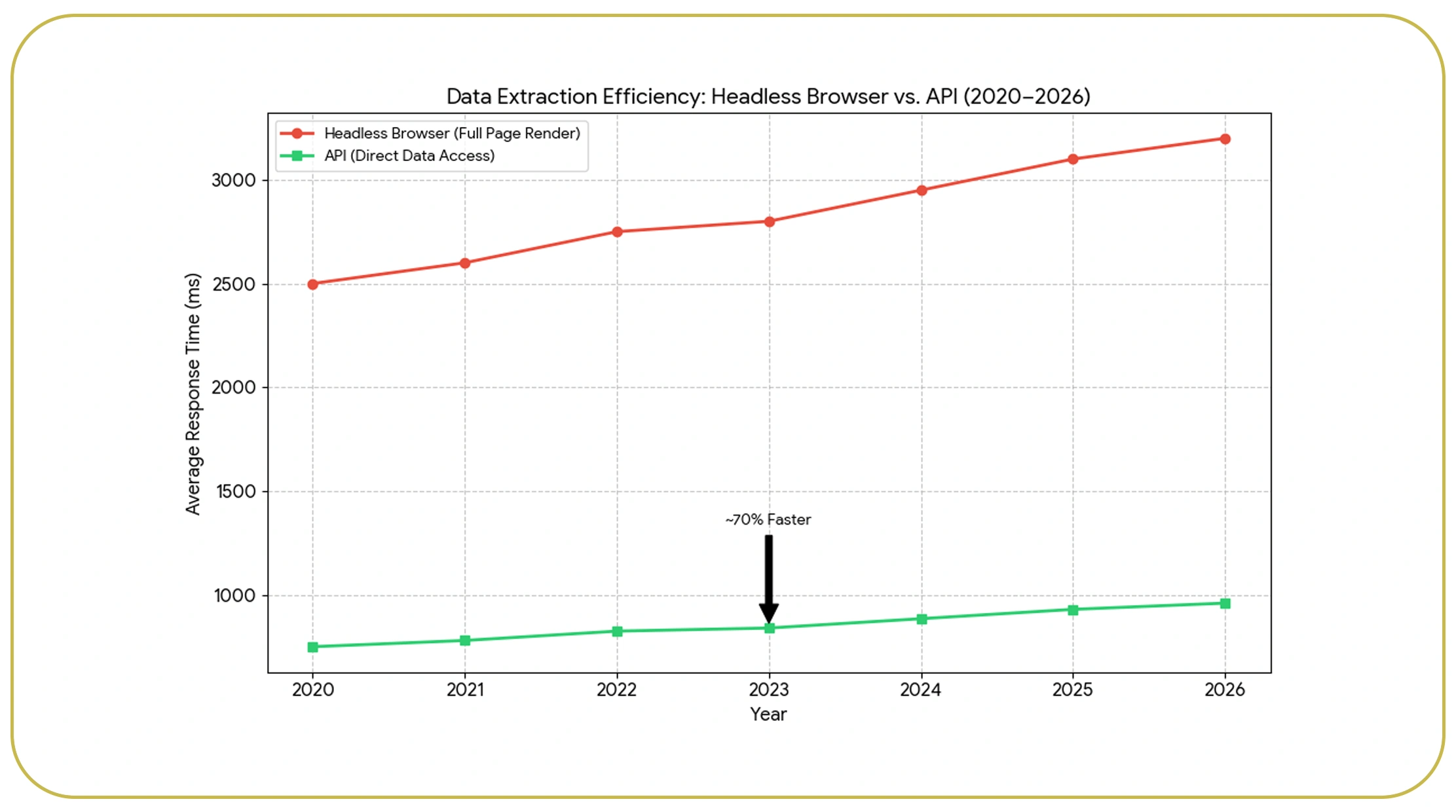
The debate around headless browsers vs APIs for data extraction often centers on flexibility versus efficiency. APIs provide direct access to structured data, eliminating the need for rendering web pages. In contrast, headless browsers simulate real user interactions, making them ideal for scraping dynamic content.
From 2020 to 2026, APIs have demonstrated up to 70% faster response times compared to browser-based methods. However, headless browsers remain essential for websites with heavy JavaScript or anti-scraping mechanisms.
| Method | Speed Advantage | Use Case | APIs | High | Structured data access |
|---|---|---|
| Headless Browsers | Moderate | Dynamic content scraping |
While APIs reduce computational overhead, browsers offer greater adaptability. Businesses often combine both approaches to balance speed and flexibility, ensuring comprehensive data extraction across diverse web environments.
Enhancing Speed and Efficiency
To maximize output, organizations must optimize scraping performance using APIs or browsers depending on their requirements. APIs excel in delivering fast and consistent results, while browsers require optimization techniques such as caching and resource blocking to improve performance.
Between 2020 and 2026, optimized API scraping systems have achieved up to 65% higher throughput compared to unoptimized browser-based systems. Techniques like asynchronous requests and distributed computing further enhance performance.
| Optimization Technique | API Impact | Browser Impact |
|---|---|---|
| Async Processing | +60% | +40% |
| Caching | +30% | +25% |
| Resource Blocking | N/A | +35% |
Choosing the right optimization strategy ensures efficient resource utilization and faster data retrieval. By aligning tools and techniques with specific needs, businesses can significantly improve scraping performance.
Determining the Right Strategy for Scale

Selecting the best approach for large-scale data extraction APIs vs browsers depends on the volume and complexity of data. APIs are ideal for high-volume operations due to their scalability and low latency, while browsers are better suited for smaller, complex tasks.
From 2020 to 2026, organizations using API-based scraping for large-scale operations have reported a 50% reduction in infrastructure costs. However, browser-based scraping remains indispensable for accessing data behind interactive interfaces.
| Scale Level | Preferred Method | Key Benefit |
|---|---|---|
| Small Scale | Browsers | Flexibility |
| Medium Scale | Hybrid | Balanced performance |
| Large Scale | APIs | High efficiency |
A hybrid approach often delivers the best results, combining the strengths of both methods. This ensures scalability without compromising on data coverage.
Integrating Automation for Better Outcomes
Modern scraping workflows rely on API and browser automation for scraping to streamline operations and reduce manual intervention. Automation tools enable seamless integration of APIs and browser-based methods, creating efficient pipelines.
Between 2020 and 2026, automation adoption in scraping has increased by over 55%, enabling faster and more reliable data extraction. Automated workflows can handle retries, error detection, and data processing without human input.
| Automation Feature | Benefit | Adoption Growth |
|---|---|---|
| Error Handling | Reduced downtime | +50% |
| Scheduling | Consistent data collection | +45% |
| Integration | Seamless workflows | +60% |
By integrating automation, businesses can improve efficiency and ensure consistent performance. This approach reduces operational complexity and enhances overall productivity.
Leveraging Managed Solutions for Efficiency
Many organizations turn to Web Scraping Services to simplify their data extraction processes. These services provide end-to-end solutions, including API integration and browser automation, ensuring optimal performance.
From 2020 to 2026, the adoption of managed scraping services has grown by over 50%, as businesses seek scalable and reliable solutions. These services offer features such as real-time data delivery, proxy management, and performance optimization.
| Service Feature | Benefit | Growth Rate |
|---|---|---|
| API Integration | Faster data access | +55% |
| Browser Automation | Handle complex sites | +50% |
| Real-Time Delivery | Immediate insights | +60% |
By outsourcing scraping operations, businesses can focus on analyzing data rather than managing infrastructure. This approach ensures consistent and high-quality data output.
Enabling Enterprise-Grade Data Operations
For large organizations, Enterprise Web Crawling solutions provide the scalability and reliability needed for advanced data operations. These systems integrate APIs and browser-based methods into a unified platform.
Between 2020 and 2026, enterprise crawling adoption has increased by 60%, driven by the need for high-performance data extraction. These solutions are designed to handle massive datasets while maintaining accuracy and efficiency.
| Capability | Business Impact | Adoption Growth |
|---|---|---|
| Scalability | Handle large datasets | +60% |
| Automation | Reduce manual effort | +50% |
| Integration | Unified workflows | +55% |
Enterprise solutions provide the foundation for scalable and efficient scraping operations. By leveraging these technologies, businesses can achieve better performance and gain a competitive edge.
Why Choose Real Data API?
When it comes to delivering high-quality Web Scraping Datasets, performance comparison between API and browser-based scraping, Real Data API offers a comprehensive solution tailored for modern businesses. Its platform combines the speed of APIs with the flexibility of browser-based scraping, ensuring optimal performance across use cases.
Real Data API provides advanced infrastructure, automation, and real-time data delivery, enabling businesses to extract and process data efficiently. Its solutions are designed to handle high-volume operations while maintaining accuracy and reliability.
With a focus on innovation and scalability, Real Data API empowers organizations to transform their data strategies and achieve better outcomes.
Conclusion
Understanding the performance comparison between API and browser-based scraping is essential for selecting the right approach to data extraction. APIs offer speed and scalability, while browser-based methods provide flexibility for complex scenarios.
By combining these approaches and leveraging automation, businesses can achieve optimal performance and efficiency. As data demands continue to grow, choosing the right strategy will play a crucial role in maintaining a competitive advantage.
Ready to optimize your scraping strategy? Partner with Real Data API today and unlock faster, smarter, and more scalable data extraction solutions.
Latest posts

Why Brands Use Hyperlocal Retail Intelligence With Location Data Scraping For Hyperlocal Market Insights?

How To Scrape Product Availability Data For Modern Trade Brands For Better Stock Monitoring And Retail Execution?

How Businesses Can Reduce Lost Sales via Stock-Out Risk Detection Using Retail Data Scraping?

How Competitor Assortment Intelligence for Retailers Reduces Lost Sales Through Better Product Mix Decisions?
Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.







Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7


Disclaimer : RealData API functions solely as an independent data infrastructure and technology solutions provider. We build customized automation workflows designed to collect publicly accessible web data based exclusively on client instructions. RealData API neither owns proprietary datasets nor engages in the sale or redistribution of extracted information. Our operations are limited strictly to lawful public web data processing and never involve unauthorized access to restricted systems or private networks. Any company names, trademarks, logos, or brand references displayed on this website are used purely for demonstrative and illustrative purposes to showcase our technical capabilities and do not imply endorsement, partnership, or affiliation. Use of our platform and services remains subject to our Terms of Service.